Unleashing the Power of RAG: My Journey to Transforming Industrial Automation ??
Hey #AI enthusiasts! Calling all data wizards and automation aficionados! I'm Zak, a passionate developer on a quest to explore cutting-edge tech. Recently, I embarked on a thrilling journey to unravel the potential of Retrieval-Augmented Generation (RAG) in revolutionizing industrial automation.
What's the magic behind RAG? ??
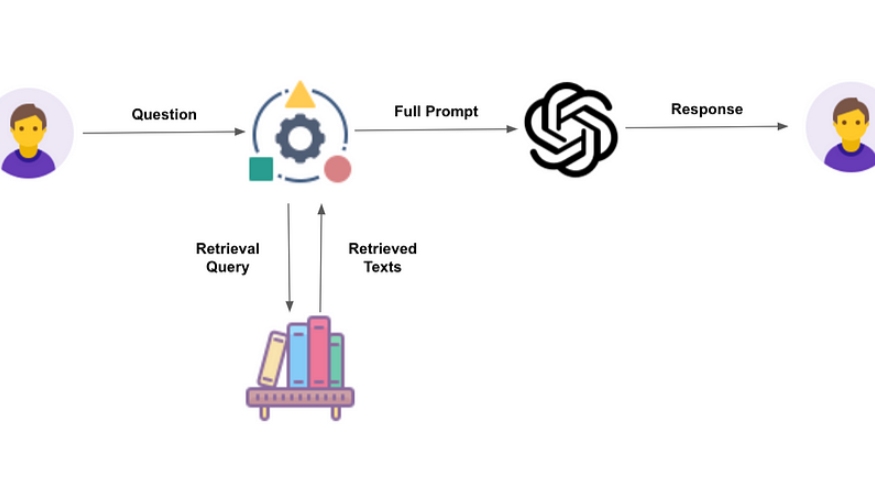
Retrieval-Augmented Generation (RAG) is a powerful AI technique that leverages the combined strengths of information retrieval and natural language generation to produce more accurate and informative responses. By combining these two AI elements, RAG can provide more comprehensive and relevant answers to complex queries.
How does RAG work?
- Input Query: A user poses a question or request.
- Information Retrieval: The system searches through a vast knowledge base to find relevant documents, articles, or data that are related to the query. This retrieval process can be based on keywords, semantic similarity, or other techniques.
- Response Generation: A language model, such as GPT-4, is used to generate a coherent and informative response based on the retrieved information. The model considers the context of the query and the relevant information to produce a relevant and accurate answer.
Why is RAG a game-changer for Industrial Automation? ??
?Enhanced Accuracy: No more "hallucinations"! RAG relies on real data to avoid misleading information.
? Industry-Specific Expertise: Tailor the knowledge base to your industry for highly specialized systems.
? Dynamic Knowledge Updates: Keep your system up to date without retraining the model, ensuring responses reflect the latest information.
Unlocking RAG's Potential: Best Practices & Techniques
Retrieval-Augmented Generation (RAG) is a powerful tool that can be used to improve the accuracy and relevance of AI-generated responses. To effectively implement RAG, consider the following best practices and techniques:
1. Knowledge Base Curation:
- Comprehensive and Well-Organized: Ensure your knowledge base is comprehensive and well-organized to facilitate efficient retrieval of relevant information.
- Industry-Specific: Tailor your knowledge base to the specific needs of your industry or application. For example, in industrial automation, include technical manuals, maintenance logs, and sensor data records.
2. Efficient retrieval:
- Retrieval Techniques: Explore various retrieval techniques, such as TF-IDF (Term Frequency-Inverse Document Frequency) and dense retrieval with BERT, to optimize the system's ability to find the most relevant documents.
3. Contextual Generation:
- Sufficient Context: Provide the generative model with enough context from the retrieved documents to ensure accurate and relevant responses. This can involve incorporating key phrases, summaries, or entire sections of the retrieved information.
4. Feedback Loop:
- Continuous Improvement: Implement a feedback mechanism to gather user feedback and refine both the retriever and the generator over time. User feedback is invaluable for identifying areas for improvement and ensuring the system meets user needs.
RAG in Action: Real-World Scenarios
Let me share a couple of scenarios where RAG really shines in industrial automation.
Use Case 1: Predictive Maintenance
Problem: Maintenance engineers need to know when a piece of equipment might fail to prevent unexpected downtime.
Solution:
- Query: "When should I schedule maintenance for the compressor?"
- Retrieval: The system fetches historical maintenance records and sensor data related to compressors.
- Generation: The model suggests a maintenance schedule, supported by data on past failures and sensor readings.
Use Case 2: Retrieving Call History Data
Problem: Users want to quickly check their recent call history and retrieve specific information (e.g., the last 5 contacts they spoke with).
