This is the final installment of our three-part series highlighting Rakuten Symphony Cloud Business Unit President
Partha Seetala
's “A Comprehensive and Intuitive Introduction to Deep Learning” (CIDL) web training series, which provides an accessible introduction to neural networks for anyone working in the field of AI.??
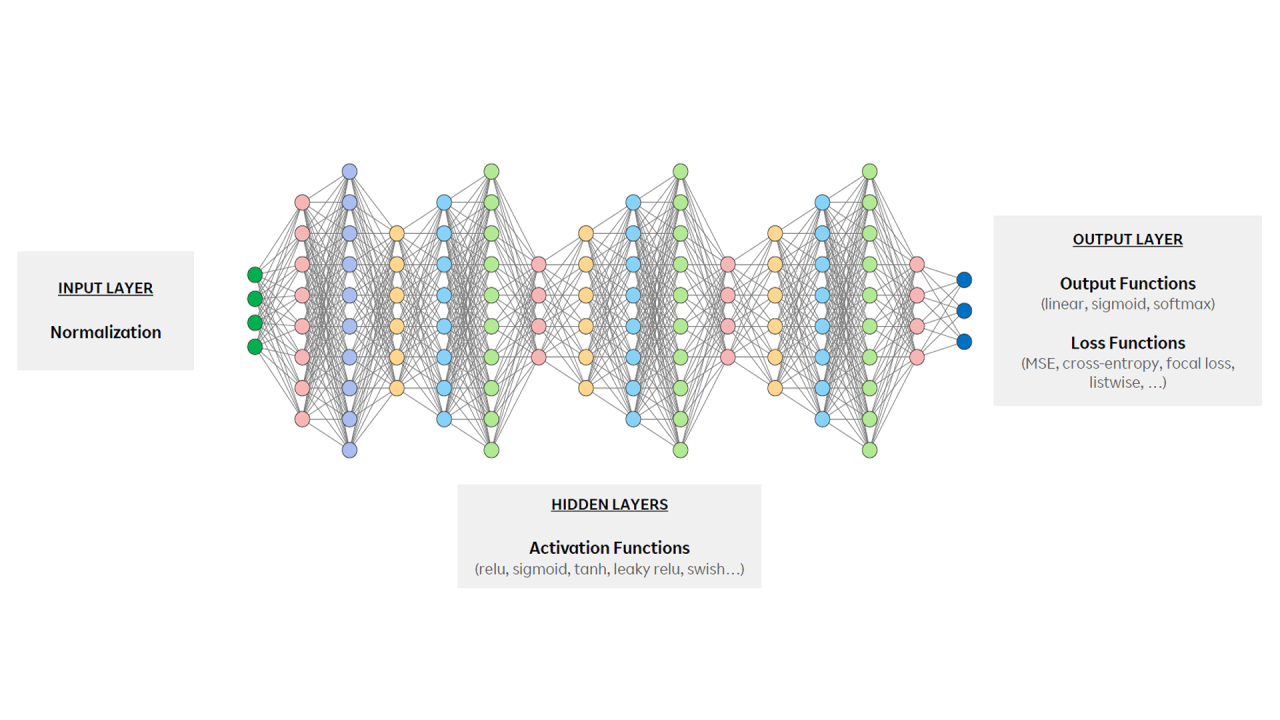
Our previous issue of Zero-Touch Telecom covered how to optimize the input and output layers of neural networks, focusing on concepts like input normalization and output functions. Our final deep learning training issue focuses on techniques for fine-tuning the “hidden layers” that comprise the “heart” of a neural network. We’ll explore activation functions, weight initialization, training stabilization and ways to avoid challenges like overfitting. Each plays a role in improving neural network performance.???
The hidden layer of a neural network sits between the input layer where data is fed, and the output layer where predictions and classifications are made. Whereas input and output layers deal with raw data and final results, the hidden layer handles intermediate steps that transform data into increasingly complex patterns and features. These layers learn to identify patterns from input data that aren’t immediately obvious.???
Simply put, hidden layers are where the learning occurs. So it is vital to tune them properly to increase effectiveness in complex environments like telecom networks.????
Let’s break down the top five takeaways from episode three:???
- Activation functions introduce non-linearity. Partha explains how activation functions like ReLU (Rectified Linear Unit), Sigmoid and Tanh introduce non-linearity into neural networks to capture complex, non-linear patterns in data. In telecom networks, non-linear patterns are prevalent in tasks like predicting customer churn, detecting network anomalies and optimizing traffic routing. Activation functions improve the network’s understanding of traffic patterns for better predictions and optimization.?
- Weight initialization makes learning more efficient. In neural networks, each connection between neurons is assigned a weight before training begins and is adjusted during training to learn from data and make more accurate predictions. Correctly initializing weights at optimal values with techniques like Xavier and He prevents issues that hinder training processes while allowing neural networks to learn more efficiently. A telecom network may have thousands of parameters to monitor, making proper weight initialization critical for efficient data processing. The result is faster and more accurate insights to support tasks like capacity planning, fault detection and network optimization.??
- Batch normalization can stabilize training processes. Batch normalization balances hidden layer activation values to help AI models converge faster and perform better. It reduces internal covariate shift for more consistent learning even as the network deepens. Telecom networks with varying conditions can rely on batch normalization to ensure neural networks remain stable and adaptable—and ultimately more effective.??
- Regularization will help avoid overfitting. Overfitting happens when a neural network learns the training data—noise and all—too well. This leads to a scenario where models perform well on the training data itself but not the real-world data they are eventually fed. Partha discusses techniques like L1 (lasso) and L2 (ridge) regularization that prevent this phenomenon from occurring. Overfitting can be particularly problematic in telecom networks since data patterns shift frequently due to?things like changing user behavior, seasonal traffic variations or live events. Regularization keeps AI models flexible as network conditions evolve.???
- Residual connections enhance signal strength. Residual connections propagate signals across multiple layers to keep the flow of info constant for deep neural networks. This ensures critical insights aren’t lost as data is processed across layers. Overall, these connections improve a model’s ability to identify subtle patterns or anomalies, like rare but impactful network performance issues that may indicate impending outages or degradation.??
Check out episode three of “A Comprehensive and Intuitive Introduction to Deep Learning” below and subscribe to Partha’s YouTube channel to get alerts when new training episodes are uploaded.???
Mention
Partha Seetala
in the comments now to ask questions or start a conversation.?
Ameya Digital is a premier digital marketing agency dedicated to guiding businesses through the complexities of today’s digital landscape with innovative, client-centered strategies and state-of-the-art solutions. With clients globally—from the USA, Canada, Singapore, and GCC countries to China and India—our mission is to help brands thrive through tailored digital marketing strategies that enhance visibility, engagement, and long-term growth. https://www.dhirubhai.net/company/ameya-digital/?viewAsMember=true
IN Manager
2 个月Nice information
Quality focused software testing specialist having experience of one and half decades in telecom and education domain | UAT | functional testing | Defect management | OSS | BSS | Test Management | Agile | Scrum
2 个月Optimization is an iterative process. Continuously experiment, evaluate, and refine your network's architecture and parameters to achieve the best possible results.