Unveiling Customer Churn Insights: Leveraging Data for Retention Strategies
SUSAN ADONGO,PhD
Biodiversity Conservation | Blue Economy Strategist | Project Management | Corporate Trainer | Community Development | Physical Planner | Disaster Risk Reduction | Climate, & Sustainability Enthusiast
In the competitive landscape of today's business world, customer retention stands as a cornerstone for sustainable growth and profitability. Recently, I embarked on a data-driven journey to develop a classification model aimed at predicting customer churn—a pivotal step towards enhancing retention efforts and driving business success. Here’s a detailed look at the steps taken in this project and the key insights gained.
Harnessing the power of machine learning and analytics, this project underscores the importance of data-driven decision-making in customer retention strategies. By predicting churn accurately, businesses can proactively tailor interventions, optimize resource allocation, and ultimately foster long-term customer loyalty.
?Project Environment Setup
To begin, I established a dedicated repository for version control, ensuring organized management of code and project assets. A virtual environment was set up to manage dependencies and maintain reproducibility. Git was used for version control, enabling efficient collaboration and tracking of changes.
1. Business Understanding
· Problem Statement:?Every company aims to reduce customer churn to sustain profitability and growth.
· Goal and Objectives:?The primary objective was to develop a robust classification model to predict customer churn and identify factors influencing it.
· Stakeholders:?The key stakeholders included business leaders, marketing teams, and customer service managers who are invested in improving retention rates.
· Key Metrics and Success Criteria:?The success of the model was gauged using metrics such as accuracy, precision, recall, and F1-score.
· Hypothesis:
o Null Hypothesis (Ho): Customers with longer tenure are more likely to churn compared to new customers.
o Alternate Hypothesis (Ha): Customers with longer tenure are less likely to churn compared to new customers.
o Null Hypothesis (Ho): Customers with higher monthly charges are more likely to churn due to cost considerations.
o Alternate Hypothesis (Ha): Customers with higher monthly charges are less likely to churn due to cost considerations.
· Analytical Questions:?The project explored customer demographics, service subscriptions, and contract terms to understand churn dynamics.
2. Data Understanding
Importation and Loading Dataset:?The dataset was divided into three parts:
i. First Dataset:?Stored in a remote SQL Server database.
ii. Second Dataset:?Hosted on a GitHub repository.
iii. Testing Dataset:?Available on OneDrive in an Excel file.
?
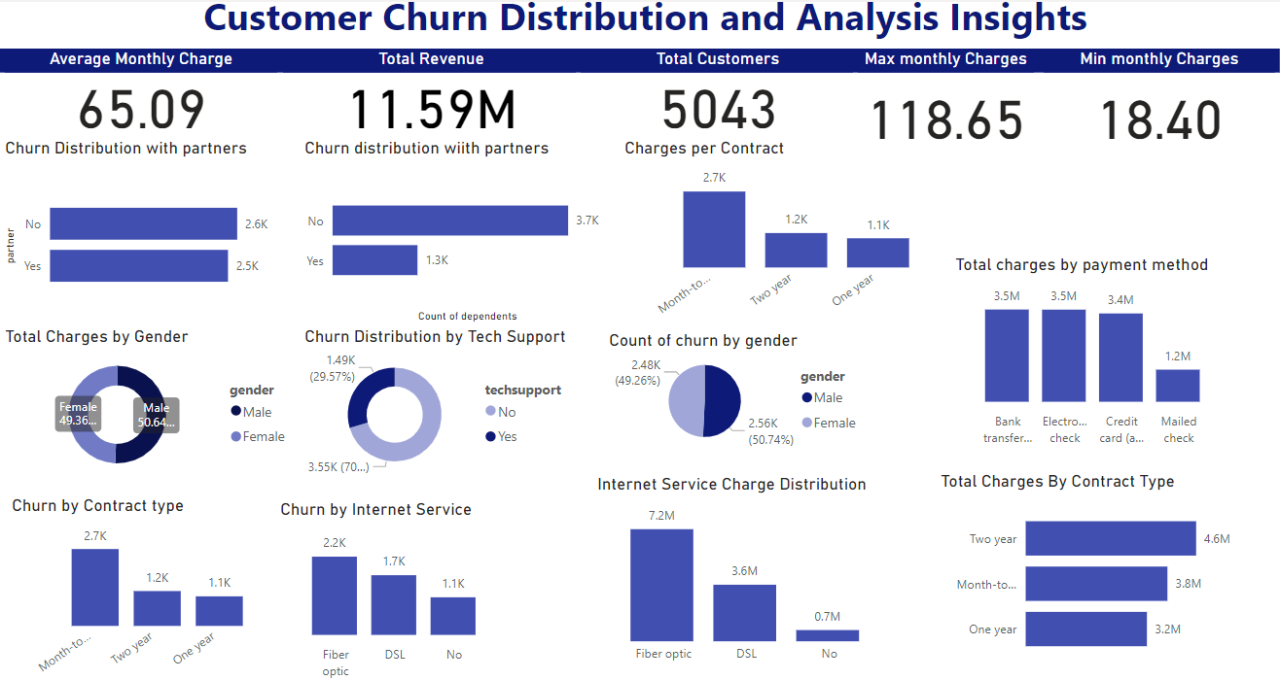
Testing Dataset through Exploratory Data Analysis (EDA):
