TimesFM: A Foundation Model Revolutionizing Time-Series Forecasting
Time-series data, like stock prices or weather patterns, is everywhere. Predicting the future of this data – forecasting – is crucial for many applications, from optimizing supply chains to predicting energy demands. Traditionally, specialized models are built for each forecasting task, demanding significant time and resources. But what if we could have a single, powerful model capable of accurate forecasting across diverse datasets, straight out-of-the-box?
Inspired by the success of large language models (LLMs) in natural language processing, researchers have introduced TimesFM: a decoder-only foundation model for time-series forecasting. This innovative model is trained on a massive corpus of both real-world and synthetic time-series data, enabling it to achieve remarkable zero-shot accuracy on unseen datasets, rivalling the performance of supervised models meticulously trained for specific tasks.
This blog post delves into the intricacies of TimesFM, simplifying its concepts and architecture for beginners while providing a comprehensive overview of its capabilities.
The Power of Pretraining: A Parallel with LLMs :
Imagine you're learning a new language. If you've already mastered a similar language, you'll pick up the new one much faster. This is analogous to how foundation models like LLMs work. By training on vast amounts of text data, they learn general language patterns, making them adaptable to various tasks.
TimesFM adopts a similar strategy. By pretraining on a massive time-series dataset, it learns fundamental temporal patterns, allowing it to generalize well to unseen time-series data, even across different domains, granularities (like hourly or daily data), and forecast horizons.
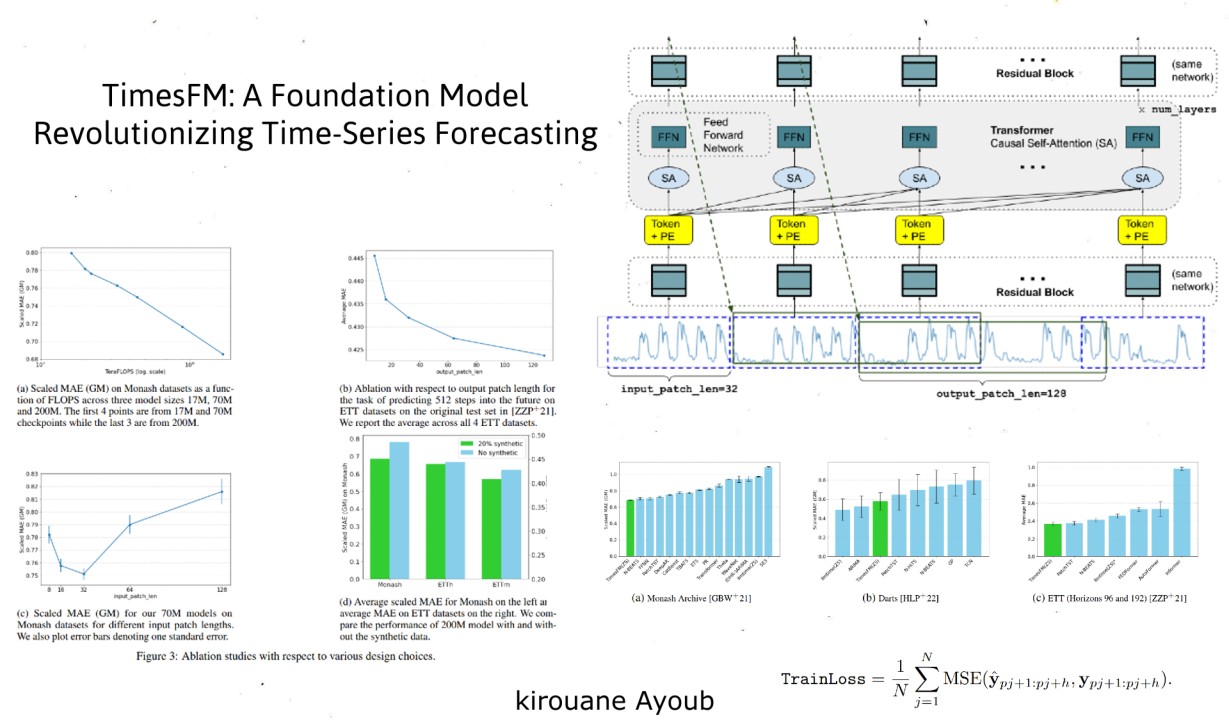
Navigating the Architecture:
Let's dissect TimesFM's architecture, uncovering the key elements that contribute to its exceptional performance:
1. Patching: Breaking Down the Data
Much like words form sentences, time-series data can be segmented into meaningful chunks. TimesFM employs a patching technique, dividing the time-series into smaller, more manageable "patches". These patches, akin to tokens in LLMs, provide a structured way for the model to process the temporal information. This approach improves computational efficiency and allows the model to handle varying context lengths during training and inference.
2. Decoder-Only Model: Predicting the Future from the Past
TimesFM employs a decoder-only architecture, similar to LLMs like GPT. This means it learns to predict the next patch based on all preceding patches. This causal nature enables efficient parallel processing and empowers the model to predict the future based on varying past information (context).
3. Longer Output Patches: Increasing Efficiency
Unlike LLMs that generate one token at a time, TimesFM can predict larger chunks of the future using longer output patches. This significantly reduces the number of autoregressive steps required, especially for long-horizon forecasting, enhancing prediction efficiency.
