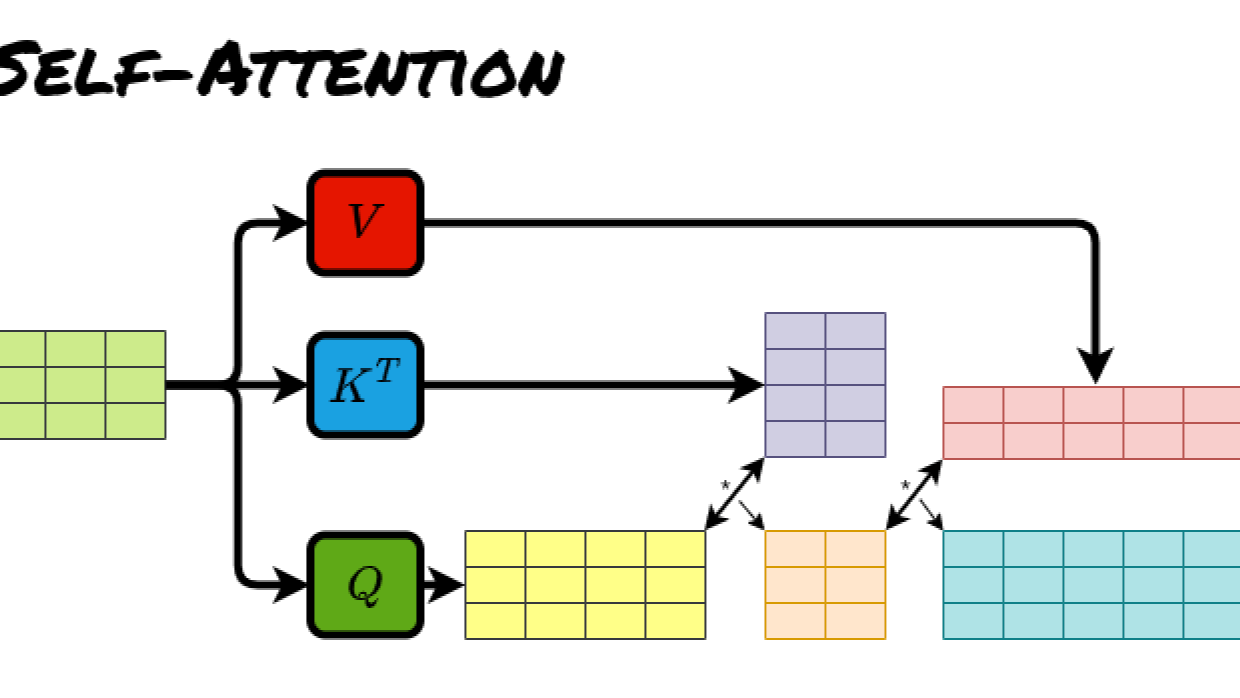
Understanding Self-Attention in Transformers
Siva Swetha G
Data Science & GenAI Intern @ Innomatics Research Labs| Statistics, Machine Learning , MySQL, Tableau, Deep Learning, NLP
Ever wondered how Transformer models like BERT and GPT understand relationships between words? The secret lies in self-attention—a mechanism that helps models evaluate how every word in a sentence relates to every other word.
Let’s dive in and explore it further
The Sentence
We will work with the sentence: "The cat chased the mouse."
Our goal is to compute self-attention using the formula:
Let’s calculate the attention for all the words step by step.
Step 1 : Covert Words into Embeddings
We assign the following embeddings to the words:
Step 2 : Compute Q, K & V Vectors
We use the following weight matrices:
Step 2.1 : For "The" [0.1,0.2,0.3] :
Step 2.2 : For "cat" [0.5,0.6,0.7] :
Step 2.3 : For "chased" [0.8,0.9,1.0] :
Step 2.4 : For "mouse" [1.1,1.2,1.3] :
Step 3 : Compute Attention Scores
The attention scores between two words is calculated as :
3.1: Compute Scores for "The":
This forms the first row of the score matrix.
3.2: Compute Scores for Remaining Words:
Repeat the process for "cat", "chased" and "mouse", calculating their scores against every other word.
The final score matrix is :
领英推荐
Step 4: Normalize the Scores using Softmax
Apply softmax to each row of the score matrix to convert raw scores into probabilities. This step ensures that the scores for each word sum to 1.
Formula for Softmax is :
Softmax for "The" :
Score : [0.150, 0.559, 0.902, 1.261]
Exponentiate each value:
Sum of exponentials : 1.162 + 1.749 + 2.465 +3.529 = 8.905
Normalize each value :
Normalized probabilities for "The": [0.130, 0.196, 0.277, 0.396]
Similarly, calculate for all the rows corresponding to "cat", "chased", "mouse". The final softmax-normalized score matrix is :
Step 5 : Weighted Sum of Values
The final step is to compute the weighted sum of the Value vectors for each word. The weights are the attention probabilities from the normalized score matrix.
For "The" :
Attention probabilities : [0.130, 0.196, 0.277, 0.396]
Value Vectors :
Weighted Sum :
Compute each term :
Sum them up :
This vector represents how "The" is understood, considering its relationship with "cat," "chased," and "mouse."
Perform similar weighted sums for the other words (cat, chased, mouse) using their attention probabilities and Value vectors.
Conclusion
The final contextualized embeddings encode how each word interacts with others in the sentence:
PLSQL developer/Facets Developer/Aspiring data scientist
1 个月Interesting