SQL database replication: Logical or Physical?
Franck Pachot
Developer Advocate at ?? MongoDB ??AWS Data Hero, ?? PostgreSQL & YugabyteDB, ??? Oracle Certified Master
Traditional SQL databases have incorporated replication after their initial design. This can be achieved by implementing replication on top of crash-recovery write-ahead logging (WAL) or capturing the changes within the SQL processing. The changes can be applied to the replica in two ways: by writing the same data into the database storage, known as physical replication, or by generating an SQL statement to apply to the replica, known as logical replication. More recently designed databases, often referred to as cloud-native, have built-in replication that combines the advantages of both logical and physical replication. Let's explore all these alternatives.
Physical replication from WAL
Traditional SQL databases are typically monolithic. They write to one shared buffer pool in memory, which is then flushed (checkpoint) to disk asynchronously. This approach helps to avoid slow random writes on HDD and SSD. To protect against potential memory loss in case of server failure or instance crash, all writes are safeguarded by Write-Ahead Logging (WAL), described in 1992 in the?ARIES?paper. WAL is also called an online redo log, journal, or transactional log and is a single thread written sequentially.
To reduce the Recovery Point Objective (RPO), the WAL is archived to roll forward transactions during recovery from backups. To minimize the Recovery Time Objective (RTO), this recovery process is continuously run on a standby database, ready to be activated for Disaster Recovery. When high availability (HA) is required to minimize data loss and automate failover, the WAL is streamed to the standby through the network, written to files, and synchronously committed to ensure the durability of committed transactions.
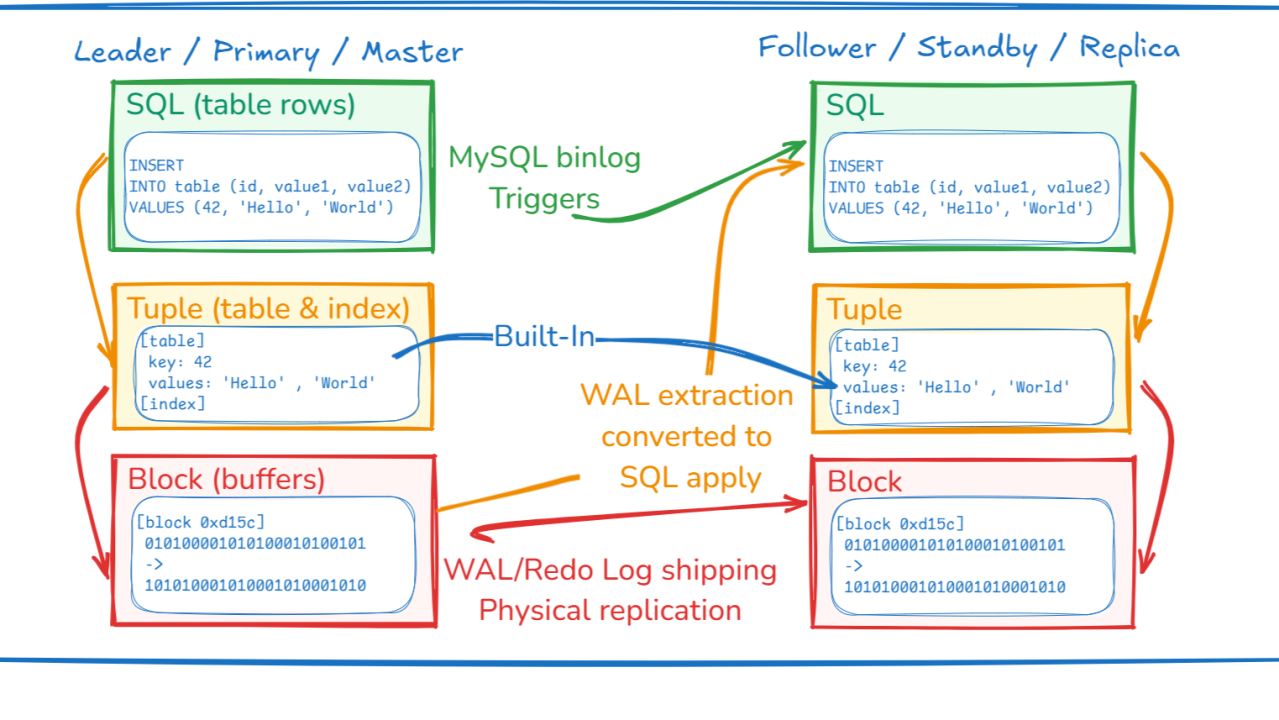
This is called physical replication because it synchronized an exact binary copy of the database:
Physical replication has its advantages and disadvantages. On the positive side, it results in low overhead on the primary database since it utilizes the existing Write-Ahead Log (WAL). Additionally, there is minimal overhead on the standby database as it writes directly to the buffers, bypassing the query layer. Indexes are replicated along with the tables as bytes in datafiles.
On the downside, there is limited flexibility in using the standby database beyond its activation in case of a disaster recovery scenario. At best, it can be opened in Read Only mode to allow consistent queries with minimal synchronization with the standby. However, there are very few optimization options for this read-only workload. This is because, being a physical replica, it runs the exact same version of the database software and has the same physical and logical model. Such a replica cannot be used to reduce downtime for upgrades or to design different indexes for the read workload.
Logical replication from SQL
To provide the best flexibility, replicating between different platforms, versions, and data models, the replication can be logical, at higher level. Thanks to data independence, it would be possible to run the exact same SQL statements on a replica. However, this is not as easy as it looks like because reads and writes must be intermixed in SQL. A simple example is a sequence, or a generated always as identity column. Running the same INSERT on two databases may set a different number. Even if both are correct, the replicas differ and the next statements will not have the same effect. Even when not using those non-deterministic functions of SQL, the ordering of the SQL statement effects is dependent on the concurrent transactions which may conflict or lock the same rows, and this will be different on a replica.
