Setting up Ollama + OpenWebUI on Docker
I just got a 128GB M4 Macbook pro (woo hoo!) - well out of need since my older 16GB M1 pro couldn’t run any of the 70B models. (The challenge with Mac continues to be the lack of CUDA!) Anyways, so the easiest way to try out the models is to serve them using Ollama and OpenWebUI. More recently, using Docker to run the things feels more cleaner - everything has their own containers and I can observe the processes more cleanly. Otherwise, running everything from the command line leads to a lot of switching between windows, and improper logging.
But running these things on Docker take a bit of learning curve. So here are the steps for running these on MacOS.
1. Install Docker Desktop - this is a useful UI for managing docker images and containers. A Docker image is prepackaged collection of software that is built to run a particular software e.g. there is a docker image for Ollama and a docker image for OpenWebUI. So on my docker desktop these will look like this:
2. To get ollama into the Docker desktop goto your command line and run the following command - this has to be run from command line - it will download the image of ollama if you don’t have it - as you can see from previous image its a 7GB image:
docker run -d -v /Users/prayank/ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
This command will take the /Users/prayank/ollama - local directory and map it to the /root/.ollama directory in the container, also it will map the local port of 11434 to the port of the container 11434. (the variables are in host:container mapping format) . You can see the contents of my ollama directory here:
3. To run the image from the Docker desktop, goto Images and click on the play icon next to the ollama image, then it will show an options screen, you can enter the following:
Once you set these settings and run, these settings will become the initialization parameters of the container from the image.
4. You should be able to access Ollama API server now. Try this from command line:
curl https://localhost:11434/api/tags
Or, you can access the URL in the browser. You will get an output like this :
5. You can go into the Ollama container in Docker Desktop to run commands for listing, downloading and running models. See below:
6. You can even see logs of ollama:
7. And also the stats, this is where I see how much RAM / CPU my models are consuming:
8. For Open-WebUI (github), we need to make sure it can access our Ollama server so we need to use the following command to run the container:
docker run -d -p 3000:8080 --restart always --name open-webui --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data ghcr.io/open-webui/open-webui:main
This command tells docker to run the container as a daemon (-d), and ‘--restart always’ will make it startup every time we start docker and the ~/open-webui directory on host is mapped to the /app/backend/data container directory.
