Low-Cost LLM and Semantic Clustering for Generating High-Quality and Relevant Search Queries with LangChain
David García Broto
Senior AI/ML Data Scientist | Engineer & Researcher | Entrepreneur (2x) | Generative AI
When working with AI agents—such as large language models (LLMs) orchestrated by LangChain—it’s often necessary to generate search queries that gather real-time data from across the web via Tavily’s Search API. This capability proves especially useful in scenarios such as:
In this article, we’ll explore how to generate multiple search queries using a low-cost LLM, apply an iterative process to identify the most statistically prevalent ones, and then use semantic clustering to narrow them down to the most meaningful subset for a given topic. This approach can yield powerful results even with a small model, because iteration and semantic clustering add layers of intelligence that go beyond what a basic model alone can deliver.
I’ll provide code snippets and detailed explanations to guide you through each step.
Let’s dive in!
Table of Contents
Setup
This article assumes you’re a Python developer with basic experience in LLMs and LangChain. I use PyCharm, but feel free to work in any IDE you prefer.
First, let’s define some environment variables in a .env file:
OPENAI_API_KEY=<Your OpenAI API Key>
LANGCHAIN_TRACING_V2=true
LANGCHAIN_ENDPOINT=https://eu.api.smith.langchain.com
LANGCHAIN_API_KEY=<Your LangChain API Key>
LANGCHAIN_PROJECT=<Your Project Name>
OPENAI_API_KEY authenticates your requests to OpenAI’s API, allowing you to use GPT models and other OpenAI services.
LANGCHAIN variables configure the application to use LangChain’s services, such as tracing, authentication, and project organization.
Treat these variables as sensitive information and avoid committing them to version control. You can load them in your application with:
from dotenv import load_dotenv
load_dotenv()
Chains
We define two LangChain chains.
Research Queries Chain
This chain creates a structured prompt that directs an LLM to generate a list of search queries covering multiple perspectives on a given topic.
First, we define a custom Pydantic model specifying the output format as a list of queries:
class ResearchQueries(BaseModel):
"""
Pydantic model for a list of queries that can be used to investigate a topic
from multiple angles.
"""
queries: List[str] = Field(
description="A list of comprehensive search queries for investigating the given topic."
)
Then, we create a method that builds the chain and invokes the LLM:
def get_research_queries(topic: str, num_queries: int, llm):
"""
Produce a list of 'num_queries' search queries that thoroughly investigate a topic
from multiple angles and perspectives.
"""
structured_llm = llm.with_structured_output(ResearchQueries)
prompt = ChatPromptTemplate(
[
SystemMessagePromptTemplate.from_template(
"You are a thorough research assistant. "
"Provide a set of queries that cover multiple angles of a given topic. "
"The queries should allow the user to explore the topic from various perspectives, "
"including background information, current trends, controversies, major players, etc. "
"Focus on a broad yet in-depth approach."
),
HumanMessagePromptTemplate.from_template(
"""Given the topic "{topic}", produce {num_queries} queries that a user could
use to thoroughly investigate this topic from multiple angles and gain a
comprehensive understanding of it.
List only the queries themselves without additional commentary or explanations."""
),
],
)
chain = prompt | structured_llm
return chain.invoke(
{
"topic": topic,
"num_queries": num_queries,
}
)
Representative Query Chain
This new chain also uses a structured prompt. It takes an existing list of queries and uses an LLM to produce a single representative query that succinctly represents the core idea shared among multiple inputs.
We start by defining a helper function, calculate_dynamic_word_limit, which sets an upper bound on the length of the final representative query. It calculates the maximum word count among the given queries and adds a buffer percentage (e.g., 20%). This ensures our final query remains concise while allowing for slight variations in wording:
def calculate_dynamic_word_limit(queries: list[str], extra_pct: float = 0.2) -> int:
"""
Returns an integer representing a dynamic word cap.