· Data Quality Assessment:?I assessed data quality by checking for null values, duplicates, and overall data completeness.
· Univariate Analysis: I then ?Analyzed individual features to understand their distributions.
· Bi-variate and Multi-variate Analysis:?I Explored relationships between features and their impact on churn.
3. Data Preparation
Data Splitting:
· I Split the dataset into features (X) and target (y).
· I Further divided the data into training and evaluation sets.
Feature Engineering:
· I then Created new features, handled missing data, and performed encoding, standardization, and normalization.
领英推荐
Pipeline Creation:
· Separated input features into numeric and categorical for different pipelines.
· Handled missing values using imputation techniques.
· Scaled or normalized numeric features.
· Encoded categorical features.
· Applied transformations for skewed data.
· Balanced the dataset based on observed imbalances.
4. Modeling
Model Training:
· Developed and trained various models including distance-based models, gradient descent models, tree-based models, and neural networks.
5. Evaluation
Model Evaluation:
· Used ROC curves, AUC scores, precision-recall curves, and confusion matrices for comprehensive model assessment.
· Evaluated feature importance and selection.
· Performed hyperparameter tuning using GridSearchCV and RandomizedSearchCV.
· Compared models and selected the best-performing one.
Business Impact Assessment:?Documented how the chosen model affects business decisions and strategies.
Model Persistence:?Ensured the model is saved and can be reloaded for future use.
6. Deployment
Deployment Strategy:?Although not applicable in this project, a deployment strategy would typically include integrating the model into existing systems.
Model Monitoring and Maintenance:?Future steps would involve continuous monitoring and maintenance of the model to ensure its effectiveness over time.
Insights and Business Impact
Through this project, several key insights emerged:
· Contract Term:?Longer contracts correlated with reduced churn rates, suggesting that stability fosters loyalty.
· Service Bundling:?Customers with tech support services showed lower churn propensity, highlighting the value of comprehensive service offerings.
· Monthly Charges:?Contrary to initial hypotheses, higher charges did not consistently correlate with increased churn, indicating other factors at play in customer decisions.
Next Steps
Looking ahead, I am excited to delve deeper into predictive analytics and explore real-time deployment strategies for continuous improvement in churn prediction models. Let's continue shaping the future of customer retention through data!
#DataScience #CustomerRetention #ChurnAnalysis #MachineLearning
Governance and Leadership, WASH Expert, Environmental sustainability and climate action experts (ESCA), Blue economy specialist/ Project Management professional, EIA/EA expert.
8 个月I agree!