The most important part is ‘--add-host=host.docker.internal:host-gateway’, allows containers to resolve ip and connect with services running on the host machine. (documentation)
9. When you are running Open-webui from Docker Desktop, the options should look like this:
10. You should be able to now access open-webui on https://localhost:3000/
11. If things are all well you should be able to login to your Open-Webui interface, now goto User → Settings → Admin Settings
12. You should see your ollama settings:
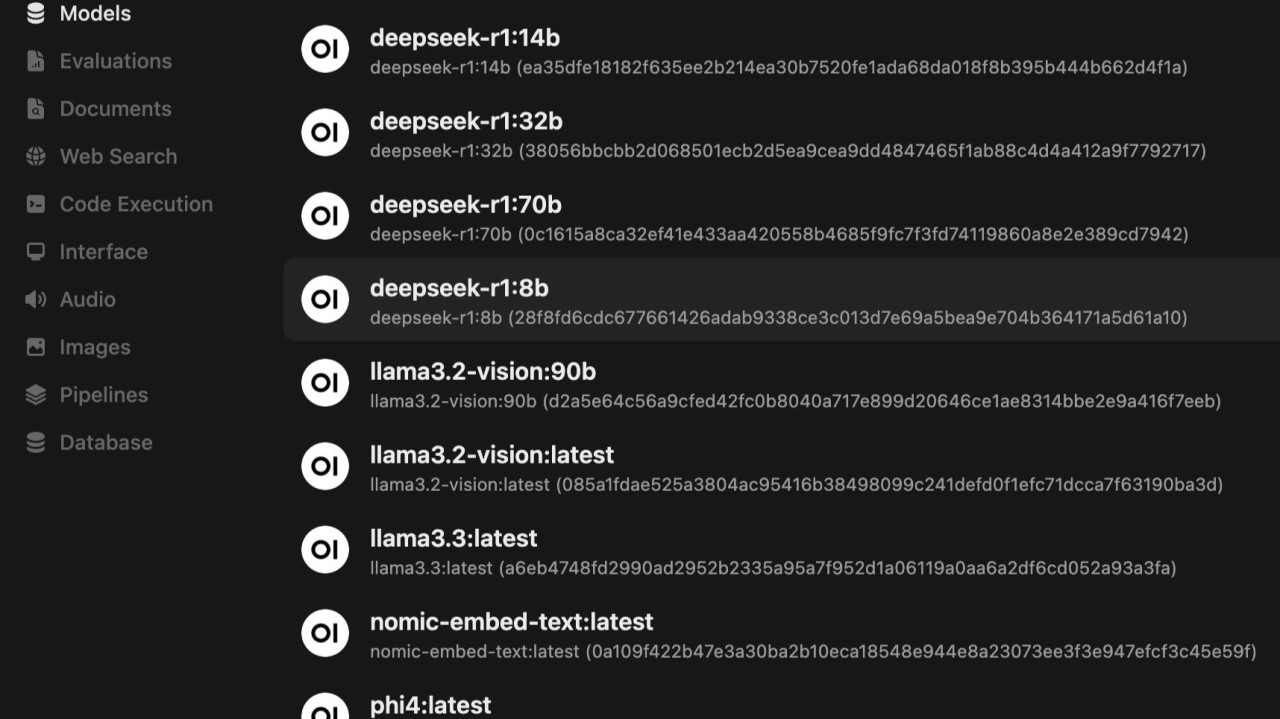
13. If you goto models you should be able to see all your models in Ollama docker, if things are doing ok.
14. You can now start chatting with your model.
You are good to go!
(TIP: In my case I have forgotten my password couple of times for Open-Webui, you need to to the Docker Desktop → OpenWebui container → Exec. Then goto /app/backend/data and delete the webui.db file and restart the container. It will ask you to recreate the accounts. )
(TIP: One of the things that I need control over is context length in my chats in OpenWebUI, since by default Ollama / Open-webui context length is 2048, you can work around this by setting chat specific context length, click on the “Controls” in the chat in the top right and set the context length.)
Founder & CEO @ Ploton
1 周You can always just get a Mac Studio 512GB RAM for $24k and save the money on APIs spending.?
Global Business Development Manager at RWS Group | "Helping Enterprises Scale with Cutting-Edge IT Solutions | DevOps | Cloud | AI | Cybersecurity | 24x7 IT Support ??"
1 周I’d love to connect and share how RWS Technology Services is helping businesses like yours stay ahead with digital transformation, Custom Web & App Development, AI integration, and intelligent automation. From cloud solutions and DevOps to data analytics and dynamic testing services, we enable organizations to scale efficiently, optimize operations, and drive innovation in a rapidly evolving landscape. If you’re exploring cutting-edge technology solutions, let’s schedule a quick call to discuss how RWS can support your digital journey. When would be a good time for you? ?? Explore our services here: https://shorturl.at/j7SEv Feel free to share your requirements at [email protected], or visit www.rws.com for more details. Looking forward to connecting!
Senior ML Engineer II at o9 Solutions, Inc.
2 周Here's my post on the same topic! :) https://everythingpython.substack.com/p/i-want-to-run-llm-models-locally
Technologist | Ex - Agriculturalist, Hunter Gatherer, Herbivores Primate
2 周Apple silicon seems like a great balance of performance per watt & cost both. 128 gigs mac is way cheaper than pulling up 4x24GB 4090 or better, especially if your use case is personal & don't mind ~25-30 tokens/ sec Thanks for sharing!
You should get a Mac mini setup and run a home server with the exo labs stack. Then you can run AI on confidential data with good tok/sec and without heating your Mac too, cos that’s the most scary part ime.