Excel Isn't Going Anywhere, So Let's Automate Parsing?It
Lasha Dolenjashvili
Data Solutions Architect @ Bank of Georgia | IIBA? Certified Business Analyst | Open to Freelance, Remote, or Relocation Opportunities
Introduction
Excel remains a significant part of our work lives. Despite modern tools and technologies, we frequently handle Excel files?—?particularly those filled in manually. Parsing these files manually is both time-consuming and challenging.
In this guide, I’ll share how I built a simple function that finds and extracts tables from messy Excel files using Python and Pandas. Best of all, you can adapt this method to work with Polars or any other DataFrame library.
Why automate Excel parsing? Three words: Efficiency, Consistency, Scalability.
Excel files, especially those filled out manually, can be unpredictable:
Automating the parsing process ensures consistent data extraction, regardless of how messy the file is.
The Challenge
When receiving Excel files, you might encounter these challenges:
Additionally, each file from stakeholders might have a different structure than previous ones.
Our goal is to efficiently extract table data, focusing only on the columns we REQUIRE for analysis. In my experience, there’s just one crucial requirement for stakeholders: maintain consistent column names in the header.
The Solution
To handle Excel file parsing, I built a generic Python functions:
The solution steps:
Here are the functions I use, and we’ll break them down step by step.
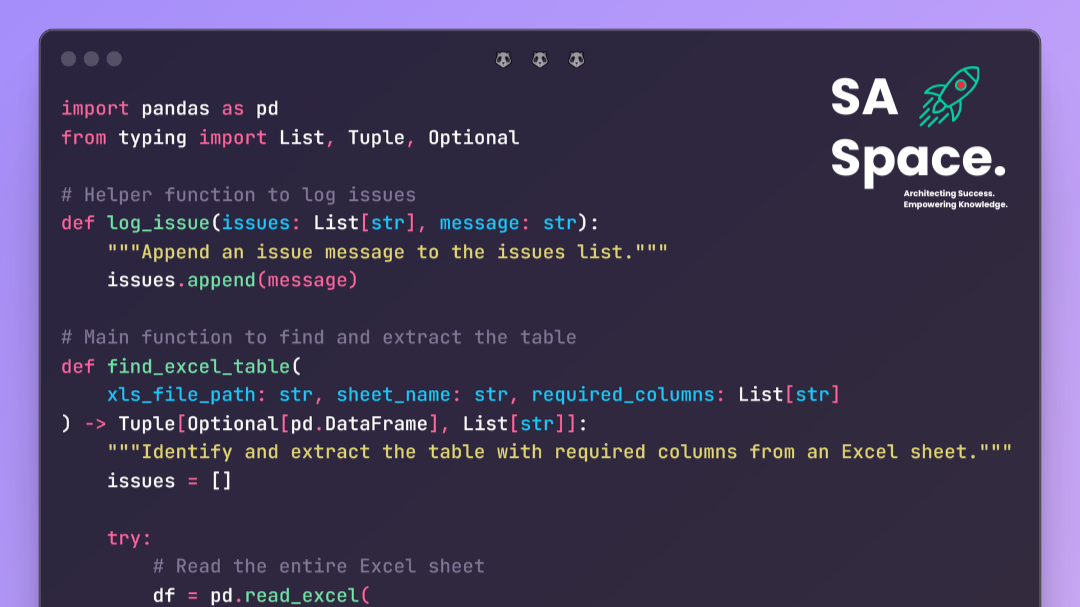
import pandas as pd
from typing import List, Tuple, Optional
# Helper function to log issues
def log_issue(issues: List[str], message: str):
"""Append an issue message to the issues list."""
issues.append(message)
# Main function to find and extract the table
def find_excel_table(
xls_file_path: str, required_columns: List[str], sheet_name: str="Sheet1"
) -> Tuple[Optional[pd.DataFrame], List[str]]:
"""Identify and extract the table with required columns from an Excel sheet."""
issues = []
try:
# Read the entire Excel sheet
df = pd.read_excel(
xls_file_path, sheet_name=sheet_name, engine="openpyxl", dtype=str
)
print("Excel file read successfully.")
except Exception as e:
log_issue(issues, f"Error reading Excel file '{xls_file_path}': {e}")
return None, issues
header_row_index = None
# Iterate over each row to find the header
for idx, row in df.iterrows():
row_values = [
str(x).strip() for x in row.tolist()
if str(x).strip() != "" and str(x).strip().lower() != "nan"
]
if set(required_columns).issubset(set(row_values)):
header_row_index = idx
print(f"Header found at row index: {header_row_index}")
break
if header_row_index is None:
log_issue(issues, "Required columns not found in any row.")
return None, issues
# Slice the DataFrame starting from the header row
df = df.iloc[header_row_index:].reset_index(drop=True)
df.columns = df.iloc[0] # Set the first row as header
df = df[1:] # Remove the header row from data
# Return only the required columns
return df[required_columns], issues
Step-by-Step Breakdown
Import Necessary Libraries
We start by importing Pandas and typing tools for type hints. I love using type hints, they make my code more readable and easy to understand both for developers and linters.
import pandas as pd
from typing import List, Tuple, Optional
Helper Function to Log?Issues
This function collects any issues encountered during the parsing process.
def log_issue(issues: List[str], message: str):
issues.append(message)
The Main Function?—?find_excel_table
The find_excel_table function is where the magic happens.