For example, the max word count of any query * (1 + extra_pct).
"""
if not queries:
return 20 # fallback if no queries
max_words = max(len(q.split()) for q in queries)
limit = int(max_words * (1 + extra_pct))
return max(limit, 1) # ensure at least 1
Secondly, we create a Pydantic model, RepresentativeQuery, with a single field called representative_query. By pairing this model with llm.with_structured_output(RepresentativeQuery), we ensure that the chain’s output is consistently formatted as one unified query string:
class RepresentativeQuery(BaseModel):
representative_query: str = Field(
description="A single best representative query that captures the essence of the input queries."
)
Finally, we create a method that builds the chain and invokes the LLM:
def get_representative_query(queries: list[str], llm):
"""
Given a list of queries, return the single most representative query.
If there is exactly one query, return it directly (no LLM call).
Otherwise, use the LLM to produce a single best representative query.
"""
if len(queries) == 1:
return queries[0]
queries_text = "\n".join(f"- {q}" for q in queries)
word_limit = calculate_dynamic_word_limit(queries)
structured_llm = llm.with_structured_output(RepresentativeQuery)
prompt = ChatPromptTemplate(
[
SystemMessagePromptTemplate.from_template(
"You are a skilled language assistant that creates a concise, unified query "
"from a list of related queries. Your goal is to capture the essence of the "
"majority of these queries in a single question or prompt. If any queries "
"are outliers or tangential, you may ignore them. The result must be short "
"and reflect their shared meaning."
),
HumanMessagePromptTemplate.from_template(
"""Here is a list of queries:
{queries_text}
Please produce a single concise query (**no more than {word_limit} words**)
that best represents the common theme or intent of these queries.
If some queries seem off-topic compared to the majority, ignore them.
Output only the resulting query text, with no extra commentary.
"""
),
],
)
chain = prompt | structured_llm
result = chain.invoke({
"queries_text": queries_text,
"word_limit": word_limit,
})
return result.representative_query
LLMs
Now that we have our chains defined, let’s set up the models we’ll use:
DEFAULT_MODEL = "gpt-4o-mini"
DEFAULT_MAX_TOKENS = 2048
DEFAULT_TEMPERATURE = 0.1
def get_chat_open_ai(
model=DEFAULT_MODEL,
max_tokens=DEFAULT_MAX_TOKENS,
temperature=DEFAULT_TEMPERATURE
):
return ChatOpenAI(
model=model,
max_tokens=max_tokens,
temperature=temperature
)
llm = get_chat_open_ai(max_tokens=3072, temperature=0.3)
llm_0 = get_chat_open_ai(temperature=0)
llm will be used for generating the search queries. This moderate temperature introduces a bit of creativity and variety to the generated queries, which is helpful for exploring a topic from multiple angles without deviating too far from factual accuracy. Typically, temperatures between 0.1 and 0.3 are used when you want outputs that stay relatively on-topic but can still offer some variation.
llm_0 will be used for consolidating a cluster of similar queries into a single representative query. Its temperature of 0 yields deterministic outputs, ensuring minimal randomness. This is ideal for tasks like summarizing or unifying existing content where consistency and precision are more important than creativity.
By fine-tuning the temperature parameter in each scenario, we can balance creativity where it’s needed (generating broader search queries) and reliability where it’s crucial (merging queries into a concise and accurate representative prompt).
Please note that we’ve selected gpt-4o-mini as our model, which belongs to the smaller and more cost-effective range of available OpenAI models. Despite its modest size, we’ll demonstrate how iteration and semantic clustering can still yield high-quality, relevant queries.
Iterations
With our chains and LLMs set up, let’s move on to the application logic.
Imagine we want to use an LLM to generate NUM_QUERIES different queries for researching a given TOPIC. Later, we might use these queries with an external service, such as Tavily Search API, to collect information from the internet.
