Mastering LLM Inference: Cost-Efficiency and Performance
Victor Holmin, CEng, MIET
Engineer | Architect | Consultant – AI & Data Strategy | AI Ecosystems & Platforms | Agentic AI | Accelerated Computing | Cybersecurity - Innovation & New Product Development | Product Management
Just a couple of weeks ago, I kicked off a series of articles examining lessons learned from organizations generating ROI from their LLM-powered applications at scale in the enterprise. In the first article, we broke down the foundational components of these applications, key design choices, and the economic factors that influence their success. The second article highlighted the critical role of evaluations as a strategic tool to safeguard investments and ensure long-term value.
This week, I’ll look into a sub-component that is often misunderstood yet integral to achieving a sustainable ROI: managing inference costs. While training LLMs tends to get the spotlight, inference (the process of generating outputs in response to user inputs) represents an ongoing expense that directly impacts total cost of ownership (TCO). Inference costs are deeply intertwined with your ability to scale, sustainably, and ultimately with the overall financial viability of GenAI deployments.
Far from being a static line item, inference costs reflect broader strategic choices about customer experience, resource utilization, architecture design, and deployment strategies. These costs intersect with other critical costs, such as fine-tuning, prompt engineering, cloud hosting, and talent acquisition. Without careful planning, inference costs can escalate, turning what should be a high-value investment into a financial burden.
While the cost of AI infrastructure is generally decreasing, it's important to recognize that inference costs are more nuanced than they might appear. These costs can significantly impact the overall ROI of your LLM application, especially as usage scales. To effectively manage and optimize these expenses, it's essential to understand the factors that drive them. In this article, we'll explore the hidden challenges that can inflate inference costs and outline practical strategies to ensure your LLM deployments are both, achieving your goals and being cost-effective.
A Quick Look at LLM Inference
At the heart of any LLM-powered application, as the name suggests, are Large Language Models (LLMs).?This is where a significant part of the value is generated in the system.
While training LLMs requires a significant upfront investment, a significant cost driver often lies in inference, the process of actually using the model to generate responses. Every time someone interacts with the LLM, it incurs a cost, and these expenses can quickly add up, especially for businesses dealing with high volumes of requests. This ongoing operational cost makes inference optimization essential for scaling AI solutions in a cost effective manner.
Inference optimization is about balancing cost, speed, and resource utilization to align with business goals. That’s why getting a good grasp of how LLM inference works under the hood?and making informed design choices can significantly impact your bottom line. To understand how to optimize inference, let's first take a closer look at what it actually involves.
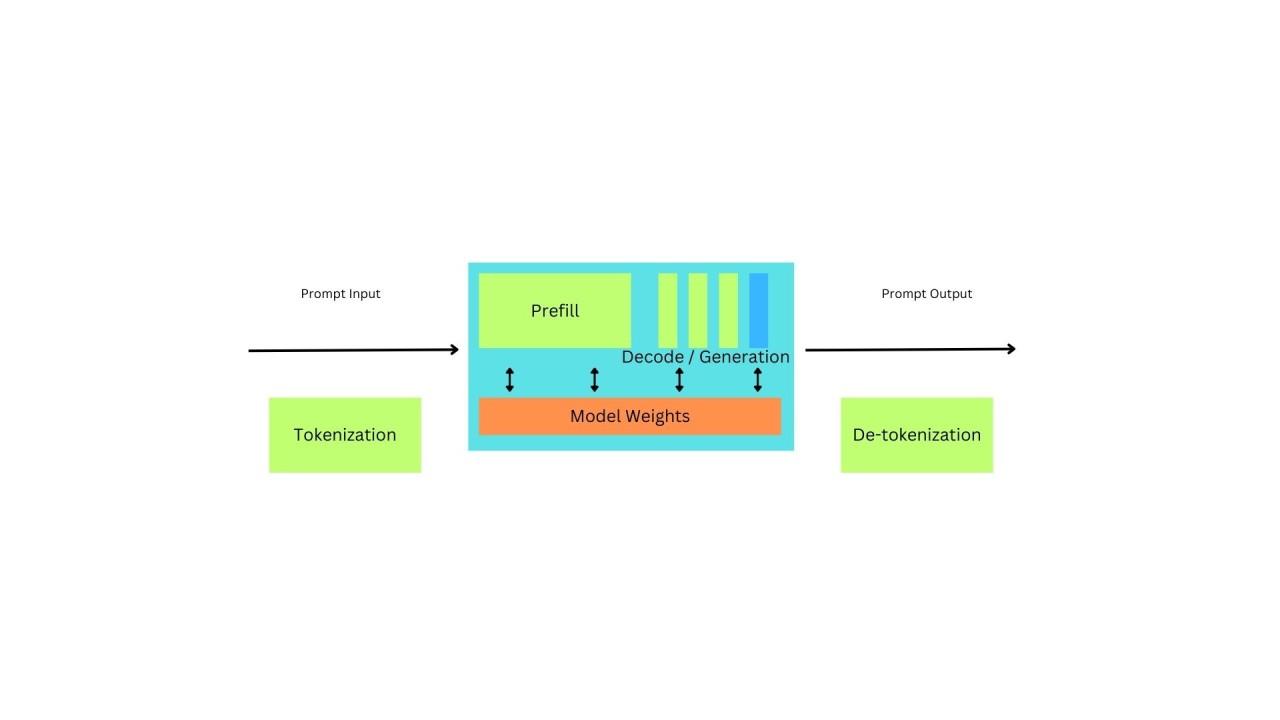
What Exactly Is LLM Inference?
