Region-Based Object Detection (R-CNN Object Detection)
What is RCNN?
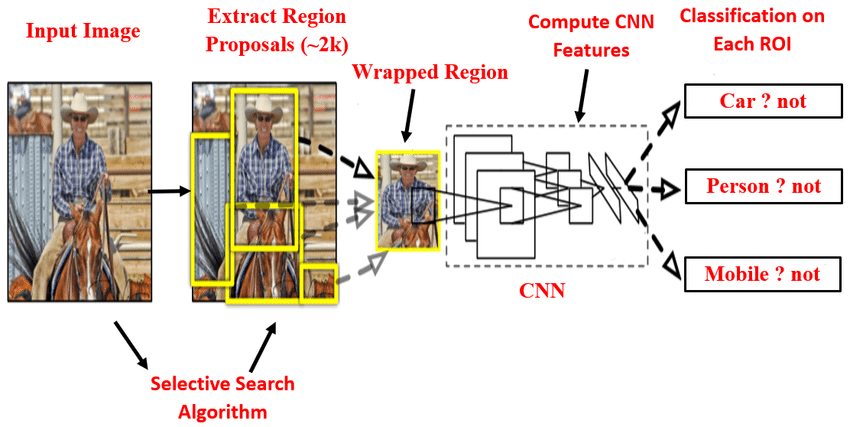
R-CNN (Region-based Convolutional Neural Network), or?Regions with CNN Features, is an object detection model that uses high-capacity CNNs to bottom-up region proposals in order to localize and segment objects. It uses?selective search?to identify a number of bounding-box object region candidates “regions of interest” and then independently extracts features from each region for classification.
How does the R-CNN model work?
As can be seen in the image above before passing a shot through a network, we need to extract region proposals or regions of interest using an algorithm such as selective search. Then, we need to resize all the extracted crops and pass them through a network.
Finally, a network assigns a category from C + 1, including the ‘background’ label, categories for a given crop. Additionally, it predicts delta Xs and Ys to shape a given crop.
Region Proposals :
The region proposal step selects about 2000 areas (bounding boxes) in the image where objects are likely to be. They chose the?Selective Search?method because it is easy to compare the performance with the previous research that uses the same method.
R-CNN is agnostic to region proposal methods because the region proposal step and the subsequent CNN feature extraction step are independent. It first selects regions and then applies CNN feature extraction to each region.
Since selected rectangle areas have various sizes, all areas are warped (resized) to a fixed size of 227×227 pixels. It ensures that the bounding box dimensions are constant and that the features extracted by the CNN layers all result in the exact dimensions.
CNN Feature Extraction :
R-CNN uses five convolutional layers and two fully connected layers in AlexNet to extract features from each area (227×227 pixels) into a 4096-dimensional vector. It then uses the features to classify the images in each area. It is transfer learning, where the final part is SVM, which makes the judgment for image classification. SVM was a widely used method, and they followed the same approach for the last classification step.
SVM Classification :
领英推荐
Now we will need to classify those feature vectors. We want to detect what class of object those feature vectors represent. For this, we use an SVM classification. We have one SVM for each object class and we use them all. This means that for one feature vector we have n outputs, where n is the number of different objects we want to detect. The output is a confidence score.
NOW, how we trained those different SVMs?
Well, we train them on feature vectors created by AlexNet. That means, that we have to wait until we fully trained the CNN before we can train the SVM. The training is not parallelizable.
Non Maximum Suppression :
NMS is a greedy algorithm that?loops over all the classes, and for each class, it checks for overlaps (IoU — Intersection over Union) between all the bounding boxes. If the IoU between two boxes of the same class is above a certain threshold (usually 0.7), the algorithm concludes that they refer to the same object, and?discards the box with the lower confidence score?(which is a product of the objectness score and the conditional class probability).
Intersection over Union (IoU) :
The?Intersection over Union (IoU)?metric, also referred to as the?Jaccard index, is essentially a method used usually to quantify the percent overlap between the ground truth BBox (Bounding Box) and the prediction BBox. However, in NMS, we find IoU between two prediction Bounding Box instead.
IoU?in mathematical terms can be represented by the following expression,
Intersection Over Union(IoU) =
(Target ∩ Prediction) / (Target U Prediction)