Simplifying Data Streams with Kafka: A Guide for Beginners
Adarsh Mishra
Innovative Software Engineer | Rust, C++, Java | Expert in Distributed Systems, Microservices | Passionate about High-Level Design & Optimization |
In the world of software, efficient communication between services is crucial. But how do we manage this communication effectively, especially when dealing with large volumes of data? This is where Apache Kafka comes in – a powerful tool designed to handle real-time data streams. Let's explore Kafka and its role in simplifying service communication.
The Problem of Service-to-Service Communication:
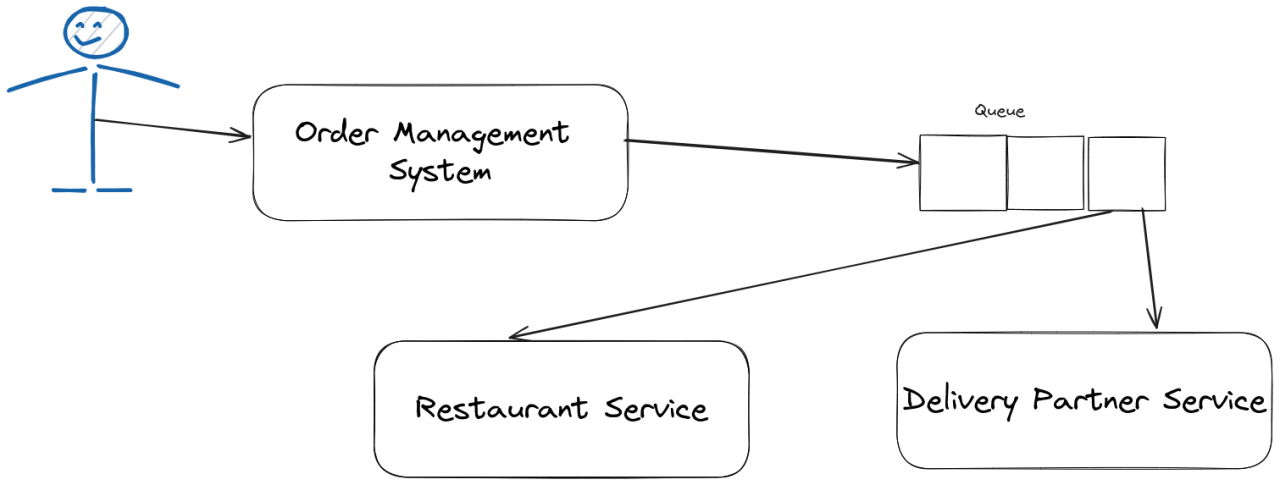
Option 1: Synchronous Communication Imagine two services needing to exchange information. The traditional method is synchronous: Service A sends a request, and Service B responds. However, this method has a limitation: Service A cannot send another request until it receives a response from Service B, leading to potential delays and dropped requests.
Option 2: Introducing a Queue with Kafka To overcome this, we introduce a queue system, where Kafka shines. Instead of direct communication, services interact through a Kafka queue. This approach ensures no data is lost and services can operate independently without waiting for immediate responses.
Understanding Kafka:
领英推荐
Challenges and How Kafka Addresses Them:
Key Takeaways: Kafka offers a reliable, scalable solution for managing data streams between services. Its architecture ensures efficient processing, fault tolerance, and data integrity, making it an ideal choice for modern applications dealing with large volumes of data.
Engagement: Have you used Kafka in your projects? What challenges did you face, and how did Kafka help? Share your experiences in the comments below!
Conclusion: Kafka is more than just a tool; it's a gateway to efficient, reliable data processing in a world where real-time data handling is paramount. Stay tuned for more deep dives into Kafka's features in upcoming posts.
Additional Resources: