Introduction to Random Forest
Omkar Sutar
Data Analyst | Power BI Expert | Power Automate Specialist | Python Aficionado
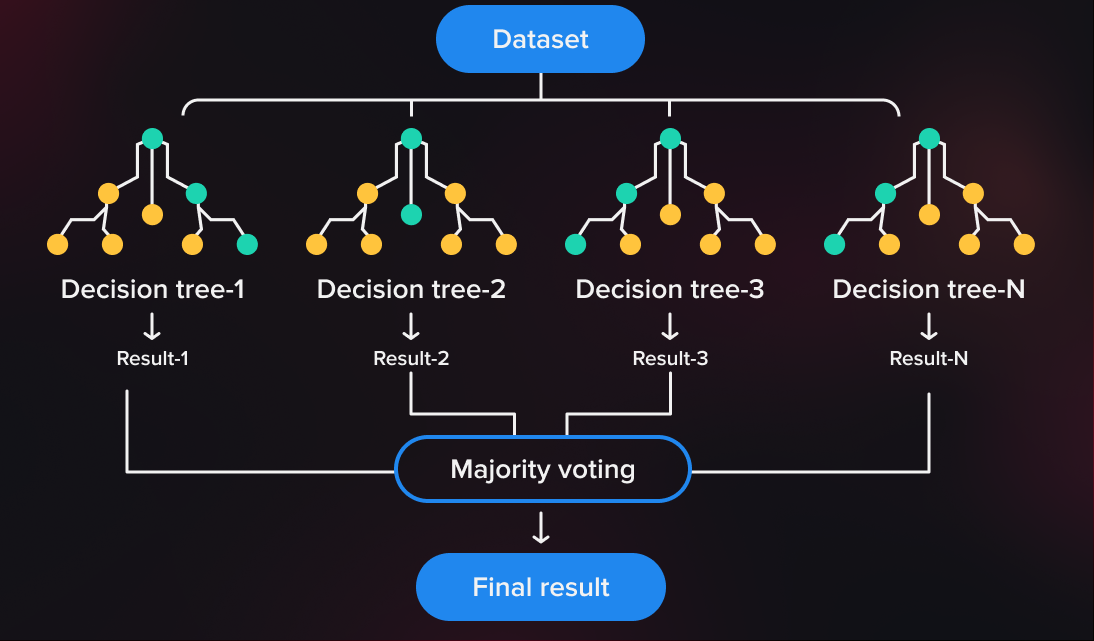
Random Forest is an ensemble learning method for classification, regression, and other tasks that operate by constructing a multitude of decision trees at training time and outputting the class or mean prediction of the individual trees. It is one of the most popular algorithms in machine learning and is used in a wide range of applications such as recommendation systems, fraud detection, and medical diagnosis.
The key idea behind Random Forest is to combine multiple decision trees, each trained on a different subset of the training data, in order to reduce overfitting and improve the accuracy of the predictions. In addition, Random Forest provides a measure of the importance of each feature in the data, which can be used for feature selection and interpretation.
we will implement Random Forest using Python and the scikit-learn library, one of the most popular machine-learning libraries in Python.
Implementation of Random Forest using Python
First, we will import the necessary libraries and load the dataset.
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
Next, we will split the dataset into training and testing sets using the train_test_split function from scikit-learn.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
领英推荐
Now, we can create an instance of the RandomForestClassifier class and fit it to the training data.
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X_train, y_train)
In this example, we are creating a Random Forest with 100 decision trees and setting the random_state parameter to 42 for reproducibility.
Once the Random Forest is trained, we can make predictions on the testing data and evaluate the performance of the model using various metrics such as accuracy, precision, recall, and F1-score.
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
y_pred = rf.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
print("Precision:", precision_score(y_test, y_pred, average='weighted'))
print("Recall:", recall_score(y_test, y_pred, average='weighted'))
print("F1-score:", f1_score(y_test, y_pred, average='weighted'))
In this example, we are using the weighted average of precision, recall, and F1-score to account for class imbalance in the data.
Conclusion
In this article, we have implemented the Random Forest algorithm using Python and the scikit-learn library. Random Forest is a powerful algorithm for.