Efficiently Check If a Username Exists Among Billions of Users
?? ??Saral Saxena ??????
?11K+ Followers | Linkedin Top Voice || Associate Director || 15+ Years in Java, Microservices, Kafka, Spring Boot, Cloud Technologies (AWS, GCP) | Agile , K8s ,DevOps & CI/CD Expert
Have you ever tried to register for an app, only to find out that your preferred username is already taken? While this might seem like a minor inconvenience, it’s a significant technical challenge for applications that handle massive user bases. The process of determining whether a username is available can be approached in several ways, each with its strengths and weaknesses. In this article, we will explore three methods: the traditional Database Query, a Caching Strategy with Redis, and an optimized approach using a Bloom Filter.
When memory efficiency is critical, a Bloom Filter offers an attractive solution. A Bloom Filter is a space-efficient probabilistic data structure that allows for quick checks on whether an element (like a username) is part of a set. The trade-off is that it may occasionally produce false positives — indicating that a username exists when it does not.
Simplified Explanation of Bloom Filters
A Bloom Filter is a smart, space-efficient tool used to check if an item is part of a set. It’s especially useful when you want to avoid storing large amounts of data. The catch? It might occasionally tell you an item is in the set when it’s not (false positive), but it will never miss an item that is actually in the set (no false negatives).
How It Works:
Why Use Bloom Filters?
In short, Bloom Filters are a powerful tool when you need quick, memory-efficient membership testing, as long as you can handle the occasional false positive.
Here’s how you can implement a Bloom Filter in Go using the bloom package:
package main
import (
"fmt"
// https://pkg.go.dev/github.com/bits-and-blooms/bloom/v3#section-readme
"github.com/bits-and-blooms/bloom/v3"
)
func main() {
// Initialize a Bloom Filter
filter := bloom.New(20*1000*1000, 5) // Capacity: 20 million, 5 hash functions
// Add a username to the Bloom Filter
filter.AddString("john_doe")
// Check if a username exists
exists := filter.TestString("john_doe")
fmt.Printf("Username 'john_doe' exists? %v\n", exists)
// Check for a non-existent username
exists = filter.TestString("jane_doe")
fmt.Printf("Username 'jane_doe' exists? %v\n", exists)
}
领英推荐
Output:
Username 'john_doe' exists? true
Username 'jane_doe' exists? false
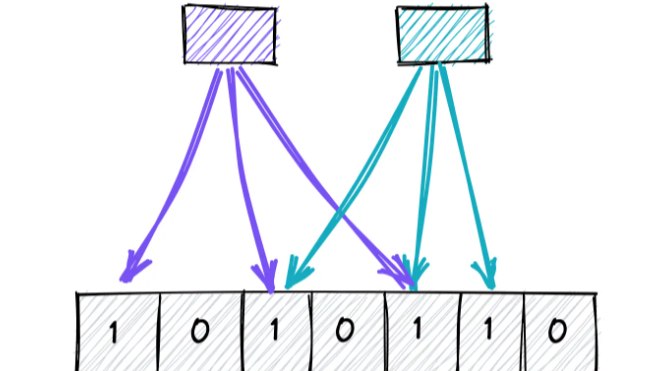
Visual Explanation of Bloom Filters
The diagram below visually explains how a Bloom Filter works:
Part (a): Inserting a Sequence
Part (b): Querying a Sequence
Summary:
This diagram visually shows how Bloom Filters can be used to efficiently check for the presence or absence of data in a set, making them useful in many scenarios like filtering or speeding up database queries.