If we simply asked the LLM for a set of queries once, we’d get results—but are those queries guaranteed to be the most relevant or important? Could there be more crucial queries the LLM didn’t produce? Did it return any niche or tangential queries that might not be useful?
We address these issues with an iteration and semantic clustering process. For the first step (iteration), instead of calling the chain just once, we call it NUM_REPETITIONS times and accumulate the generated queries in a search_queries list:
领英推荐
TOPIC = "Himalaya mountaineering"
NUM_QUERIES = 10
NUM_REPETITIONS = 50
search_queries = []
for _ in tqdm(range(NUM_REPETITIONS)):
response = get_research_queries(TOPIC, NUM_QUERIES, llm)
for query in response.queries:
search_queries.append(query)
By repeating the process multiple times, we collect a broader set of queries, which lays the groundwork for our semantic clustering step.
Create Embeddings
If we ask the model once to generate NUM_QUERIES search queries, it’s likely smart enough to give us distinct suggestions. However, if we request NUM_REPETITIONS rounds of queries without providing previous answers as context, some will be new while others may repeat in slightly different wording. Over many iterations, the most important and typical queries will appear more frequently than niche or tangential ones—or those that are just random hallucinations.
Our rationale is that by clustering these search_queries semantically, the most essential queries will form large clusters of similar meaning, and each cluster should differ in focus. Meanwhile, tangential or hallucinatory queries will likely end up in very small clusters of one or two elements at most.
Therefore, semantic clustering will give us a set of meaningful, relevant queries that differ from each other, while filtering out LLM “noise” and hallucinations.
To perform semantic clustering, we calculate embeddings for each query and then use those vector representations for clustering:
DEFAULT_MODEL = "text-embedding-3-large"
DEFAULT_DIMENSIONS = 3072
def get_embeddings_open_ai(model=DEFAULT_MODEL, dimensions=DEFAULT_DIMENSIONS):
return OpenAIEmbeddings(model=model, dimensions=dimensions)
embeddings_model = get_embeddings_open_ai(dimensions=3072)
embeddings = []
for query in tqdm(search_queries):
vector = embeddings_model.embed_query(query)
embeddings.append(vector)
This gives us a list of embedding vectors that we can feed into a clustering algorithm in the next step.
Semantic Clustering
Now we reach the most interesting part. The embeddings list contains vector representations of our search queries in a multidimensional space, where closer vectors typically represent closer meanings. To turn these vectors into meaningful clusters, we can use a classic clustering algorithm like KMeans.
Here’s how we do it:
N_CLUSTERS = 10
MIN_CLUSTER_SIZE = int(NUM_REPETITIONS * 0.1)
X = np.array(embeddings)
kmeans = KMeans(n_clusters=N_CLUSTERS, random_state=42)
kmeans.fit(X)
labels = kmeans.labels_
cluster_centers = kmeans.cluster_centers_
clusters_info = []
for cluster_id in range(N_CLUSTERS):
cluster_indices = np.where(labels == cluster_id)[0]
if len(cluster_indices) == 0:
rep_query = "No queries in this cluster"
rep_query_llm = rep_query
queries = []
else:
distances = np.linalg.norm(X[cluster_indices] - cluster_centers[cluster_id], axis=1)
nearest_idx = cluster_indices[np.argmin(distances)]
rep_query = search_queries[nearest_idx]
queries = [search_queries[i] for i in cluster_indices]
rep_query_llm = get_representative_query(queries, llm_0)
clusters_info.append({
"cluster_id": cluster_id,
"size": len(cluster_indices),
"representative_query": rep_query,
"representative_query_llm": rep_query_llm,
"queries": queries
})
The result is a list of cluster metadata. Key points include:
By inspecting clusters_info, we can verify several important aspects:
Sorting and Filtering
Before inspecting the final results, let's perform some post-processing. We will sort the clusters in descending order by size, prioritizing the most relevant clusters first. Additionally, we will filter out clusters that do not meet the minimum cluster size, thereby eliminating irrelevant clusters or hallucinations:
# Sort the clusters by size in descending order
clusters_info_sorted = sorted(clusters_info, key=lambda x: x["size"], reverse=True)
# Filter out the clusters by MIN_CLUSTER_SIZE
clusters_info_sorted = [c for c in clusters_info_sorted if c["size"] >= MIN_CLUSTER_SIZE]
# Print LLM representative queries
for c in clusters_info_sorted:
print(f"Cluster {c['cluster_id']} (size={c['size']}): {c['representative_query_llm']}")
# Convert to JSON and print with indentation
json_output = json.dumps(clusters_info_sorted, indent=4)
print(json_output)
Resulting Search Queries
Here are the final search queries produced by our code, sorted in descending order of cluster size (the number in brackets indicates the cluster size at the end of each query):
As you can see, the queries are relevant and varied. The iteration and clustering process leverages the model’s underlying knowledge base to quantify query relevance by cluster size. If we were to use these queries with the Tavily Search API next, we could be confident that our search queries thoroughly explore the topic from multiple perspectives.