4. Patch Masking: Handling Diverse Context Lengths
To prevent the model from becoming overly reliant on specific context lengths (multiples of the input patch length), TimesFM utilizes a clever patch masking strategy. During training, random portions of patches, or even entire patches, are masked. This forces the model to learn from diverse context lengths, making it adaptable to various forecasting scenarios.
5. Input and Output Layers: Transforming the Data
TimesFM uses residual blocks – essentially multi-layer perceptrons with skip connections – to process the input patches into vectors compatible with the transformer layers. Similarly, another residual block maps the output tokens from the transformer to the final forecasts.
Detailed Processing and Prediction in TimesFM :
The input time-series is first divided into patches, with each patch processed by a Residual Block—a type of neural network layer that aids in training deeper networks—and combined with Positional Encoding to retain the sequence order. These patches are then passed through Stacked Transformer Layers, consisting of multiple Self-Attention (SA) and Feed-Forward Networks (FFN), to capture complex patterns and dependencies in the data. The processed patches are mapped to forecasted values using another Residual Block, allowing the model to predict larger chunks of future values at once. The model is trained using the Mean Squared Error (MSE) loss function, which measures the average squared difference between the predicted and actual values, mathematically defined as :
Building the Foundation (A Rich and Diverse Pretraining Dataset) :
The success of TimesFM hinges on its pretraining dataset. A vast and diverse collection of time-series data is crucial for the model to learn a wide range of temporal patterns. The researchers curated a massive dataset comprising over 100 billion timepoints from various sources:
- Real-world data: This includes data from Google Trends, capturing search interest over time for millions of queries, and Wiki Pageview statistics, providing insights into the hourly views of Wikimedia pages.
- Synthetic data: To ensure representation of various temporal dynamics, they incorporated synthetic time-series data generated from models like ARMA, mimicking common seasonal patterns, trends, and step functions.
领英推荐
- Publicly available datasets: Additional time-series data from sources like the M4 competition, electricity and traffic datasets, and weather data further enriched the pretraining corpus, enhancing the model's ability to generalize to different domains and granularities.
Zero-Shot Performance ( Putting TimesFM to the Test ) :
The true power of TimesFM lies in its zero-shot forecasting capabilities. The researchers evaluated its performance on three popular benchmark datasets, deliberately excluded from the pretraining data:
- Monash archive: This diverse collection of 30 datasets, covering various domains and granularities, served as a challenging testbed. TimesFM achieved remarkable results, surpassing the performance of even specialized supervised models trained on these datasets.
- Darts: This collection of 8 univariate datasets, known for their complex seasonal patterns and trends, further showcased TimesFM's ability to generalize well to intricate temporal dynamics.
- Informer datasets: Designed for long-horizon forecasting, these datasets provided a rigorous evaluation for TimesFM's capabilities. The model excelled on these datasets, achieving state-of-the-art accuracy.
The Advantages of TimesFM ( A Paradigm Shift in Forecasting ) :
TimesFM marks a significant paradigm shift in time-series forecasting, offering numerous advantages:
- Zero-shot accuracy: Its pretrained nature allows it to provide accurate forecasts on diverse datasets without requiring any additional training, saving significant time and resources.
- Generality: Unlike specialized models, TimesFM can generalize well to different domains, forecast horizons, and temporal granularities.
- Efficiency: The model's architecture is optimized for computational efficiency, particularly for long-horizon forecasting, thanks to longer output patches and parallel processing.
- Accessibility: The release of pretrained TimesFM models will democratize access to advanced forecasting capabilities, empowering users across various domains.
Usage :
Initialize and load the model
import numpy as np
import pandas as pd
import timesfm
tfm = timesfm.TimesFm(
context_len=<context>,
horizon_len=<horizon>,
input_patch_len=32,
output_patch_len=128,
num_layers=20,
model_dims=1280,
backend=<backend>,
)
tfm.load_from_checkpoint(repo_id="google/timesfm-1.0-200m")
Example with array inputs :
forecast_input = [
np.sin(np.linspace(0, 20, 100)),
np.sin(np.linspace(0, 20, 200)),
np.sin(np.linspace(0, 20, 400)),
]
frequency_input = [0, 1, 2]
# Performing Inference
point_forecast, experimental_quantile_forecast = tfm.forecast(
forecast_input,
freq=frequency_input,
)
Example with pandas dataframe :
input_df = pd.read_csv("your_input.csv") # Load your data
# Performing Inference
forecast_df = tfm.forecast_on_df(
inputs=input_df,
freq="M", # monthly
value_name="y",
num_jobs=-1,
)
Conclusion
TimesFM represents a significant advancement in time-series forecasting, leveraging the principles of large language models to achieve impressive zero-shot performance. Its innovative use of patching, decoder-only architecture, and efficient training techniques make it a powerful tool for various forecasting tasks.
By Kirouane Ayoub
Nice explanation and thanks for the write up. Does it work on any time series data? Even for domains that it has not been trained on?
AI Engineer & Data Scientist | Seeking Opportunities in AI and Data Science
6 个月Great work Ayoub! This is something I have been looking for to try. Does it work on multivariate time series?