Simplifying AI Development: A Practical Guide to HeatWave GenAI’s RAG & Vector Store Features
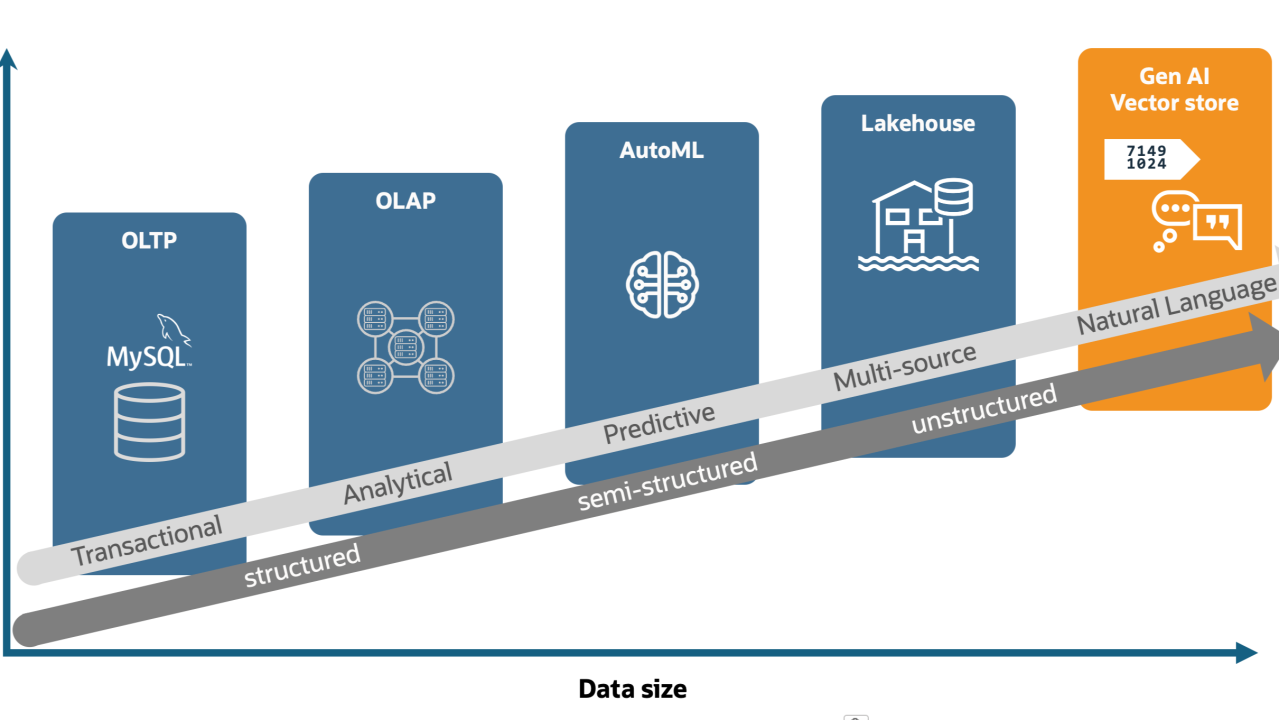
This tutorial explores HeatWave GenAI, a cloud service that simplifies interacting with unstructured data using natural language. It combines large language models, vector stores, and SQL queries to enable tasks like content generation, chatbot, and retrieval-augmented generation (RAG). The focus is on RAG and how HeatWave GenAI’s architecture helps users gain insights from their data. By the end, you’ll learn how to implement these features effectively to unlock the full potential of generative AI for your applications.
Full version: https://dasini.net/blog/2024/12/10/simplifying-ai-development-a-practical-guide-to-heatwave-genais-rag-vector-store-features/
HeatWave GenAI empowers you to interact with unstructured data seamlessly using natural language. Whether you’re performing content generation, summarization, sentiment analysis, or retrieval-augmented generation (RAG), HeatWave GenAI simplifies the process with its intuitive design and robust features.
Here’s why HeatWave GenAI stands out:
领英推荐
What is RAG?
RAG stands for Retrieval-Augmented Generation. It’s a technique that combines the power of Large Language Models (LLMs) with external knowledge bases. The primary goal of RAG is to enhance the quality, relevance, and accuracy of AI-generated responses by retrieving relevant information from these sources.
Essentially, it’s like giving an LLM access to a vast library, allowing it to provide more informative and contextually relevant answers.
How RAG Works