Testing LLM Query Outputs with Cosine Similarity
Sagar Shroff
Sr Software Development Engineer In Test - Selenium | Cucumber | Karate | Cypress | Javascript | Java | AWS
Introduction
Few weeks ago, I was pondering on the thought on how to effectively test LLM based application features since their output is non-deterministic. As more applications tightly integrating AI into their product suite, traditional testing techniques such as inputA-expect-outputB would not work. Thankfully, through one of the newsletter, I came across a very well articulated Article by Amruta Pande which introduced me to - Metamorphic testing technique.
In this article, I am going to extend on the Metamorphic Technique, particularly explaining on my experiments of using Cosine Similarity as a method to quantitatively compare outputs to validate if the metamorphic relation appears holds true.
I will first start-off by explaining the problem statement, followed up by explaining about how technique such as Metamorphic Testing is helpful for validating non-deterministic output, and lastly touching on explaining about my experiment of using Cosine Similarity as a tool and some limitations I observed.
Why is LLM output indeterministic?
Most LLMs are built on GPT (Generative Pre-Trained Transformer) architecture which uses decoder based design approach optimized to generate new text. This is different from encoder-based models like BERT or similar encoding based architecture which are great at understanding and processing text instead of generating new text.
To learn more about the history and different architecture I would highly recommend this amazing video series on Youtube by Dr Raj Abhijit Dandekar . The second lesson in Hands on Large Language Models nicely explains about the history and different open and closed source architectures.
What is Metamorphic Testing?
The article, that I earlier referenced in the intro, does a great job in explaining different techniques around this, but I will try to mention few key ideas.
Metamorphic Testing uses Metamorphic Relations (MR) to find out how the output should change or remain similar when the input is changed. Or to test if the MR holds true between two pairs of input-output.
For example, if I ask the LLM what are the drawbacks of eating outside? The LLM would respond me with a list of drawbacks. Now if I ask another similar question - What negative aspects come with outdoor dining? The answer would still be semantically same.
But what if I ask - What are the benefits of eating outside? The LLM should then list some benefits such as Stress Reduction, Improving Mood etc. This second question flips the sentiment as you can see.
Now, Metamorphic Relation is useful here because we can use it as tool to test non-deterministic outputs like above to gauge if the relation has changed for the answers given by LLM.
My experiment of using Cosine Similarity to test MR programmatically
As a next step, I wanted to find what tools could we use to test if MR holds true or not programmatically. There were multiple options, one being using LLM itself to test its output but I wanted to explore more options.
In the intro, I briefly mentioned that encoder based architectures are good at understanding and processing text. So I thought of using such as SentenceTransformer with cosine similarity as tool to quantitatively measure if 2 texts are same/different/opposite.
