How Slack Runs Cron Scripts Reliably At Scale
Cron jobs are scheduled tasks that run automatically on a server at specific times or intervals. They're often used to perform routine maintenance or automate repetitive tasks. For example, cron jobs can back up a database every night, generate reports at the end of the day, or clear out temporary files once a week.
Slack uses cron scripts to handle tasks like sending reminders, email delivery, and database cleaning. As the number of scripts and the data they processed grew, they sometimes didn't work reliably and became harder to manage. This made Slack realize they needed a better system to run these scripts more reliably and at a larger scale.
How it was before
When Slack first started running cron scripts, it was done straightforwardly. There was one server with all the scripts and a single crontab file that managed their schedules. This server was responsible for running the scripts as scheduled. As the number of scripts and the data they processed increased, Slack kept upgrading to bigger servers with more CPU and RAM to keep things working.
However, this setup wasn't very reliable. If anything went wrong with that one server, it could stop some key Slack functions from working. After repeatedly patching up the system, they decided it was time to build a new, more reliable, and scalable cron execution service.
The New System
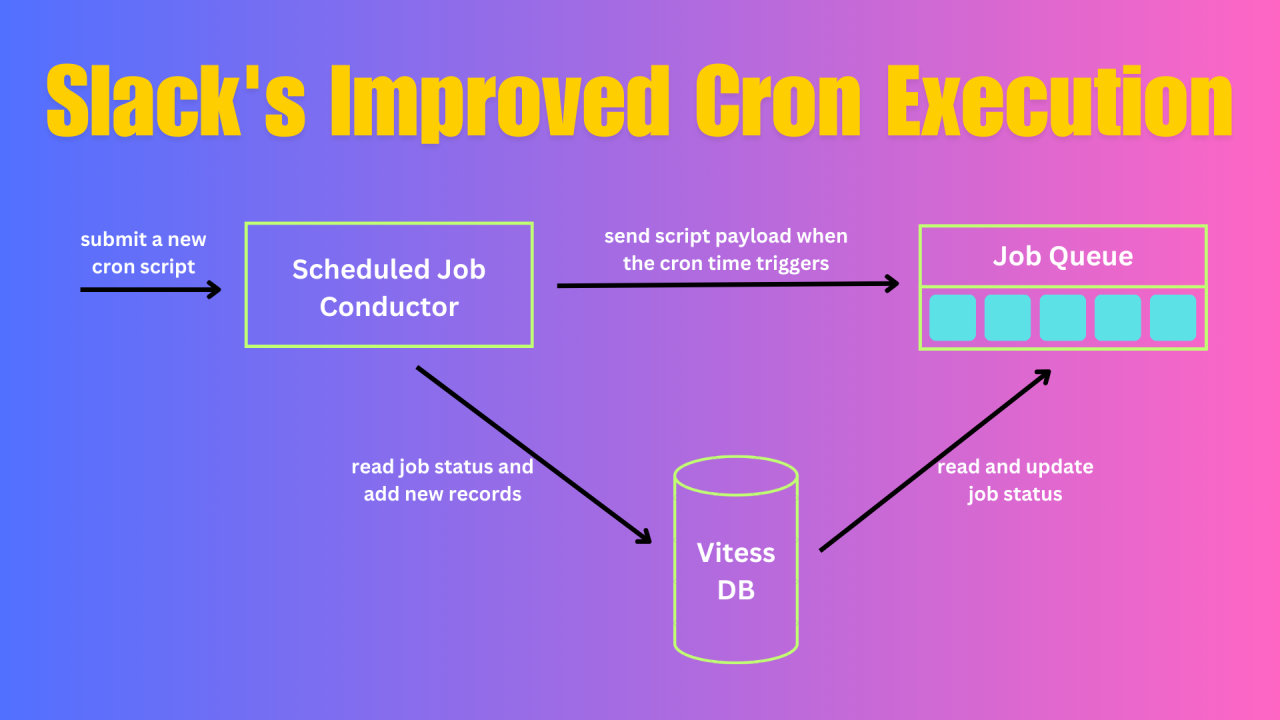
The new service has three main parts:
Scheduled Job Conductor
Slack used a Golang cron library with Bedrock, their Kubernetes-based system, to manage multiple pods. Kubernetes Leader Election selects one pod for scheduling, while others remain on standby. To ensure smooth transitions between pods, Slack avoids shutting down the active pod at the start of a new minute. This is important because cron jobs are often scheduled to run at the beginning of the minute, so they want to avoid disrupting this timing.
领英推荐
It might seem like using more pods to handle jobs would be better, as it would prevent a single point of failure and spread out the workload. However, Slack decided that keeping the pods synchronized would be too complicated. There are two reasons for this:
Job Queue
Slack’s Job Queue is a system that handles about 9 billion jobs each day. It works with a series of “queues” where jobs pass through. Jobs are moved through Kafka for long-term storage in case of problems or delays, then into Redis for short-term storage and extra details about who is running the job, and finally to a “job worker” — a node that actually runs the job. In this setup, each job is a single script. Although it’s an asynchronous system, it processes work very quickly when each job is handled separately.
Vitess Database Table
The Vitess table will handle duplicate job prevention and track job status by completing the new service. Their old cron system used a Linux tool called "flocks" to make sure only one copy of a script ran at a time. This usually worked, but for some scripts that take longer than their scheduled time, two copies could run at once. In the new system, each job run is recorded in a table, and the job’s status is updated as it progresses. This way, before starting a new job, the service can check the table to see if a job is already running. They use an index on script names to speed up these checks.
In summary, Slack's new system for running cron scripts is now more reliable, can handle more work, and is easier for users. Although the old crontab on a single server worked for a while, it began to cause problems and couldn’t keep up with Slack’s growth. The new system provides the flexibility Slack needs to expand both now and in the future.
References