Simply put, inference is the process of extracting meaningful output from an LLM based on user input. Unlike human conversations that occur in natural language, LLMs handle information in a structured, mathematical way. For every query, the model predicts and generates tokens (pieces of text equivalent) one at a time, building up the response step by step. Each token is essentially a piece of the puzzle, and generating these pieces depends on both the input and the tokens already generated.
This iterative, step by step approach is what makes LLMs feel intelligent but it also explains why inference can be computationally expensive and time-consuming.
LLM inference happens in two main phases:
Understanding these phases not only clarifies why inference can be resource-intensive but also highlights where businesses can focus their optimization efforts to maximize ROI.
The Importance of Optimizing LLM Inference
Strategic and Economic Impacts
Every design choice in an LLM deployment carries a cost. Poor optimization can lead to ballooning operational expenses, particularly in high-volume environments. For instance:
From a strategic perspective, inference optimization enables businesses to scale AI deployments without sacrificing profitability. It’s not just about getting a model up and running, it’s about making conscious choices to ensure that costs align with business objectives while delivering seamless user experiences.
Key Performance Metrics
To identify optimization opportunities, it's important to understand and track these metrics:
?
Notable Challenges in LLM Inference and Design Choices
Challenge 1: Memory Bottlenecks
LLMs (specially the very large ones) have significant memory requirements, which can strain GPU resources and inflate costs. This memory usage primarily comes from two elements:
Model Weights:?These parameters define the model's structure and behavior. For instance, one of the versions of a relatively old model like LLaMA-3 with 70 billion parameters requires approximately 140GB of GPU memory in FP16 precision.
KV Caching:?During the decode phase, the intermediate computations are stored as Key-Value (KV) tensors, and they grow linearly with the input and output sequence lengths. Long-context queries (e.g. processing a large document) exacerbate this issue, further increasing memory demands.
Design Choices to Mitigate Memory Bottlenecks
Economic Impact:?You can fit larger models or handle bigger workloads with the same hardware, reducing the need for expensive GPU upgrades.
Economic Impact:?Reduces the cost of processing long-context queries and allows larger batch sizes without additional GPU resources.
Economic Impact:?Achieves cost savings while maintaining performance for specific use cases.
?
Challenge 2: Latency Bottlenecks
As we discussed earlier, the decode phase of LLM inference (where tokens are generated sequentially) often results in underutilized GPUs. This sequential process, where each token depends on the previous ones, makes it more about memory access than raw computational power. This leads to increased latency, especially when you need long outputs.
Design Choices to Mitigate Latency Bottlenecks
Economic Impact:?Reduces time-to-completion for token generation, decreasing latency-related costs without requiring additional hardware.
- Pipeline Parallelism:?Splits the model across GPUs to process different layers simultaneously.
- Tensor Parallelism:?Distributes computations within a layer, such as dividing attention heads across GPUs.
- Sequence Parallelism:?Partitions sequence-based operations like LayerNorm across devices.
Economic Impact:?You get better GPU utilization, reducing the cost per query by processing more tokens in less time.
Economic Impact:?Lowers latency while maximizing GPU throughput.
?
Challenge 3: Dynamic Workloads
LLMs need to handle diverse queries, ranging from short inputs requiring brief outputs to complex, long-context queries. These varying workloads can lead to inefficiencies in batching:
Design Choices to Address Dynamic Workloads
Economic Impact:?Maximizes throughput, reducing the per-query cost and making GPU utilization more predictable.
Economic Impact:?Reduces idle resources during low traffic and prevents delays during peak usage.
Economic Impact:?Balances cost and performance by matching resource requirements to query complexity.