Solution:
1. Query: The user asks, “Tell me the last 5 contacts in my recent call history.â€
2. Retrieval: The system retrieves the relevant call history data from a stored vector database (using FAISS), where contact names, phone numbers, and timestamps are indexed for quick access.
3. Generation: Using the retrieved data, the system generates a coherent response that lists the last 5 contacts, including their names, phone numbers, and call times, in an easy-to-read format. For example:
? Name: Alice, Phone: 123-456-7890, Time: 9/28/2023, 09:00 AM
? Name: Bob, Phone: 987-654-3210, Time: 9/27/2023, 04:30 PM
? Name: Charlie, Phone: 555-555-5555, Time: 9/27/2023, 03:15 PM
? Name: David, Phone: 444-444-4444, Time: 9/26/2023, 11:00 AM
? Name: Eve, Phone: 333-333-3333, Time: 9/25/2023, 02:45 PM
This use case explains the problem, how the retrieval happens using the FAISS vector index, and how the OpenAI model generates a response using the retrieved data. It keeps the focus on a simple, real-world scenario: retrieving recent call history based on user queries.
Exploring Vector Storage: A Powerful Tool for RAG ??
One of the most exciting aspects of my RAG journey was experimenting with vector storage. This innovative technique involves storing data as vectors (arrays of numbers) that represent the semantic meaning of information. This approach offers several significant advantages:
1. High-Dimensional Search: Unlike traditional keyword searches, vector storage captures the context and meaning of queries, enabling more accurate and relevant document retrieval.
2. Scalability: Vector storage can efficiently handle large datasets, making it ideal for real-time applications where quick and accurate responses are essential.
3. Contextual Matching: By comparing the semantic meaning of queries and documents, vector storage allows for more precise matching, ensuring that the most relevant information is retrieved.
Building a RAG PoC with Vector Storage: A Step-by-Step Guide
To demonstrate the power of vector storage in RAG, we'll create a simple system that:
- Stores call history data (names, phone numbers, and call times).
- Allows users to ask questions like "Tell me the last 5 contacts in my recent call history."
- Retrieves the correct call history using vector storage.
- Utilizes OpenAI's GPT model to generate a human-readable response based on the retrieved data.
P.S. Check out the post for the complete code!
Step-by-Step Guide
???????? Step 1: Set Up Your Project
???????? First, we need to create a Node.js project where we’ll write our code. Node.js is a platform that helps us run JavaScript code outside of a web browser.
领英推è
1. Create a folder for your project and initialize Node.js. Run these commands:
mkdir rag-poc
cd rag-poc
npm init -y
This creates a new directory and initializes a new Node.js project.
2.Install necessary libraries:
- express: To set up a simple API.
- openai: To interact with OpenAI’s language model.
?Run this command to install them:
npm install express openai
Step 2: Simulate Call History Data
We need some data to work with. In this PoC, we’ll use a simple call history stored in a JSON (JavaScript Object Notation) file.
- Create a file called callHistory.json in your project directory and add the following data to it:
[
{ "name": "Alice", "phone": "123-456-7890", "time": "2023-09-28T09:00:00Z" },
{ "name": "Bob", "phone": "987-654-3210", "time": "2023-09-27T16:30:00Z" },
{ "name": "Charlie", "phone": "555-555-5555", "time": "2023-09-27T15:15:00Z" },
{ "name": "David", "phone": "444-444-4444", "time": "2023-09-26T11:00:00Z" },
{ "name": "Eve", "phone": "333-333-3333", "time": "2023-09-25T14:45:00Z" },
{ "name": "Frank", "phone": "222-222-2222", "time": "2023-09-24T12:30:00Z" }
]
This data represents call history with the name, phone number, and call time of each contact.
Step 3: Set Up Vector Storage for Retrieving Data
Now, we need to create a way to search or retrieve the relevant call history based on what the user asks. For this, we’ll use FAISS (Facebook AI Similarity Search), a tool to store and quickly search through data by creating vectors (mathematical representations of our data).
We’ll use a Python script for this part since FAISS works best in Python. Don’t worry; we’ll run this Python script from our Node.js code later.
- Install the Python dependencies: Install the Python dependencies:
Run these commands to install faiss-cpu for vector storage and sentence-transformers to convert text into vectors.
pip install faiss-cpu sentence-transformers
2. Create create_index.py: This script will convert your call history into vectors and store them in a FAISS index, which allows you to search through them later.
import faiss
import json
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
def create_index(docs):
texts = [f"{doc['name']} {doc['phone']} {doc['time']}" for doc in docs]
embeddings = model.encode(texts)
index = faiss.IndexFlatL2(embeddings.shape[1])
index.add(embeddings)
faiss.write_index(index, 'call_index.faiss')
print("Index created successfully.")
if __name__ == "__main__":
with open('callHistory.json', 'r') as f:
docs = json.load(f)
create_index(docs)
?3. Run the script to create the FAISS index from the call history data:
python create_index.py
After running this, FAISS will create a vector index (call_index.faiss), which allows us to quickly retrieve relevant call history later.
