Understanding the K-Nearest Neighbors (KNN) Algorithm
In the ever-evolving field of machine learning, the K-Nearest Neighbors (KNN) algorithm stands out as one of the most straightforward yet effective techniques for classification and regression tasks. Whether you are a seasoned data scientist or a newcomer to the world of machine learning, understanding KNN is crucial due to its simplicity and broad applicability.
What is K-Nearest Neighbors (KNN)?
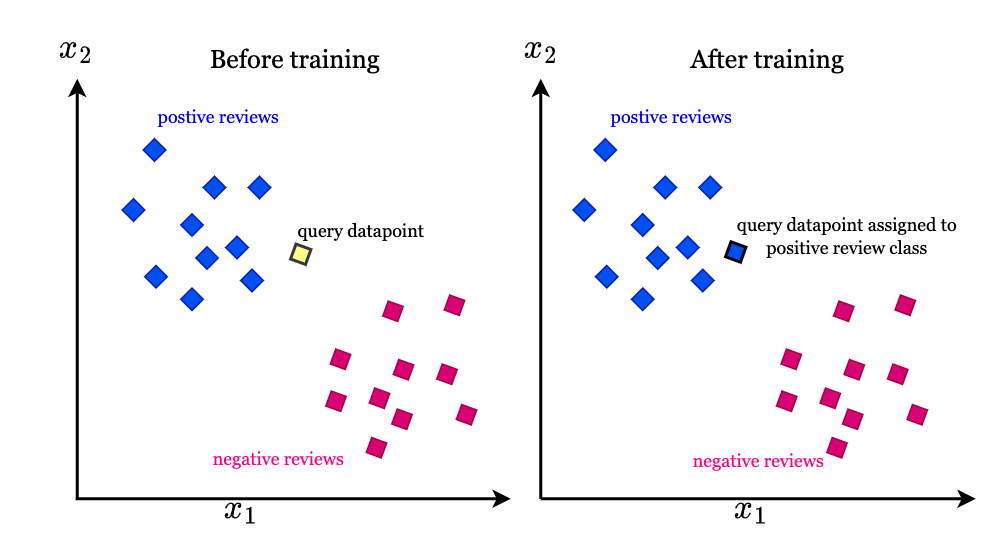
The K-Nearest Neighbors algorithm is a non-parametric, supervised learning classifier. Unlike many other machine learning models, KNN does not make any assumptions about the underlying data distribution. Instead, it relies on the proximity of data points to make predictions, making it highly versatile and easy to implement.
How Does KNN Work?
At its core, KNN operates on the principle of similarity. Here’s a step-by-step breakdown of how the algorithm functions:
Advantages of KNN
领英推荐
Disadvantages of KNN
Applications of KNN
KNN is widely used across various domains due to its simplicity and effectiveness. Some common applications include:
Tips for Implementing KNN
Conclusion
The K-Nearest Neighbors algorithm, with its intuitive approach and robust applicability, remains a foundational technique in the toolkit of any machine learning practitioner. By leveraging the power of proximity, KNN provides a simple yet powerful way to make predictions and uncover patterns within data.
Whether you are solving classification problems or tackling regression tasks, understanding and implementing KNN can be a valuable asset in your journey through the landscape of machine learning.