LeetCode System Design: A Deep Dive into Scalable Code Execution Platforms
Functional Requirements
Non-Functional Requirements
Basic Data Design
API Design
GET /api/problems/{problem_id}
Response:
{ "problem_id": int,
"title": string,
"description": string,
"difficulty": string
}
2.Submit Solution:
POST /api/submit Request:
{
"problem_id": int,
"code": string,
"language": string
} Response:
{
"submission_id": string
}
3.Check Submission Status:
GET /api/submissions/{submission_id}
Response:
{
"status": string,
"result": string,
"runtime": float,
"memory_usage": float
}
4.List Problems:
GET /api/problems?page={page_number}&limit={limit}
Response: {
"problems": [ { "problem_id": int, "title": string, "difficulty": string }, ... ],
"total_pages": int }
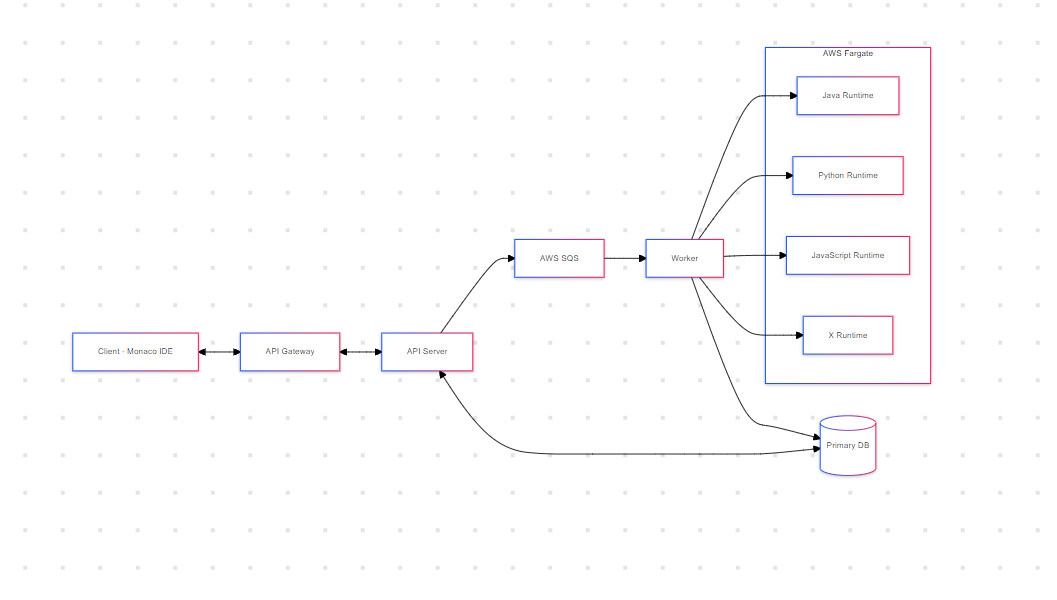
System Architecture and Flow
Now, let's dive into how the system actually works and why it's designed this way.
An API Gateway is like a smart receptionist for your system. It directs incoming requests to the right places, handles security checks, and can even do some basic request processing.
Application Servers These servers handle the core logic of the application. They process requests, interact with databases, and manage the overall flow of operations.
Here's where we encounter our first major design decision.
Why can't we just run user code directly on these servers?
The problem is with vertical scaling.
Vertical scaling means adding more power (CPU, RAM) to an existing server. It's like trying to make a car go faster by putting in a bigger engine.
While this can work up to a point, it has limitations:
There's a limit to how powerful a single machine can be It's expensive It doesn't provide isolation between different users' code This is where the concept of horizontal scaling comes in.
Horizontal scaling means adding more machines to your system instead of making one machine more powerful. It's like adding more cars to a delivery fleet instead of trying to make one car do all the deliveries.
In essence, the sheer amount of processing power needed makes it impossible to run a system like LeetCode on traditional servers. This is why they use cloud services, containerization, and distributed computing to handle the massive workload efficiently and cost-effectively.
领英推荐
To solve the problems of vertical scaling and provide necessary isolation, we use containerization. Let's break down the evolution of this approach: a.
Virtual Machines (VMs) Virtual Machines are like having several separate computers running inside your physical computer.
Each VM has its own operating system and resources.
Pros:
Good isolation Can run different operating systems
Cons: Heavy resource usage Slow to start up Inefficient for running small, short-lived processes (like code submissions)
b. Docker Containers
Docker containers are like lightweight, standardized boxes for your code and all its dependencies.
They're much lighter than VMs because they share the host system's kernel.
Pros: Lightweight and fast to start Efficient resource usage Consistent environment across different systems
Cons: Slightly less isolation than VMs (though still very good) Requires careful configuration for security
c. Amazon ECS (Elastic Container Service)
Amazon ECS is like a smart manager for your Docker containers.
It handles deploying containers, scaling them based on demand, and ensuring they're healthy.
Pros: Automated management of containers Easy scaling Integration with other AWS services Cons: Vendor lock-in to AWS Can be complex to set up initially ECS keeps track of container health through regular checks.
If a container becomes unresponsive or unhealthy, ECS can automatically replace it.
A queue system is like a buffer or waiting line for tasks.
When a user submits code, instead of running it immediately, we place it in a queue. This queue system allows for asynchronous processing.
Asynchronous means "not occurring at the same time". In our system, it means that the user doesn't have to wait for their code to finish running before getting a response.
Here's how it works: User submits code System immediately returns a submission ID Code is placed in the queue Worker processes pick up code from the queue and execute it Results are stored in the database User can check the status using the submission ID This approach has several benefits: Users get an immediate response The system can handle traffic spikes more easily We can prioritize certain tasks if needed
Putting It All Together
When a user submits code, here's what happens:
This architecture allows LeetCode to:
By leveraging technologies like Docker and AWS services, and using patterns like queuing and asynchronous processing, LeetCode creates a robust, scalable system capable of handling the demands of millions of users practicing coding problems every day.