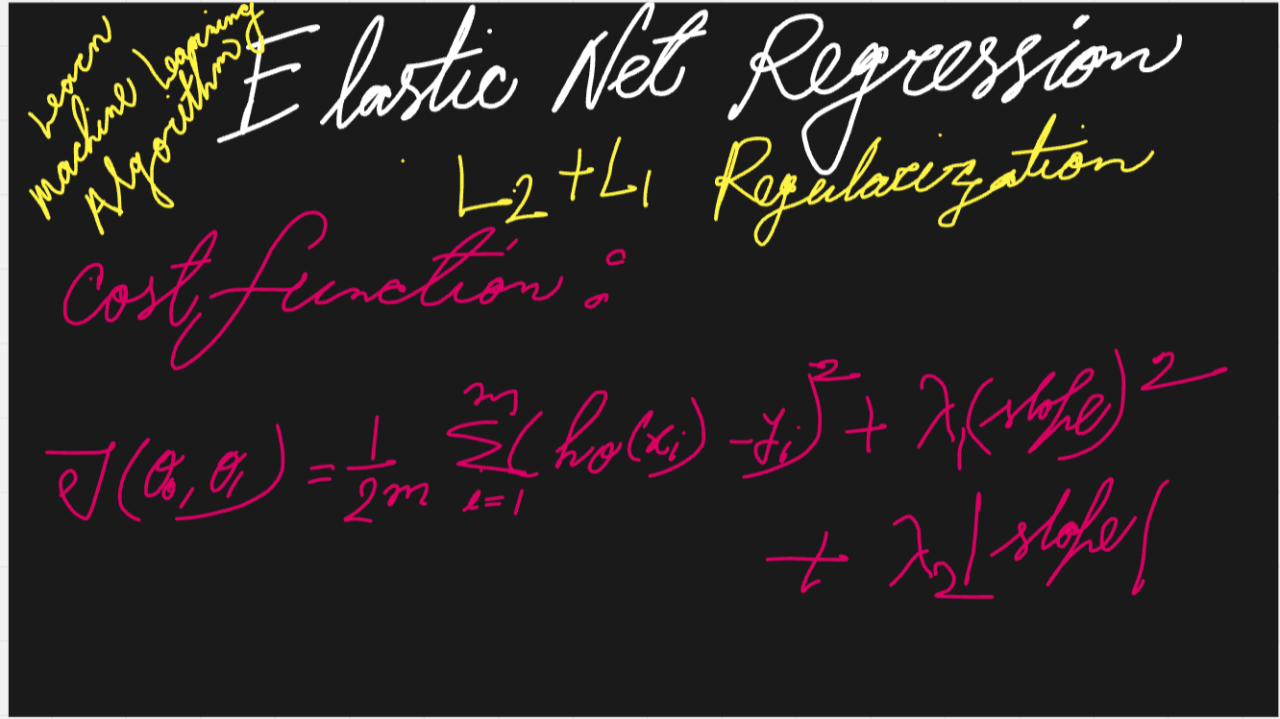
Elastic Net Regression: Combining Both Ridge & Lasso
In the vast field of machine learning, regularization plays a crucial role in preventing overfitting and improving the generalizability of models. While Ridge Regression and Lasso Regression are popular techniques for regularization, both have their limitations. This is where Elastic Net Regression comes in, combining the strengths of both Ridge and Lasso to create a powerful tool for high-dimensional data and feature selection.
In this article, we’ll explore the concept of Elastic Net Regression, its unique benefits, and when to use it over other regression methods.
What is Elastic Net Regression?
Elastic Net Regression is a linear regression model that combines L1 (Lasso) and L2 (Ridge) regularization penalties. It addresses the limitations of both methods by offering a hybrid approach, making it more flexible and powerful for handling complex datasets with many features or high multicollinearity.
In simple terms, Elastic Net combines the feature selection capability of Lasso and the shrinking effect of Ridge, leading to a more robust model.
Why Use Elastic Net Regression?
Both Lasso and Ridge regression have their advantages, but they also come with some limitations:
Elastic Net overcomes these drawbacks by incorporating both penalties. It is especially useful when:
Elastic Net can be seen as a middle ground, balancing Ridge’s ability to handle correlated features and Lasso’s ability to perform feature selection.
How Does Elastic Net Work?
Elastic Net introduces two key parameters:
By tuning both of these parameters, Elastic Net allows for more flexibility compared to Ridge or Lasso alone. If λ1=0= 0λ1=0, Elastic Net becomes equivalent to Ridge regression, and if λ2=0 = 0λ2=0, it becomes equivalent to Lasso.
The combination of both penalties allows Elastic Net to handle datasets where:
Bias-Variance Tradeoff in Elastic Net
Like any regularization method, Elastic Net helps with the bias-variance tradeoff:
Elastic Net strikes a balance between bias and variance by combining the strengths of Ridge and Lasso, allowing the model to better generalize to unseen data while retaining important features.
领英推荐
Key Advantages of Elastic Net
When Should You Use Elastic Net?
Elastic Net is particularly useful in scenarios where:
Tuning Parameters: How to Choose λ1 and λ2
One of the key steps in using Elastic Net is tuning the regularization parameters λ1 and λ2
. This can be done through techniques like cross-validation, which allows you to evaluate the model’s performance on unseen data and select the best combination of parameters.
In practice, machine learning libraries like scikit-learn make this process easier by providing methods like ElasticNetCV, which automatically finds the optimal values for both penalties.
Practical Example: Elastic Net in Action
Imagine you're working on a problem where you have to predict housing prices, but many of the features (e.g., number of rooms, size, location) are highly correlated with each other. Additionally, you have hundreds of features, many of which may not be relevant to the target variable.
By applying Elastic Net Regression, you can:
Elastic Net helps in creating a robust model that strikes the right balance between feature selection and preserving important correlations between variables.
Conclusion
Elastic Net Regression is a powerful tool for handling high-dimensional datasets, multicollinearity, and feature selection. By combining the strengths of both Ridge and Lasso Regression, Elastic Net creates a flexible, balanced model that’s well-suited for a wide range of machine learning problems. Whether you're working with complex data or want to improve model performance through regularization, Elastic Net offers the best of both worlds.
If you're looking to improve your machine learning models by regularizing and selecting features effectively, Elastic Net might just be the solution you need.
About the Author:
Shakil Khan,
Pursuing BSc. in Programming and Data Science,
IIT Madras