Window and windowing functions using DataFrame API in Spark
Navneet Singh G.
Azure Databricks ? Data Engineer ? PySpark ? SQL ? IaC ? Terraform ? Cloud Automation ? Agile Methodology ? AWS Cloud
In this article we will clear the below concepts:
Such as:
We will be using DataFrame spark API to demonstrate this.
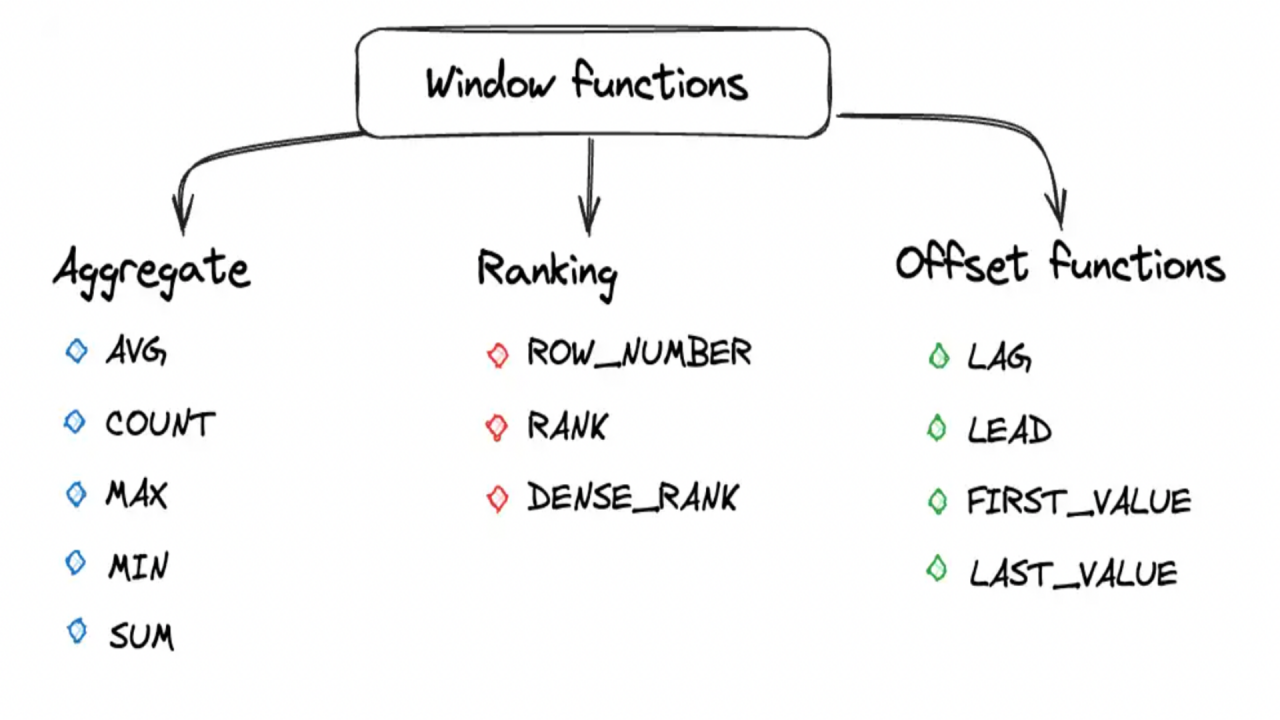
What is Window class?
The Window class in PySpark is used to define window specifications for window functions.
Specifications such as:
To demonstrate this consider you a DataFrame orders_df with columns:
country | weeknum | numinvoices | totalquantity | invoicevalue
Window class Usage:
%python
from pyspark.sql import Window
myWindow = Window.partitionBy("country") \
.orderBy("weeknum") \
.rowsBetween(Window.unboundedPreceding, Window.currentRow)
Frame boundary and available options:
Frame boundary define the subsets of rows within the partition to which window function is applied. We have the following options:
We have explained the window class. At this stage we are good to apply the window functions.
What is a Window Function ?
Window functions in Apache Spark operate on a group of rows (referred to as a window) and calculate a return value for each row based on the group of rows.
Common Window Functions
rank() - skips ranks in case of a tie. Example usage - Entrance Exam for a university.
dense_rank() - doesn't skip a rank. Example usage - To declare winners in an olympic.
领英推荐
row_number() - assigns a number to each row within a partition.
NOTE: Apart from the standard functions you can also apply other aggregate functions such as sum(), avg() on a window, based on the use case.
Usage of rank(), dense_rank() and row_number():
%python
from pyspark.sql import Window
myWindow = Window.partitionBy("country") \
.orderBy(desc("invoicevalue"))
from pyspark.sql.functions import row_number, rank, dense_rank, lag, lead, sum
// (from pyspark.sql.functions import *)
results_df = orders_df.withColumn("rank", rank().over(myWindow))
results_df.show()
// Similarly usage for dense_rank
results_df = orders_df.withColumn("dense rank", dense_rank().over(myWindow))
results_df.show()
// Similarly usage for row_number
results_df = orders_df.withColumn("row number", row_number().over(myWindow))
results_df.show()
We have 2 more important window functions: lead and lag.
Lead() - compares with the next row
Lag() - compares with the previous row
LAG() Usage:
%python
from pyspark.sql import Window
myWindow = Window.partitionBy("country") \
.orderBy("weeknum")
from pyspark.sql.functions import lag, lead
results_df = orders_df.withColumn("previous_week", lag("invoicevalue").over(myWindow))
final_df = results_df.withColumn("invoice_diff" , expr("invoicevalue - previous_week"))
Hope you understood what is a window and how to use a window function over a window.
NOTE - This topic is very important in case you are planning to appear for a data engineering interview. So, understand it well.
All the best. : )