Function Definition:
def find_excel_table(
xls_file_path: str, sheet_name: str, required_columns: List[str]
) -> Tuple[Optional[pd.DataFrame], List[str]]:
Reading the Excel?File
This is the first step. We attempt to read the Excel file using pd.read_excel?.?
Important Note: The dtype=str parameter ensures all data is read as strings, which helps avoid issues with mixed data types. We don't want Pandas (or Polars) to infer column types for a key reason: when stakeholders manually fill Excel files, they often make formatting errors or add notes directly in the "production" template?—?for example, using commas instead of dots for decimal points.
We want the “read” step to succeed regardless of these inconsistencies. It’s better to get the data into a DataFrame first, then process it as needed, and decide what to do next.
df = pd.read_excel(
xls_file_path, sheet_name=sheet_name, engine="openpyxl", dtype=str
)
Efficiency Note: I tend to use calamine engine whenever possible?—?in Polars, it’s a default engine.
Finding the Header?Row
Now, this is an interesting part. We iterate over each row to find where the header starts.
header_row_index = None
for idx, row in df.iterrows():
row_values = [
str(x).strip() for x in row.tolist()
if str(x).strip() != "" and str(x).strip().lower() != "nan"
]
if set(required_columns).issubset(set(row_values)):
header_row_index = idx
break
Handling Missing?Headers
But what if we can’t find the header row? In that case, we log an issue and exit the function.
if header_row_index is None:
log_issue(issues, "Required columns not found in any row.")
return None, issues
Extracting the?Table
Once we’ve found the header row:
df = df.iloc[header_row_index:].reset_index(drop=True)
df.columns = df.iloc[0] # Set the first row as the header
df = df[1:] # Remove the header row from the data
Returning the?Results
Finally, we return the DataFrame containing only the required columns and any issues encountered.
return df[required_columns], issues
While I generally avoid returning multiple values, I find this approach makes Excel parsing pipelines easier to handle?—?especially when sending formatted alerts to stakeholders.
Using the?Function
Now, let’s see how to use this function in practice.
required_columns = ["Name", "Email", "Phone"]
xls_file_path = "path/to/your/excel_file.xlsx"
sheet_name = "Sheet1"
df, issues = find_excel_table(xls_file_path, required_columns, sheet_name)
if df is not None:
print("Table extracted successfully!")
print(df.head())
else:
print("Failed to extract table.")
for issue in issues:
print(issue)
Bonus?—?Sending Alerts to Stakeholders
Need to notify stakeholders about issues encountered during the parsing process? I often do this to help them correct and resubmit the file.
Here’s a function that converts an issues dictionary into structured text for an email body:
from typing import Dict
def format_issues_for_email(file_issues: Dict[str, List[str]]) -> str:
"""Formats the issues dictionary into a readable email body."""
email_body = ["**File Issues Report:**\n"]
for i, (filename, issues) in enumerate(file_issues.items(), start=1):
if not issues:
continue
email_body.append(f"{i}. *{filename}*")
for issue in issues:
email_body.append(f" - {issue}")
email_body.append("") # Adds a blank line between files
return "\n".join(email_body)
Example Usage
Let’s say you processed multiple Excel files and collected issues for each one.
file_issues = {
"excel_file1.xlsx": ["Missing columns: Email, Phone"],
"excel_file2.xlsx": ["Error reading Excel file: File not found"],
"excel_file3.xlsx": []
}
email_body = format_issues_for_email(file_issues)
print(email_body)
Output:
**File Issues Report:**
1. *excel_file1.xlsx*
- Missing columns: Email, Phone
2. *excel_file2.xlsx*
- Error reading Excel file: File not found
You can now include email_body in an email to stakeholders, informing them of any issues that need attention.
You can copy my Google Colab Notebook to try the above functions yourself.
Conclusion
To summarize, automating Excel file parsing can significantly improve your data extraction process. In my experience, the process typically involves these steps:
I hope this guide helps with your data handling tasks. Feel free to modify the functions to suit your specific needs, and don’t hesitate to reach out with questions or suggestions?—?I’m always open to feedback.
Enjoyed the article? Support my newsletter by following the Paypalme Link. ??
Authors Note:
? Keep Knowledge Flowing by following me for more content on Solutions Architecture, System Design, Data Engineering, Business Analysis, and more. Your engagement is appreciated.
?? You can also follow my work on:
Aspen Data Lab | Predictive Analytics | Explainable AI | Gen AI | Big Data
3 个月I prefer to unpivot/melt every worksheet. Just like the tidyxl R package but in Python.