LLMOps: Strategies for Building and Scaling Large Language Models
LLMOps, or Large Language Model Operations, is a rapidly emerging field that focuses on the development, deployment, and management of large language models (LLMs). As LLMs become increasingly integrated into various applications, there is a growing need for robust and scalable processes to ensure their effective and reliable operation. LLMOps encompasses a wide range of activities, including data preparation, model development and training, evaluation and testing, deployment, and ongoing monitoring and maintenance. By following best practices and leveraging the right tools, organizations can maximize the benefits of LLMs while mitigating potential risks.
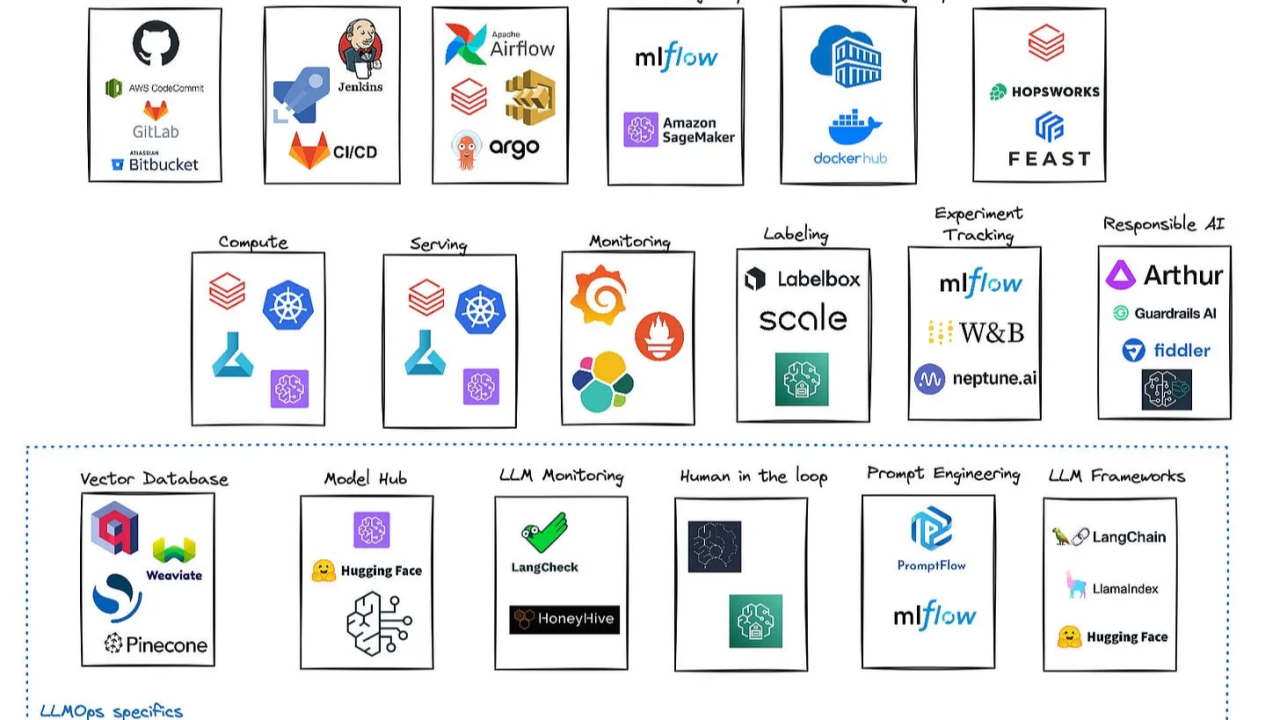
LLMOps Tools and Frameworks :
LLMOps encompasses three main phases: Continuous Integration (CI), Continuous Deployment (CD), and Continuous Tuning (CT).
CI consists of merging all working copies of an application’s code into a single version and running system and unit tests on it. When working with LLMs and other FMs, unit tests often need to be manual tests of the model’s output.
CD consists of deploying the application infrastructure and model(s) into the specified environments once the models are evaluated for performance and quality with metric based evaluation or with humans in the loop. Common pattern consists of deploying into a development environment and quality assurance (QA) environment, before deploying into production(PROD). By placing a manual approval between the QA and PROD environment deployments, you can ensure the new models are tested in QA prior to deployment in PROD.
CT is the process of fine-tuning a foundation model with additional data to update the model’s parameters which optimizes and creates a new version of the model. This process generally consists of data pre-processing, model tuning, model evaluation, and model registration. Once the model is stored in a model registry, it can be reviewed and approved for deployment.
Core Components of LLMOps
Data Preparation:
Model Development and Training
Model Evaluation and Testing:
Model Deployment:
Model Monitoring and Maintenance:
Challenges and Best Practices
Differences between LLMOps and MLOps:
Top 10 Use Cases:
Conclusion:
As LLMs continue to evolve and become more complex, LLMOps will play a vital role in ensuring their effective and responsible deployment in various industries. By following best practices and leveraging the right tools, organizations can maximize the benefits of LLMs while mitigating potential risks. LLMOps is not just a technical discipline but also requires careful consideration of ethical and societal implications. By adopting a responsible approach to LLMOps, organizations can harness the power of LLMs to drive innovation and create positive impact.