?? Understanding SQL Server Join Algorithms: A Must-Know for ETL Developers!
S Nayyar M
Senior BI & Data Automation Leader | Scalable Growth with AI-Driven Solutions | Delivered $100M+ Impact Across Asia, Middle East, Oceania, & North America | Achieved 60% efficiency gains.
When optimizing SQL queries in your ETL workflows, the choice of join algorithm can significantly impact performance. As SQL Server automatically chooses the join algorithm based on the dataset and query, it's crucial to understand the underlying technology to make your queries more efficient. ??
Here's a quick overview of the key join algorithms SQL Server uses and when to leverage them:
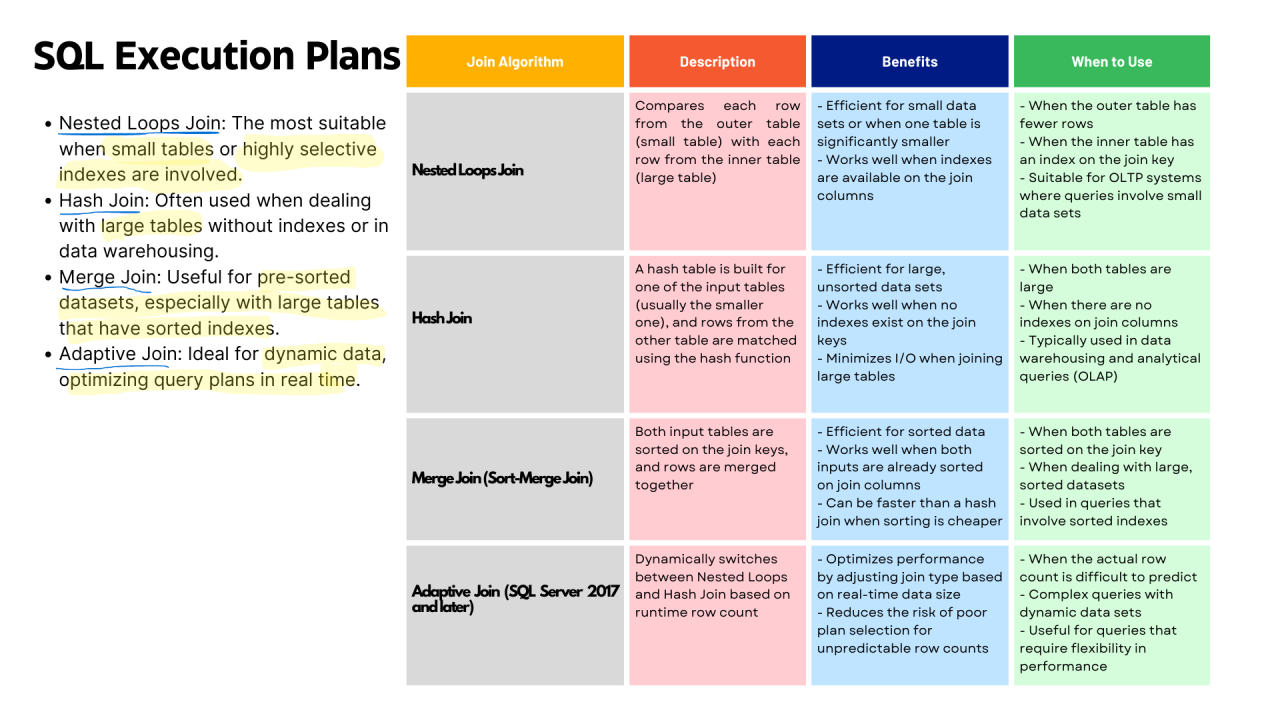
?? Nested Loops Join: Benefits Ideal for small datasets or indexed joins, Best for small outer tables or indexed inner tables
?? Hash Join: Benefits Great for large, unsorted datasets. Useful when joining large tables without indexes
?? Merge Join: Benefits Fast for sorted data Use when both tables are already sorted on the join key
? Adaptive Join: Benefits Dynamically adjusts join type based on row count. Perfect for unpredictable row counts or complex queries
?? Key Takeaways:
By understanding these algorithms, you can write more efficient queries and boost performance in your ETL processes. ??
Want to dive deeper? Feel free to reach out or comment below with your thoughts and experiences! Let's optimize our SQL queries together!
#SQLServer #ETL #DataEngineering #SQLPerformance #JoinAlgorithms #DataWarehouse #DataOptimization