Detailed Inspection of Clusters
Below is a snapshot of the detailed cluster output. For simplicity, only five queries per cluster are shown:
[
{
"cluster_id": 5,
"size": 63,
"representative_query": "What are the risks and challenges faced by climbers in the Himalayas?",
"representative_query_llm": "What are the risks and challenges of climbing in the Himalayas?",
"queries": [
"What are the safety risks and challenges faced by climbers in the Himalayas?",
"What are the challenges and risks associated with climbing in the Himalayas?",
"What are the challenges and dangers faced by climbers in the Himalayas?",
"What are the health risks associated with high-altitude climbing in the Himalayas?",
"What are the risks and challenges faced by climbers in the Himalayas?",
...
]
},
{
"cluster_id": 4,
"size": 60,
"representative_query": "What are the environmental impacts of mountaineering in the Himalayas?",
"representative_query_llm": "What are the environmental impacts of mountaineering and climate change in the Himalayas?",
"queries": [
"What are the environmental impacts of mountaineering in the Himalayas?",
"How has climate change affected the conditions for mountaineering in the Himalayas?",
"What impact does climate change have on the Himalayan climbing environment?",
"How do climate change and glacial melting affect mountaineering in the Himalayas?",
"What are the environmental impacts of mountaineering in the Himalayas?",
...
]
},
{
"cluster_id": 8,
"size": 54,
"representative_query": "What role do local communities play in Himalayan mountaineering?",
"representative_query_llm": "What role do local communities and cultures play in Himalayan mountaineering?",
"queries": [
"What role do local communities play in Himalayan mountaineering?",
"How do cultural and local communities perceive mountaineering in the Himalayas?",
"What is the cultural significance of the Himalayas to local communities and climbers?",
"What are the cultural and spiritual significance of the Himalayas to local communities?",
"How do local communities perceive and interact with mountaineering tourism in the Himalayas?",
...
]
},
{
"cluster_id": 1,
"size": 52,
"representative_query": "What are the current trends in Himalayan mountaineering expeditions?",
"representative_query_llm": "What are the current trends in Himalayan mountaineering expeditions?",
"queries": [
"What are the current trends in Himalayan mountaineering expeditions?",
"What are the current trends in Himalayan mountaineering, including popular expeditions?",
"Current trends in Himalayan mountaineering expeditions",
"Current trends in Himalayan trekking and mountaineering tourism",
"What are the current trends and advancements in Himalayan mountaineering gear and technology?",
...
