Understanding & Building LLM Applications!
Pavan Belagatti
GenAI Evangelist (62K+)| Developer Advocate | Tech Content Creator | AI/ML Influencer | 28k Newsletter Subscribers | Supporting AI Innovations
Large Language Models (LLMs) represent a significant advancement in the field of artificial intelligence, particularly in understanding and generating human-like text.?
LLMs are a specific type of deep learning model trained on massive datasets of text and code. These models possess extensive knowledge and understanding of language, allowing them to perform various tasks, including:
How do LLMs work?
LLMs typically utilize Transformer-based architectures we talked about before, relying on the concept of attention. This allows the model to focus on relevant parts of the input text when making predictions and generating outputs.
The training process involves feeding the LLM massive datasets of text and code. This data helps the model learn complex relationships between words and phrases, ultimately enabling it to understand and manipulate language in sophisticated ways.
Generative AI models have become increasingly sophisticated and diverse, each with its unique capabilities and applications.
Some notable examples include:
Gemini (formerly Bard) is a Google AI chatbot that uses natural language processing to chat naturally and answer your questions. It can enhance Google searches and be integrated into various platforms, providing realistic language interactions.
Developed by OpenAI, ChatGPT is a variant of the GPT (Generative Pre-trained Transformer) model, specifically fine-tuned for conversational responses. It's designed to generate human-like text based on the input it receives, making it useful for a wide range of applications including customer service and content creation. ChatGPT can answer questions, simulate dialogues and even write creative content.
Also from OpenAI, DALL-E is a neural network-based image generation model. It's capable of creating images from textual descriptions, showcasing an impressive ability to understand and visualize concepts from a simple text prompt. For example, DALL-E can generate images of "a two-headed flamingo" or "a teddy bear playing a guitar," even though these scenes are unlikely to be found in the training data.
Midjourney is a generative AI tool that creates images from text descriptions, or prompts. It's a closed-source, self-funded tool that uses language and diffusion models to create lifelike images.
Stable Diffusion is a deep learning model that uses diffusion processes to create high-quality images from input images. It's a text-to-image model that can transform a text prompt into a high-resolution image.
Each of these models represents a different facet of generative AI, showcasing the versatility and potential of these technologies. From text to images, these models push the boundaries of what's possible with AI, enabling new forms of creativity and problem solving.
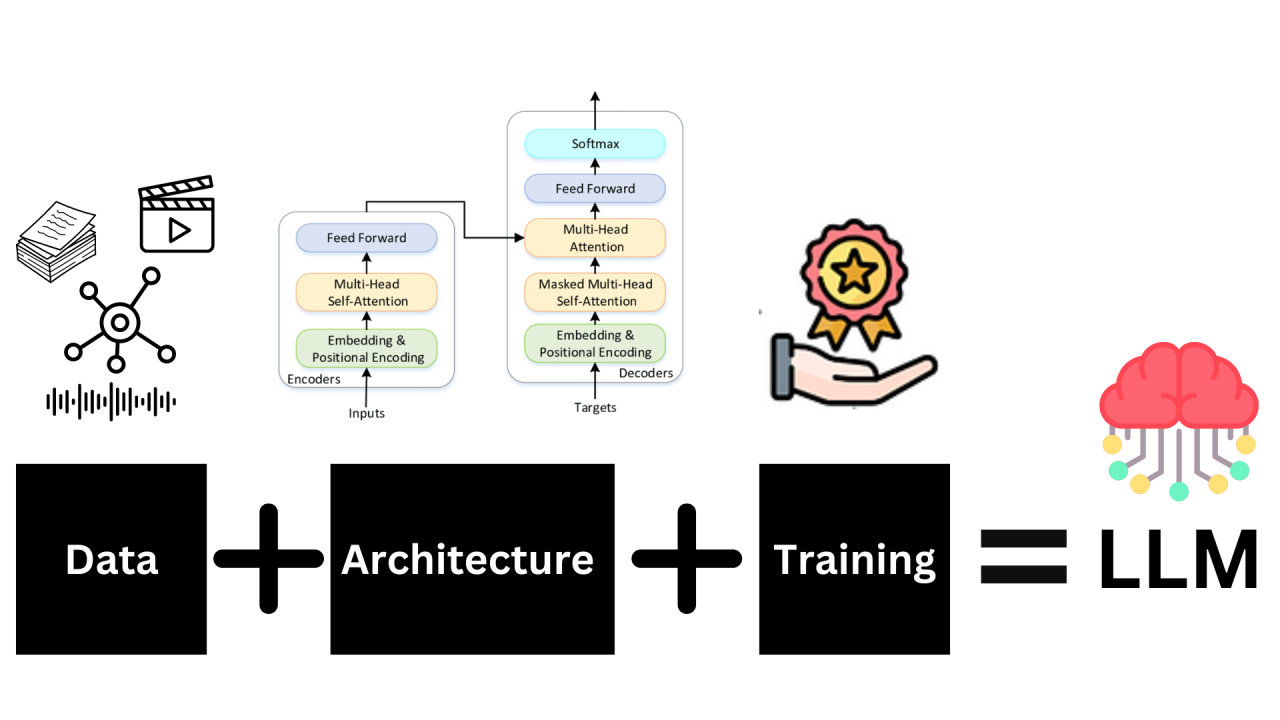
Components of an LLM
LLMs are built upon three foundational pillars: data, architecture and training.
