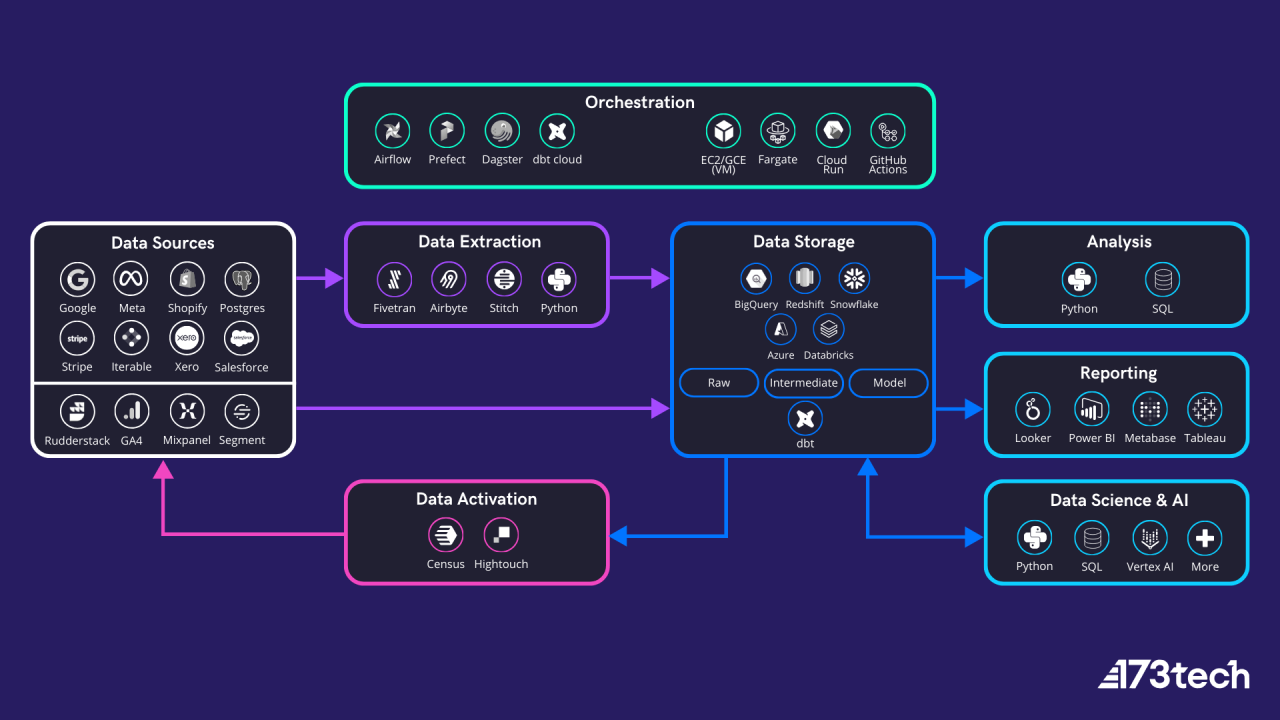
Modern Data Stack Components
In the previous article, we discussed the key considerations when designing a modern data stack. What makes up a data stack? How does information travel from its source systems, combine with everything else and become actionable insights, e.g., automated dashboards, in-depth analysis, predictions. And where does AI sit in all of this?
Below diagram shows the main components and a top level flow. We will discuss each part in detail but the important thing to note is that your pipeline should cover all your analytics needs and it is a full circle where data and insights travels from and back into your source systems.
At 173tech, we are tool agnostic with a preference towards cloud and open source technologies. Here we listed some of the most common ones. There are more options depending on your unique use cases.?
Data Sources
These are your various systems that generate and collect data. It ranges from your website, marketing channels and attribution tool, to CRM systems, backend and operational databases and more. A scaling company in its first few years will typically have around 10 data sources.?
Data Extraction
Your sources of data usually sit in silo, making it difficult to draw insights and conclusions across the customer journey. Ideally, all information should be connected together within a single source of truth. To do so, you first need to bring all data together. Data extraction is the process of retrieving data from multiple sources into a single destination.
Data Storage
This is where all your data sources are centralised. The main types are data warehouses, data lakes or lakehouses. In general, data warehouses are designed to store structured data, data lakes for structured, semi-structured and unstructured data, and lakehouses support a hybrid approach.?
This is likely to be the highest cost component within your data stack so you need to consider business use cases today and in the future, scalability and cost upfront. The main options here are BigQuery, Snowflake, Redshift, Microsoft Azure SQL and Databricks.
Data Modelling
Once source data lands into your chosen data storage, it will go through a process of transformation based on your unique set of business logics. The resulting set of data models, organised by business concepts, is the source of truth for all your downstream analytics needs by other the data team and business users.?
The most widely used tool for data modelling is dbt. It is SQL based, has a large open source community, and designed for both data engineers and analysts to contribute to the pipeline.?
Analysis
Where most business users will rely on dashboards to monitor trends and the health of the business, the analysis layer is where you deep-dive into specific topics in much greater detail. It is typically used by Data Analysts who are looking for the “why” behind the “what”.?
领英推荐
To perform deep-dive analysis, you need a workflow to query, explore and present data. Jupyter Notebook is a good option with Python and SQL as the main programming languages. The main benefits over Excel spreadsheets are the ability to leverage a wide range of Python libraries for data processing and incorporate machine learning models; combine code, charts and text explanations in one document for both data exploration and presentation; and easy to share and rerun. Although, if you find yourself repeating the same analysis, consider moving it to the reporting layer as an automated dashboard.
Reporting
This is the layer with the highest impact in democratising data among business users. Here modelled data is turned into charts and dashboards which make information easy to digest and investigate. One of the key purposes of reporting is to automate repeated data requests so that your data team can focus on finding deeper insights and generating more business value.
Dashboards are a great tool for everyday monitoring of key stats that will guide your business. The main tools that we recommend are Metabase, Looker (not Looker Studio), Tableau, and Power BI.
Data Science & AI
These are more advanced analytics with a wide range of use cases, e.g., predictions, dynamic user segmentation, matching algorithms, text analytics. Ideally, this layer should sit on top of already modelled data to leverage the same pipeline for cleaned and enriched data.?
The key thing to note here is to capture the results of your data science and AI models within your data warehouse as much as possible so they can be combined with other data points and reused by other parts of the business.?
Data Activation
So far, we discussed the process of extracting, loading and transforming (ELT) data from source and a number of use cases within the data pipeline. To make it a full circle, the last step is sending modelled insights back into the source systems. This process is also referred to as Reverse ETL. This enables your go-to-market (GTM) teams to leverage intelligence at scale for a wide range of purposes, e.g., target high-LTV audiences, personalised CRM strategies, automated sales workflows. There are two tools we currently recommend for this part of the data stack: Census and Hightouch.
Orchestration
An orchestrator is a tool that is not present in all data stacks. Many setups use multiple systems that are not directly connected to each other. For example, you can have an EL tool like Fivetran extracting data and storing it in your warehouse, and a modelling system like dbt using dbt Cloud, both of which manage their own execution schedules.
An orchestrator becomes key when you require custom extraction, as it can provide a single pane of glass to trigger, monitor and debug all tasks in your pipeline, while serving as the baseline for custom code to do extraction or data science.
Bringing Your Data Stack To Life
We hope this article gives you a good high-level overview of the different components of a typical modern data stack and how they interact with each other. Depending on your unique business model and data needs, there could be additional layers required in your stack. If you have questions, please feel free to reach out. We are always happy to share our impartial advice!