]
},
{
"cluster_id": 7,
"size": 51,
"representative_query": "Who are the most notable climbers and mountaineering organizations in the Himalayas?",
"representative_query_llm": "Who are the notable climbers and organizations in Himalayan mountaineering?",
"queries": [
"Who are the notable climbers and mountaineering organizations in the Himalayas?",
"Who are the prominent mountaineers and climbing teams in the Himalayas?",
"Who are the prominent figures and organizations in Himalayan mountaineering?",
"Who are the notable climbers and mountaineering organizations involved in Himalayan expeditions?",
"Who are the prominent climbers and mountaineering organizations in the Himalayas?",
...
]
},
{
"cluster_id": 0,
"size": 50,
"representative_query": "What are the controversies surrounding commercial expeditions in the Himalayas?",
"representative_query_llm": "What are the controversies surrounding commercialization and permits in Himalayan climbing?",
"queries": [
"What are the controversies surrounding commercial expeditions in the Himalayas?",
"What are the controversies surrounding permits and commercialization of Himalayan climbs?",
"What are the controversies surrounding permits and commercialization of Himalayan peaks?",
"What are the controversies surrounding permits and regulations for climbing in the Himalayas?",
"What are the ethical considerations and controversies surrounding Himalayan mountaineering?",
...
]
},
{
"cluster_id": 2,
"size": 50,
"representative_query": "What is the history of mountaineering in the Himalayas?",
"representative_query_llm": "What is the history of mountaineering in the Himalayas?",
"queries": [
"What is the history of mountaineering in the Himalayas?",
"History of mountaineering in the Himalayas",
"What is the history of mountaineering in the Himalayas?",
"History of mountaineering in the Himalayas",
"What is the history of mountaineering in the Himalayas?",
...
]
},
{
"cluster_id": 3,
"size": 50,
"representative_query": "What are the major peaks in the Himalayas and their climbing routes?",
"representative_query_llm": "What are the major peaks in the Himalayas and their climbing routes?",
"queries": [
"What are the major peaks in the Himalayas and their climbing routes?",
"Major peaks in the Himalayas and their climbing routes",
"Major peaks in the Himalayas and their climbing routes",
"What are the major peaks in the Himalayas and their climbing routes?",
"What are the most popular peaks to climb in the Himalayas and their difficulty levels?",
...
]
},
{
"cluster_id": 6,
"size": 44,
"representative_query": "How has technology influenced Himalayan mountaineering in recent years?",
"representative_query_llm": "How has technology impacted Himalayan mountaineering practices and approaches?",
"queries": [
"How has technology influenced Himalayan mountaineering in recent years?",
"How has technology changed the approach to climbing in the Himalayas?",
"How has technology changed the practice of mountaineering in the Himalayas?",
"Technological advancements in gear and equipment for Himalayan expeditions",
"How has technology changed the approach to Himalayan mountaineering?",
...
]
},
{
"cluster_id": 9,
"size": 26,
"representative_query": "What are the safety regulations and guidelines for climbing in the Himalayas?",
"representative_query_llm": "What are the regulations, safety measures, and training for climbing in the Himalayas?",
"queries": [
"What are the legal regulations and permits required for climbing in the Himalayas?",
"What are the safety regulations and guidelines for climbers in the Himalayas?",
"What safety measures and regulations are in place for mountaineering in the Himalayas?",
"What are the safety regulations and rescue operations in place for Himalayan mountaineering?",
"What are the training and preparation requirements for aspiring Himalayan climbers?",
...
]
}
]
You can see how each cluster neatly groups similar queries together, and each has a representative query generated both via the centroid approach and by an LLM-based method. By reviewing the representative_query, representative_query_llm, and queries fields—both within and across clusters—you can confirm the considerations we’ve explored throughout this article.
It’s impressive how LLMs, embeddings, and Machine Learning algorithms have evolved over the last few years to produce such coherent and meaningful groupings.