Summary of Challenges and Solutions
It's important to remember that these challenges are all interconnected. Memory bottlenecks, for example, directly impact hardware and memory costs. Latency issues affect energy consumption, and workload variability influences operational costs. By understanding these relationships, you can prioritize the optimizations that give you the best return on your investment.
The Real Costs of Inference Inefficiencies: Seeing is Believing
When deploying large language models (LLMs) at scale, it’s easy to focus on theoretical cost models or generalized optimization strategies. However, the real impact of inefficiencies, can have significant financial and operational consequences.
This section bridges the gap between abstract discussions and real-world applications by presenting practical scenarios. These examples demonstrate how common inefficiencies inflate costs and how targeted strategies—such as dynamic batching, speculative inference, and KV cache management—can drive substantial savings. Whether you’re optimizing latency-sensitive applications, memory-heavy workloads, or managing seasonal traffic surges, these scenarios highlight the financial and operational trade-offs involved in ensuring your LLM deployments are both scalable and cost-effective.
Note that these are illustrative examples and that actual GPU costs can vary.
领英推荐
Scenario 1: The Cost of GPU Sub-Utilization
Context: Imagine a team running an LLM-powered customer support chatbot on a single?NVIDIA A100 GPU, capable of handling?16 queries per second (QPS). Due to inefficient batching or workload distribution, the system only utilizes?50% of the GPU’s capacity. Sub-utilization like this often occurs because of unpredictable query patterns or poorly implemented batching strategies.
Assumptions:
Impact:
By running at half capacity, the team effectively?doubles their cost per query, significantly reducing ROI.
Optimization Strategy:
Outcome: Increasing GPU utilization to 80% reduces the cost per query to $0.195, delivering a?38% cost savings?while improving scalability.
Scenario 2: The Impact of Delays on Time-Sensitive Applications
Context: A business deploying a real-time transcription service faces delays due to?sequential token generation?during the decode phase. Latency-sensitive applications like transcription rely on real-time processing to maintain user engagement and ensure accuracy, making delays a significant challenge.
?
Assumptions:
Impact:
Optimization Strategy:
Outcome: By reducing latency to 2 seconds/query, the business avoids provisioning extra GPUs, maintaining a single GPU cost of $2.50/hour and saving?$2.50/hour?(or $1,825 annually).
Scenario 3: The Cost of Long-Context Queries
Context: A company uses an LLM to summarize lengthy legal documents. These?long-context queries?require significantly more memory for?KV caching, driving up GPU memory costs and impacting throughput. This challenge is common in use cases like?legal, research, or retrieval-augmented generation (RAG)?systems.
Assumptions:
Impact:
Optimization Strategy:
Outcome: By optimizing KV cache management, the batch size increases to 8 queries. The new cost per query drops to:
This represents a?50% cost reduction?while improving throughput.
?
Scenario 4: Seasonal Traffic Variability
Context: An e-commerce platform uses an LLM for?personalized product recommendations. Traffic surges during seasonal events like Black Friday lead to?resource under-provisioning, causing latency spikes and poor user experience.
Assumptions:
Impact:
Optimization Strategy:
To identify which queries are best suited for smaller models, analyze your workload and categorize queries based on complexity and resource requirements. Simple tasks like answering FAQs or generating short responses can often be handled by smaller, more efficient models, while complex tasks requiring deeper analysis or long-form content generation may require the larger LLM.
Outcome: By dynamically scaling to 3 GPUs during peak traffic (instead of 4), and deploying smaller models for 50% of queries, the business reduces peak costs from $10/hour to $7.50/hour, which comes to a?25% reduction in peak expenses.
?
Scenario 5: Latency vs. Cost Trade-Offs
Context: A financial services firm offers real-time fraud detection using an LLM. The system requires?high precision?to minimize false positives and must respond within a strict?1-second latency window?to prevent losses.
Assumptions:
Impact:
Optimization Strategy:
Outcome: Latency now falls below 1 second, eliminating the need for a second GPU. Costs remain at $3/hour, representing a?50% savings?without sacrificing quality.
Key Takeaways: The Strategic Case for Optimization
Optimizing LLM inference is not merely a technical detail, is a strategic design choice for achieving cost-effective and scalable deployments. Getting the models to work efficiently and cost-effectively can be tricky. It's not just about throwing more GPUs at the problem. It's about being smart with how we use our resources. This article has shown you how tackling those common challenges like keeping your GPUs busy, speeding up those responses, and handling those unpredictable traffic spikes can make a?huge?difference in both cost and performance and ultimately on your ROI.