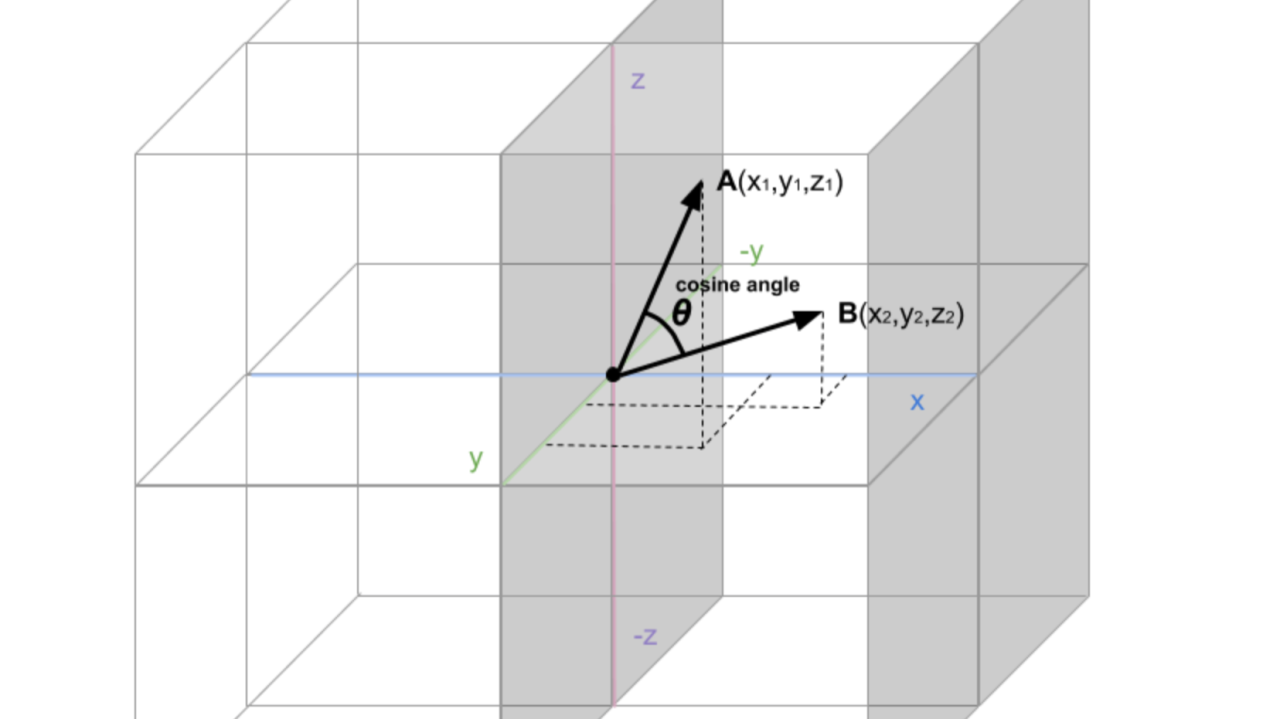
My idea was we can use Cosine similarity to measure the angle between two vectors in vector space, thereby quantifying the similarity between any two textual outputs from LLM.
领英推荐
Cosine similarity, which computes the cosine of the angle between two vectors, returns a value within the range [-1, 1]. And depending on the value return it could mean of the following:
This way we can test the LLM by testing different pairs of prompt and test the Metamorphic relation between their output is similar, or different, or opposite.
Some more context about Vectors
So Machine Learning models do not directly understand textual data, for them texts or words are resembled as numeric vectors in high dimensional vector space. A vector space can be made of 1, 2 or many dimensions (high dimension) based on the number of features in the sentence. Each dimension in vector space represents a different feature of a text.
For example, take the sentence "Sagar is a Senior SDET proficient in Java and Python." One dimension might capture the seniority level indicated by "Senior SDET," another could reflect the technical skills like proficiency in "Java" and "Python," and another might represent the overall professional context. There could be more dimensions that might encode information about the emotions, context, etc.
All the sentences are represented as numeric vector in the vector space. And my solution here is simply measuring how close 2 vectors are to each other in vector space to find their similarity.
Implementation Example
I have hooked up my Jupyter notebook here with the outputs.
Limitations
While I was playing around, I observed following limitations
Output for query1: She is really excited about her promotion
Output for query2: She is not really excited about her promotion
Cosine similarity between the outputs: 0.9077736139297485
The texts are highly similar.
Output for query1: Oh great, another rainy day!!!
Output for query2: Oh great, another day at the beach, I am so lucky
Cosine similarity between the outputs: 0.5919630527496338
The texts are not closely related.
QA Instructor @ 1 Million Students Udemy | 25+ Best Selling Test Automation Courses | EventSpeaker-QASummit.org | Mentor | Founder- RahulShettyAcademy -EdTech QA Platform | Proud Tester | ex-Microsoft
3 周Good read. ?? I think you should also look at LLM eval frameworks like RAGAS which can do this with straight forward wrapper methods.
SDET
3 周We have evals framework to do it Where you send your prompt , response from LLM and the eval instructions You can test your response based on a few params like instruction following, completeness , coherence. https://github.com/openai/evals Now I am assuming eval might be using coherence similarly internally.
Test Automation Consultant ?? Avid Tech YouTuber ?? Udemy Trainer ??
3 周Well, most of the vector database supports Cosine similarity vector_store.similarity_search_by_vector(query_embedding, k=2) So, if you are retrieving data from vector stores which is returned by the large language model then this method will do what you are pointing out right now
Software Engineering Manager Dev Infra (Platform) and Tools at Workday Analytics
3 周Insightful