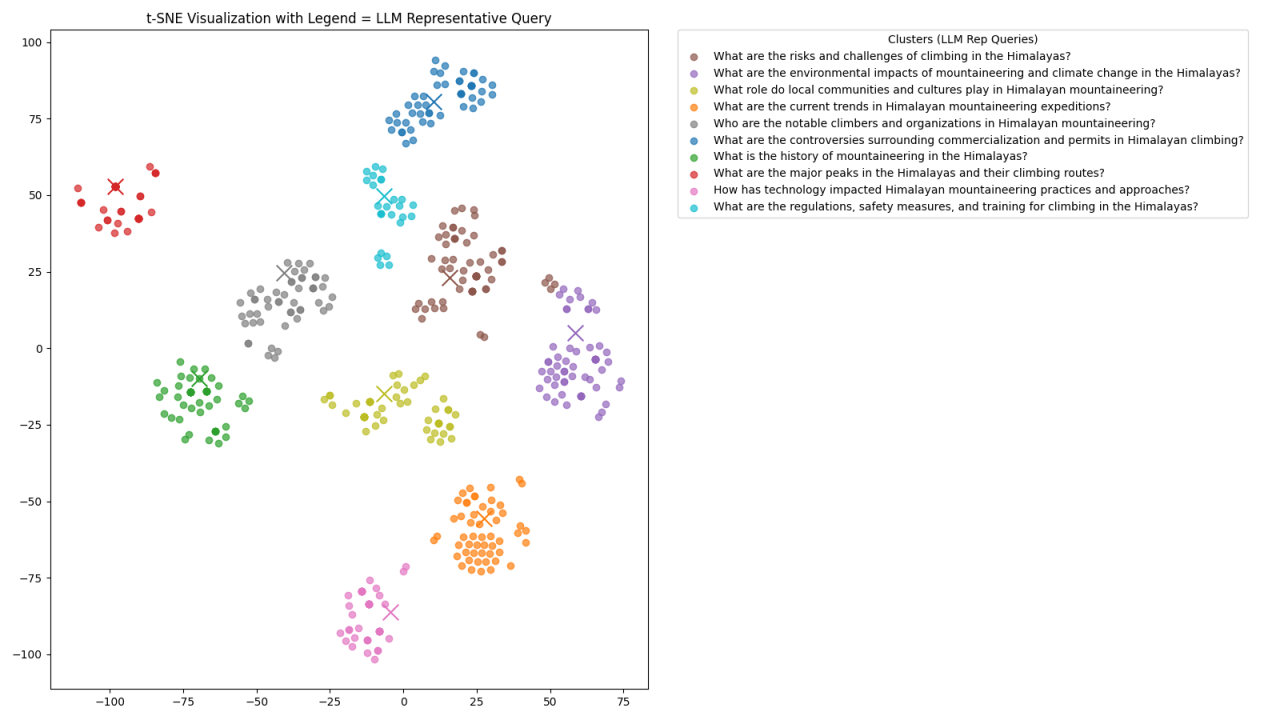
Visual Representation
As a bonus, we conducted a final experiment to visualize how our queries cluster semantically.
This visualization highlights how effectively our approach—combining iteration, embeddings, and semantic clustering—groups semantically similar queries. It’s a compelling demonstration of how even a smaller LLM, guided by careful iteration and clustering, can produce coherent, insightful groupings that are easily interpretable in a 2D plot.
Cost
Below are token counts and costs for running this experiment:
Total Estimated Cost:
The total was well under $0.01 for each service, demonstrating that even a multi-step process involving repeated queries and clustering can remain highly cost-effective.
Conclusions
In this article, we saw that repeatedly asking a low-cost LLM for search queries produces a broader set of potential questions, allowing even a smaller model to capture many angles and nuances of a topic. By embedding and clustering these queries, we can isolate the most relevant and frequently occurring ideas while discarding tangential or irrelevant ones—ultimately improving the quality of our final query list. Despite using multiple iterative steps, the token consumption and associated costs remain low. This demonstrates that smaller, budget-friendly models can still deliver high-quality, comprehensive search queries when combined with careful iteration, embeddings, and semantic clustering.