In practical terms, logical replication from SQL involves generating a SQL statement to be applied on the replica. This statement is created at a lower level of SQL processing based on the final writes of table rows. Changes to the rows are captured using triggers or similar mechanisms, which then generate a set of simpler SQL DML statements. Oracle previously had Advanced Replication, but it has been deprecated. MySQL, on the other hand, provides binlog replication. The same can be done on other databases with triggers.
Logical replication has a significant advantage in its flexibility on the replica side. It can apply SQL statements independent of the database's version or the physical data model. This means it can replicate only a subset of tables, rows, or columns and be set up as a two-way, multi-master system with custom conflict resolution. However, one drawback is the resources used on the replica side, as the SQL must be processed and indexes maintained. This is an unavoidable effect of the flexibility provided by logical replication.
The main disadvantage of this solution is on the capture side: triggers or equivalent impact the primary workload.
Logical replication from WAL
A third option combines the advantages of the two previous solutions by capturing the changes at the physical level and applying them at a logical level. The general idea is to mine the WAL and, combined with some additional metadata, reverse-engineer it to produce an SQL DML statement with the same effect on data. The overhead on the primary database is minimal, with supplemental logging to add information unavailable in the physical change vector. The flexibility on the replica is maximized as the SQL queries insert, update, or delete the corresponding rows using the SQL layer. What is more complex is the extraction to capture the logical changes from the physical log.
This solution is specific to each database, and there may be some limitations about what data types are supported. Another limitation of the capture process is linked to the monolithic nature of the WAL stream. Log mining is rarely multi-threaded as it is sequential, and the transaction order must be preserved. Another thing to consider is that the initialization must follow a different process. Before being able to apply the captured changes, the tables must be copied logically, like with a dump. This is slow and increases the window for logical replication to resolve the gap. Another possibility is to start with a physical replica and convert it to a logical one.
Even though this architecture looks like a workaround, operating between different layers, it is the most used in traditional databases when more flexibility than physical replication is desired and there is no change data capture (CDC) built-in at higher level.
Built-in replication of table and index changes
The options mentioned above do not consider the most straightforward solution: creating replicas above the physical layer to allow for greater flexibility. These replicas would not be exact binary copies of each other but would exist below the SQL layer to reduce the overhead on the capture and application. Between SQL and blocks, there are table rows and index entries, all containing values that would provide a replica that is logically equivalent to the primary but allows for a different physical organization.
Traditional databases such as Oracle and PostgreSQL are monolithic and do not have a clear separation between the SQL processing layer and the transactional storage. In these databases, a single session process handles SQL parsing, execution plan building, and directly reading/writing into table and index blocks. The table rows are stored in heap tables without a logical identifier. For instance, Oracle uses ROWID and PostgreSQL uses CTID to represent physical addresses within a block and offset within a file.
YugabyteDB addresses this issue by separating the SQL processing layer, which uses PostgreSQL code for compatibility, from the transactional storage layer, sharding on top of RocksDB. The SQL processing layer generates read-and-write operations as key-value changes, while the transactional storage layer applies these changes to the LSM Tree, which stores table rows and secondary index entries.
This separation enables scalability: the SQL processing layer can scale horizontally because it is stateless, and the transactional storage layer can also scale horizontally because it is partitioned (storage sharding). The write API between them is a log of timestamped key-value changes distributed and replicated with Raft consensus. This log is applied to each replica, strongly consistent (linearizable), and is also used as the Write-Ahead Log (WAL) to protect the first level of the LSM Tree before being flushed to SST files. Below this key-value API, each replica physically applies the changes. They can run different versions of the database software, allowing for online rolling upgrades. Each replica runs the Multi-Version Concurrency Control (MVCC) garbage collection locally. This is embedded in the SST File compaction and does not impact replication.
From the storage point of view, YugabyteDB replication is similar to logical replication, where it relies on the schema to identify the change record (primary key, indexed columns). From the SQL point of view, it looks like physical replication as it resolves sequence, identity columns, transaction ordering, and index maintenance. This is integrated with Raft, LSM Tree, and MVCC.
Which one is better?
The best solution is one that matches your database. Each database vendor has implemented what works best for their engines.
Traditional databases have been designed as monoliths. They make changes by modifying buffers that match the disk blocks and rely on physical write-head logging (WAL). This approach makes sense rather than adding hooks to capture changes at higher levels. The WAL is directly applied for physical replication, using the same code used for recovery, or it is mined to extract the changes and apply them using the existing SQL layer. Traditional databases leverage proven technologies and prefer to add replication on top of them. Mostly deployed on premises with dedicated hardware, their users do not expect horizontal scalability and resilience to failure.
On the other hand, new SQL database engines built for the cloud have been designed with replication in mind. They write to the network rather than to local disks. The log is at the core of distributed databases because a log of buffered write operations is the best fit for the network, can be replicated with strong consistency using a consensus algorithm like Raft, and is a perfect fit for LSM Tree, which is more efficient than B Tree for modern storage like SSD. For distributed SQL databases, the replication is built-in at a level that combines the advantages of traditional logical and physical replication.
Chief Consultant - Technology at Genius Computing Services
5 个月Insightful
30K 1st level connections | Servant Leader | Cloud DBA/DBE/Developer | #ladataplatform #sqlsatla #sqlsatsv #sqlsatoc #sqlsatsd
5 个月LA Data Platform UG