?Step 4: Query the Call History Data
Now that we have stored our call history data as vectors, we need a way to query the data to retrieve relevant contacts.
- ?Create query_index.py: This script will search through the vector index and find the most relevant contacts based on the user's question
import faiss
import json
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
def query_index(query, top_k=5):
index = faiss.read_index('call_index.faiss')
query_embedding = model.encode([query])
distances, indices = index.search(query_embedding, top_k)
return indices.tolist()
if name == "__main__":
import sys
query = sys.argv[1]
top_k = int(sys.argv[2]) if len(sys.argv) > 2 else 5
with open('callHistory.json', 'r') as f:
docs = json.load(f)
indices = query_index(query, top_k)
results = [docs[i] for i in indices[0]]
print(json.dumps(results, indent=2))
This script will search for the top 5 relevant contacts based on the user’s query and return them.
Step 5: Set Up the Node.js API
Now, let's bring everything together by creating a simple Node.js API that:
??Takes a user's question as input.
??Queries the FAISS index to retrieve relevant contacts.
?Sends the relevant contacts to OpenAI to generate a natural language response.
?1. Create index.js:
?import express from 'express';
import { exec } from 'child_process';
import OpenAI from 'openai';
const app = express();
app.use(express.json());
const openai = new OpenAI({ apiKey: process.env.OPENAI_API_KEY });
// Function to run the Python query script
function queryIndex(query, topK = 5) {
return new Promise((resolve, reject) => {
exec(`python query_index.py "${query}" ${topK}`, (error, stdout, stderr) => {
if (error) {
console.error(`Error querying index: ${stderr}`);
return reject(error);
}
resolve(JSON.parse(stdout));
});
});
}
// POST endpoint to ask a question
app.post('/ask', async (req, res) => {
const { question } = req.body;
if (!question) {
return res.status(400).json({ error: 'Question is required' });
}
try {
// Query the vector index for relevant contacts
const relevantContacts = await queryIndex(question);
// Format the call history context
const callHistoryContext = relevantContacts.map(contact =>
Name: ${contact.name}, Phone: ${contact.phone}, Time: ${new Date(contact.time).toLocaleString()}
).join('\n');
// Generate a response using OpenAI
const completion = await openai.chat.completions.create({
model: "gpt-4",
messages: [
{ role: "system", content: "You are a helpful assistant. You have access to the user's recent call history." },
{ role: "assistant", content: Here is the relevant call history:\n${callHistoryContext} },
{ role: "user", content: question }
],
});
res.json({ answer: completion.choices[0].message.content.trim() });
} catch (error) {
console.error('Error processing request:', error.message);
res.status(500).json({ error: 'Failed to get response from OpenAI' });
}
});
const PORT = 3000;
app.listen(PORT, () => {
console.log(`Server is running on https://localhost:${PORT}`);
});
2.Start the server:
node index.js
Step 6: Test the RAG System
With everything set up, you can now test the entire RAG system.
1. Send a request to the /ask endpoint to retrieve and augment the call history data.
Use curl:?
curl -X POST https://localhost:3000/ask -H "Content-Type: application/json" -d '{"question": "Tell me the last 5 contacts in my recent call history."}'
2. Expected Response: You should receive a response like:
{
"answer": "Here are the last 5 contacts in your recent call history:\n1. Name: Alice, Phone: 123-456-7890, Time: 9/28/2023, 09:00 AM\n2. Name: Bob, Phone: 987-654-3210, Time: 9/27/2023, 04:30 PM\n3. Name: Charlie, Phone: 555-555-5555, Time: 9/27/2023, 03:15 PM\n4. Name: David, Phone: 444-444-4444, Time: 9/26/2023, 11:00 AM\n5. Name: Eve, Phone: 333-333-3333, Time: 9/25/2023, 02:45 PM"
?The Future of RAG is Bright!?
This exploration has only scratched the surface of what RAG can achieve. I'm excited to see how it empowers various fields, including industrial automation. Retrieval-augmented generation (RAG) is a powerful AI technique that can revolutionize various industries. RAG offers improved accuracy, enhanced relevance, and increased efficiency by combining information retrieval and natural language generation. Businesses can leverage RAG for customer service, search engines, and content creation. As AI continues to evolve, RAG's potential will only grow, providing opportunities for innovation and growth.
Let's discuss it! Share your thoughts on how RAG can be leveraged in your industry.
Don't miss out on the opportunity to revolutionize your industry with RAG.
?
Digitization R&D Head@Siemens Edge-Cloud, GenAI & Startup Focus | Speaker | Ex-SAP Cloud | B.E MBA MAPC | Psychologist | Yoga Teacher
5 个月Very informative