Message Queuing in Modern Systems
David Shergilashvili
Enterprise Architect & Software Engineering Leader | Cloud-Native, AI/ML & DevOps Expert | Driving Blockchain & Emerging Tech Innovation | Future CTO
In modern distributed systems, message queuing plays a fundamental role in ensuring reliable, scalable, and decoupled communication between different services. Whether handling financial transactions, managing large-scale event processing, or ensuring real-time data flow, message queues provide essential infrastructure for system resilience.
Building a scalable authorization system: a step-by-step blueprint (6 key requirements all authorization layers should include to avoid technical debt)
Authorization can make or break your application’s security and scalability. From managing dynamic permissions to implementing fine-grained access controls, the challenges grow as your requirements and users scale. This ebook is based on insights from 500+ interviews with engineers and IAM leads. It explores over 20 technologies and approaches, providing practical guidance to design a future-proof authorization system. Learn how to create a solution that evolves with your business needs while avoiding technical debt.
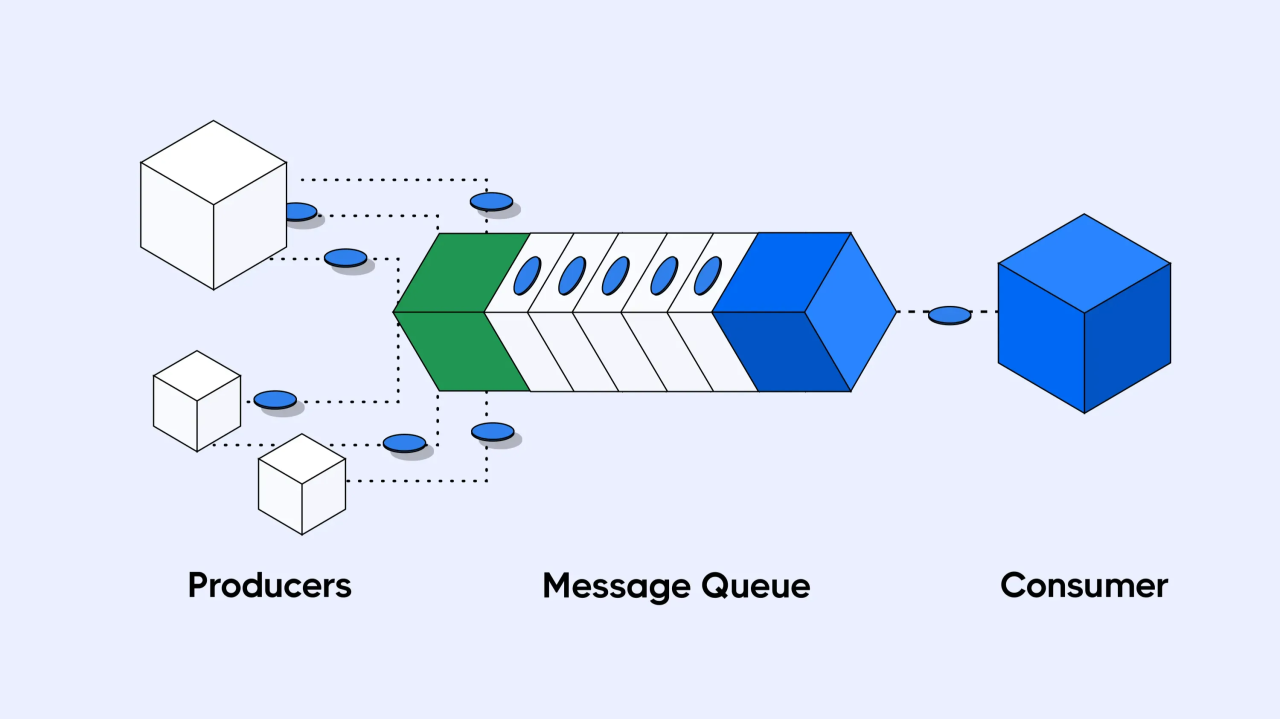
The Role of Message Queuing in Distributed Systems
Message queuing allows asynchronous communication between system components, enabling scalable and fault-tolerant architectures. Consider the following scenarios:
These applications require:
Traditional synchronous approaches struggle with these challenges, making message queuing a preferred solution in event-driven architectures.
Comparing Message Queuing Solutions
Several message queuing systems exist, each suited to different use cases:
When to Choose Which
Handling Scale with Event Buffering
The Challenge of Scale
Consider a payment processing system that typically handles 100 transactions per minute but spikes to 10,000 per minute during a flash sale. The system must efficiently process these peaks without overwhelming backend services.
The Solution: Event Buffering
Message queues act as buffers, absorbing spikes and distributing the load across multiple consumers. This prevents system failures due to sudden surges in traffic.
Example Implementation:
Normal Operation:
→ [Payment Events] → [Processing Service] → [Confirmation]
Peak Operation with Queues:
→ [Payment Events] → [Queue Buffer] → [Multiple Processing Services] → [Confirmation]
Using Kafka, RabbitMQ, or Amazon SQS, the system can handle 100x normal load by distributing workload efficiently.
Ensuring Reliable Delivery with Dead Letter Queues (DLQ)
The Reality of Failures
Failures are inevitable in distributed systems. Examples include:
Strategies for Handling Message Failures
1. Intelligent Retry Mechanisms
领英推荐
2. Dead Letter Queue (DLQ) Management
When retries are exhausted, messages move to a Dead Letter Queue for later inspection and manual or automated resolution.
Best Practices for DLQ Handling:
Alternative Failure Handling Strategies
Preserving Message Ordering in Distributed Systems
Why Ordering Matters
Message order is critical in scenarios like:
Ordering Strategies
1. Strict Ordering Guarantees
2. Partial Ordering for Scalable Systems
Managing System Stability with Backpressure
Understanding Backpressure
Backpressure prevents system overload. A sudden influx of messages could:
Backpressure Management Strategies
1. Early Detection
2. Adaptive Load Management
Security Considerations for Message Queues
Message queues must be secured to prevent unauthorized access and data breaches, especially in financial applications.
Conclusion: Best Practices for Message Queuing
Use event-driven architecture for handling high-volume workloads
Implement DLQs to track and resolve failed messages
Ensure message ordering where necessary using partitions and transaction guarantees
Apply backpressure mechanisms to prevent system overload
Monitor queue health with real-time observability tools
Secure message queues using authentication, encryption, and access controls
There is no one-size-fits-all solution for message queuing. The right approach depends on system requirements, failure tolerance, and scalability needs. A well-designed queuing system not only ensures smooth operation but also enables future growth and adaptability.