Understanding Machine Learning Algorithms: A Comprehensive Guide
Hemanth Chakravarthy Mudduluru
Team Lead - Eng’g Supervisor, Project Manager, Product Owner (AD & ADAS) Software | Product Management | Executive | R&D | MBA
In the rapidly evolving field of machine learning, selecting the right algorithm for your data can be a daunting task. Each algorithm has its unique strengths and weaknesses, making it suitable for specific types of problems. This article will explore ten widely used machine learning algorithms, examining their pros and cons to help you make informed decisions in your projects.
1. Linear Regression
Pros:
- Simple and interpretable
- Fast
Cons:
- Only works for linear relationships
Linear Regression is one of the simplest algorithms used for predictive analysis. Using a linear equation, it models the relationship between a dependent variable and one or more independent variables. While it is easy to understand and implement, it is limited to linear relationships, making it unsuitable for more complex data patterns.
2. Logistic Regression
Pros:
- Fast and interpretable
Cons:
- Assumes linear boundaries
Logistic Regression is used for binary classification problems. It estimates the probability that a given input belongs to a particular class. Despite its simplicity and speed, it assumes linear decision boundaries, which may not be suitable for all datasets.
3. Decision Trees
Pros:
- Easy to interpret
- No need for scaling
Cons:
- Prone to overfitting
Decision Trees are versatile algorithms that can handle both classification and regression tasks. They split the data into subsets based on feature values, creating a tree-like model. However, they are prone to overfitting, especially with complex datasets.
4. Random Forests
Pros:
- Reduces overfitting
- Good accuracy
Cons:
- Slower on large datasets
Random Forests are an ensemble learning method that combines multiple decision trees to improve accuracy and reduce overfitting. While they offer better performance than individual decision trees, they can be slower to train and predict on large datasets.
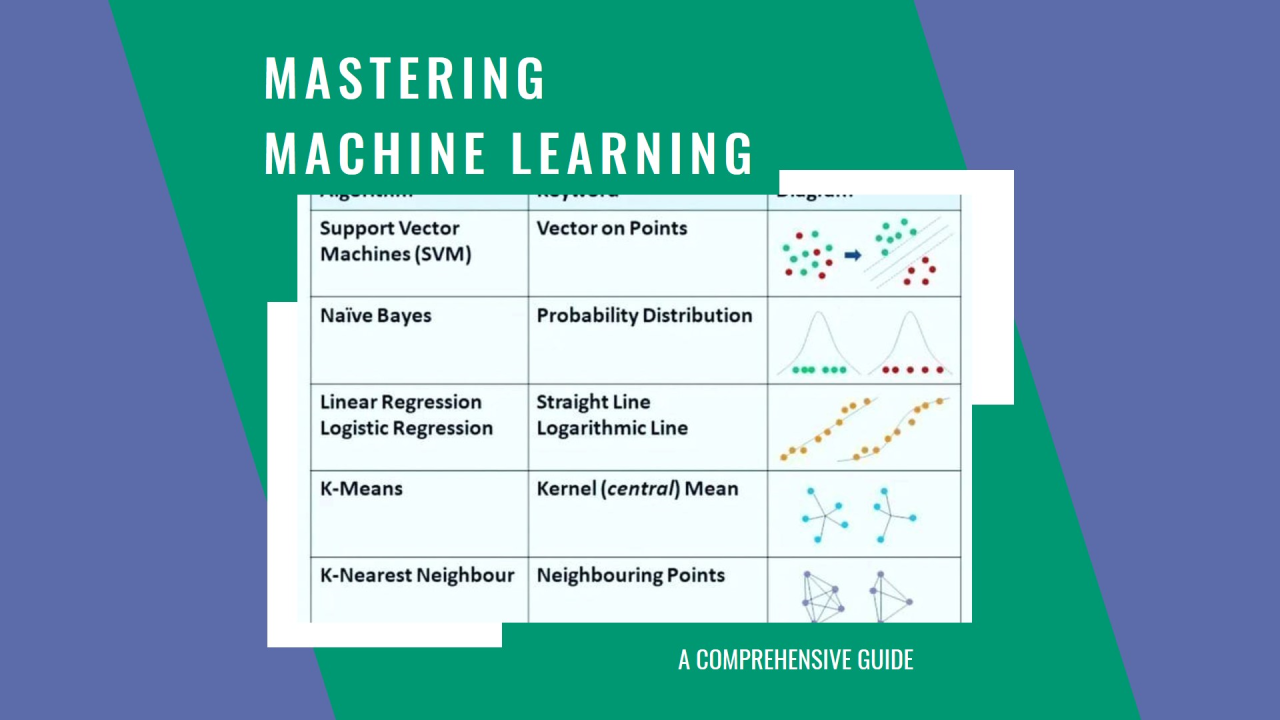
5. Support Vector Machines (SVM)
Pros:
- Effective in high-dimensional spaces
Cons:
- Computationally expensive
SVMs are powerful algorithms for classification tasks, especially when dealing with high-dimensional data. They work by finding the hyperplane that best separates the classes. However, they can be computationally intensive, making them less suitable for very large datasets.
6. K-Nearest Neighbors (KNN)
Pros:
- No training required
Cons:
- Slow
- Sensitive to noisy data
KNN is a simple, instance-based learning algorithm that classifies data points based on their proximity to other points. It is easy to implement and requires no training phase. However, it can be slow and sensitive to noisy data, especially with large datasets.
7. Naive Bayes
Pros:
- Fast and efficient
- Works well with text
Cons:
- Assumes independent features
Naive Bayes is a probabilistic classifier based on Bayes' theorem. It is particularly effective for text classification tasks. Despite its simplicity and efficiency, it assumes that features are independent, which may not always be the case.
8. K-Means Clustering
Pros:
- Simple to implement
- Good for pattern finding
Cons:
- Sensitive to initialization
K-Means Clustering is an unsupervised learning algorithm used for partitioning data into clusters. It is simple to implement and useful for discovering patterns in data. However, it is sensitive to the initial placement of centroids, which can affect the final clusters.
9. Neural Networks
Pros:
- Highly accurate
- Works on complex data
Cons:
- Requires lots of data and computing power
Neural Networks are inspired by the human brain and are capable of modeling complex patterns in data. They are highly accurate and can handle a wide range of tasks. However, they require large amounts of data and significant computational resources.
10. Gradient Boosting Machines (GBM)
Pros:
- High accuracy
- Handles both types of problems
Cons:
- Slow
- Prone to overfitting
GBM is an ensemble learning method that builds models sequentially, each correcting the errors of its predecessor. It is highly accurate and can handle both classification and regression tasks. However, it can be slow to train and prone to overfitting.
Understanding these algorithms' strengths and weaknesses can significantly impact the success of your machine-learning projects. By choosing the right algorithm, you can improve the accuracy and efficiency of your models, leading to better outcomes.
??Founder of AIBoost Marketing, Digital Marketing Strategist | Elevating Brands with Data-Driven SEO and Engaging Content??
1 周Wow, what a valuable resource! Understanding the strengths and weaknesses of each algorithm is key to successful data projects. Let's dive in together! ?? #DataScience #MachineLearning #TechInsights
Tech Resource Optimization Specialist | Enhancing Efficiency for Startups
2 周Clear and insightful breakdown of popular ML algorithms! Perfect guide for selecting the right tool based on project needs.
Engineering Manager - ADAS | AI/ML Innovation | Rapid Prototyping | Cloud
2 周Great advice
CameoUI Designer
2 周Send me connection please