Understanding llama.cpp — Computation Graph and Transformer Architecture
In the world of Large Language Models (LLMs), the Transformer architecture gets all the attention. But behind the scenes, frameworks like LLaMA rely on a sophisticated graph-based computation engine to handle memory, optimize execution, and achieve blazing-fast inference.
In Part 1: Understanding llama.cpp — Efficient Model Loading and Performance Optimization, we explored how LLaMA efficiently loads and optimizes large models. Now, in Part 2, we take a deep dive into how LLaMA builds, optimizes, and executes computation graphs.
What You'll Learn
If you’re aiming to understand LLaMA's inner workings or build your own LLM engine, this article is for you.
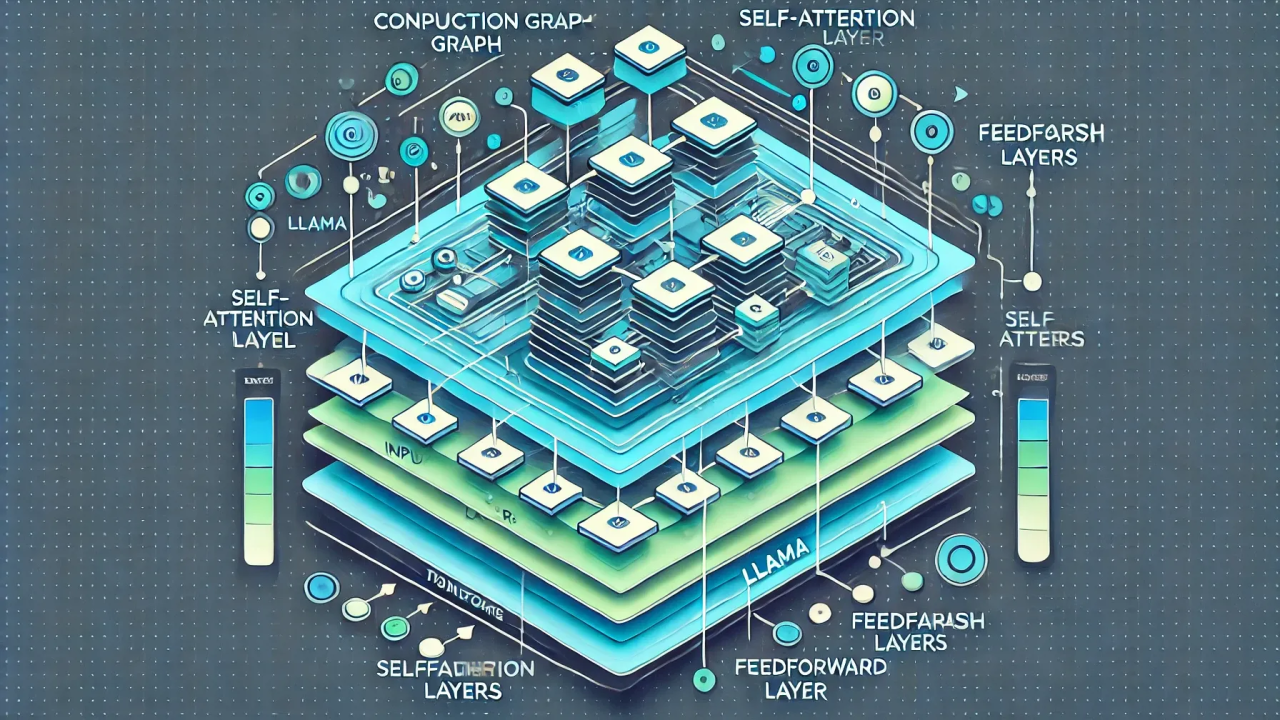
?? Understanding LLaMA's Transformer Architecture: Layers Unveiled
At its core, LLaMA follows the Transformer architecture, but with optimizations to reduce memory consumption and increase execution speed. Here’s a simplified view of the key components of the Transformer used in LLaMA:
LLaMA's Transformer layers are stacked N times (where N is the depth of the model). Each of these layers has several intermediate tensors that must be computed, stored, and reused. Directly computing these tensors at runtime would be inefficient, which is why graph-based computation is introduced.
?? Why LLaMA Uses Graph Computation Instead of Direct Calculation
In a traditional implementation, you compute tensor-by-tensor, step-by-step. For example:
This method works but requires memory to hold every intermediate result, and it prevents global optimizations.
In graph-based computation, you first define the entire graph of operations and tensors. Each node represents a tensor or an operation (like addition, multiplication, etc.), and edges represent the dependencies between them. Once the graph is defined, it is executed using an optimal order (using topological sorting).
Why Use Graph-Based Computation?
LLaMA leverages this by using the ggml library, which allows you to build the graph of computations using simple functions like ggml_add, ggml_mul, etc.
?? Anatomy of LLaMA's Computation Graph: Nodes, Edges, and Tensors
LLaMA relies on two key C++ data structures:
领英推荐
Data Structures (Simplified View)
??? Building the Graph: How ggml_build_forward_expand Assembles the Transformer
Now, let's walk through how LLaMA builds its computation graph for a single Transformer block.
Step 1: Inputs and Embeddings
The first step is embedding the input tokens. These embeddings are stored as leaf nodes in the graph since they’re not recomputed.
Step 2: Self-Attention Graph
For each input, we compute the queries, keys, and values. Each step (like Q = Embedding * Wq) becomes a node in the graph.
Each function like ggml_matmul, ggml_transpose, etc., does not compute anything immediately. It simply adds a node to the graph.
Step 3: Feedforward Network
Output from attention is fed to the feedforward network. Similar to attention, the intermediate calculations are stored as graph nodes.
?? Topological Sorting: Decoding the Execution Order of the Graph
Once the graph is built, we need to determine the order of execution. This is achieved using a depth-first search (DFS) to topologically sort the nodes.
How LLaMA Sorts the Graph
?? Running the Graph: How Inference is Performed Step-by-Step
Finally, we execute the graph node by node using the topological order.
How LLaMA Executes the Graph
?? Key Takeaways: Why Graph-Based Computation Makes LLaMA So Efficient