Optimizing AI Systems: Fintech Case Study
I downloaded 40 years' worth of daily data for the S&P 500 index, to devise trading strategies that outperform the baseline (staying long on the index). These strategies have parameters that you can fine-tune to achieve specific goals. Each parameter set characterizes a strategy and was tested on 12 different time periods. A strategy tells you when to enter (buy into the index), when to exit, and when to re-enter, in order to beat the market by leveraging periodic sharp drops and multi-years runs in bull territory. Typically, over a 10-year time period, the number of exits / re-entries is small, less than 15, and sometimes as low as 2. Despite the vast amount of data, there are very few trades, usually spaced out. Optimizing can easily lead to over-fitting.
领英推荐
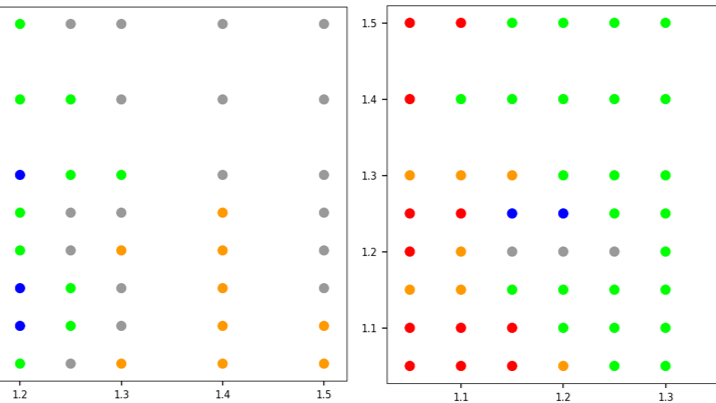
While the topic is about trading strategies that work, the most interesting part is about AI optimization techniques. Each dot in the figure represents the average performance of a trading strategy over different time periods. It ranges from great (blue, green) to no better than baseline (grey) and finally to poor performance (orange and red). Each strategy is defined by 3 parameters: two of them with values displayed on the X and Y axes, with the third one displayed in a different slice: the left and right scatterplots correspond to two different values of the third parameters.
There are obvious areas of good and bad performance in the parameter space. The idea is to find stable, good parameter sets, not too close to a red dot to avoid overfitting. This is similar to identifying the best hyperparameters in a deep neural network, using techniques such as smart grid search or boundary detection . There is no reason to look for a global optimum. It would be time-consuming, and the gain would be minimal. The same philosophy applies to gradient descent in neural networks, where over-optimizing leads to “getting stuck” (vanishing gradient). Note that in this case, the implicit loss function is somewhat chaotic — in particular, nowhere continuous — though gentle enough to lead to valuable results. You may use my math-free gradient descent algorithm featured here , suitable for pure data (no loss function), to solve this problem.
??To access the code, data, and technical paper, follow this link . All free.
Head of Growth and Transformation @MNCL | Empowering the Next Generation of Investors | Simplifying Investing for India's Youth
2 天前This case study is fascinating! The focus on stable, robust parameter sets over global optimization is a smart approach for navigating the chaotic nature of financial markets. Drawing parallels to AI hyperparameter tuning and employing a math-free gradient descent algorithm adds a practical and innovative edge. Great insights!
?? Grow your ideas from the data up ?? Data and R&D Solutions | Data Scientist | Neuroscientist
4 天前Very interesting, thanks for sharing! Can you explain why you chose this way of parameter tuning over the alternatives? Regarding your results of slightly beating the index: If I understood correctly, you did not correct for the cost of buying and selling (commissions + tax). I wonder how much adding these costs (especially tax, 25% of the profit where I'm sitting) would eat into your profit, especially when taking into account its compound nature.
Business Developer
2 周Very Insightful! Vincent ??
Software Projektleitung SUMS
2 周This is very interesting
--ownership means I own so were is my stuff ????
2 周Thanks sir I'll check it out / ?? maybe if you have more time I'd like to ask you some questions? Conclusion