Each of these components plays a crucial role in shaping the capabilities and performance of a Large Language Model. The harmonious integration of these elements allows the model to understand and generate human-like text, answering questions, writing stories, translating languages and much more.
How do LLMs learn???
It is very important to understand how these LLMs are trained, so let’s take a closer look at the training process:?
领英推荐
This cycle of encoding and decoding, informed by both the original training data and ongoing human feedback, enables the model to produce text that is contextually relevant and syntactically correct. Ultimately, this can be used in a variety of applications including conversational AI, content creation and more.
Building an LLM application
Here are the high-level steps you need to know to build an LLM application:?
1. Focus on a single problem first. The key? Find a problem that’s the right size: one that’s focused enough so you can quickly iterate and make progress, but also big enough so that the right solution will wow users.
2. Choose the right LLM. You’re saving costs by building an LLM app with a pre-trained model, but how do you pick the right one? Here are some factors to consider:
? Licensing. If you hope to eventually sell your LLM app, you’ll need to use a model that has an API licensed for commercial use. To get you started on your search, here’s a community-sourced list of open LLMs that are licensed for commercial use.
? Model size. The size of LLMs can range from seven to 175 billion parameters — and some, like Ada, are even as small as 350 million parameters. Most LLMs (at the time of writing) range in size from 7-13 billion parameters.
3. Customize the LLM. When you train an LLM, you’re building the scaffolding and neural networks to enable deep learning. When you customize a pre-trained LLM you’re adapting the LLM to specific tasks, like generating text around a specific topic or in a particular style.?
4. Set up the app architecture. The different components you’ll need to set up your LLM app. Can be broadly divided into three categories - User input , Input enrichment & prompt construction tools and efficient and responsible AI tooling.?
5. Conduct online evaluations of your app. These are considered “online” evaluations because they assess the LLM’s performance during user interaction.?
Here is a list of my favorite Dev tools to build AI/ML applications.
Of which SingleStore Notebook feature and Wing programming language are the most amazing ones. With Wing, You can build any AI/ML application with minimal code. Here is a technical overview image of this example of how to use OpenAI’s API with Wing.
Limitations of LLMs?
While LLMs offer impressive capabilities in language understanding and generation, they also have limitations that can hinder their effectiveness in real-world applications. These limitations include:
You can mitigate this hallucinated nature of LLMs using different techniques like Retrieval Augmented Generation (RAG), Prompt Engineering and Fine-Tuning.
Here is my complete guide on reducing LLM hallucinations.
Learn many Generative AI concepts in my e-book 'GenAI for Everyone'.
Looking forward to diving into your insights on #LLMs architecture and their workings! Your newsletter is always a great read
Co-Founder of Altrosyn and DIrector at CDTECH | Inventor | Manufacturer
4 个月Understanding LLMs architecture reminds me of the transition from early mainframes to distributed computingboth involved complex integration of components to achieve higher efficiency and capabilities. As LLMs evolve, their multi-layered attention mechanisms and transformer networks are becoming crucial in processing vast amounts of data effectively. Considering this progression, how do you foresee the optimization of LLMs' tokenization and embedding processes to handle increasingly diverse and unstructured data inputs? What innovations might drive the next leap in their architectural efficiency?