Distributed Locking: Ensuring Consistency in Shared Resource Access
Distributed systems, with their inherent complexity, require robust mechanisms to ensure data consistency and prevent race conditions when multiple processes access shared resources concurrently. Distributed locking plays a crucial role in achieving this by providing exclusive access control for critical sections of code that modify shared data.
Understanding the Need for Distributed Locking
Imagine an inventory management system in a warehouse. Multiple workers might attempt to update the stock levels for a particular item at the same time. Without proper locking, inconsistencies can arise:
- Scenario 1: Worker A fetches the current stock level (10) and decrements it for an order. However, before A saves the updated value (9), worker B also fetches the stock (10) and decrements it for their order. This results in overselling the item (showing 8 units in stock when there are only 7).
- Scenario 2: Worker A starts updating the stock level but encounters an error midway. The lock isn't released, preventing other workers from updating the stock until the issue with A is resolved. This can lead to delays and disruptions in the workflow.
Distributed locking prevents such scenarios by:
- Serializing access: Only one worker can acquire and hold the lock at a time, ensuring exclusive access to the stock level data.
- Maintaining data integrity: By preventing concurrent modifications, data consistency is guaranteed, eliminating the risk of race conditions and overselling.
Challenges in Distributed Locking
While conceptually simple, distributed locking comes with its own set of challenges:
- Single Point of Failure (SPOF): If a central locking service is used, its failure can bring the entire inventory management system to a halt.
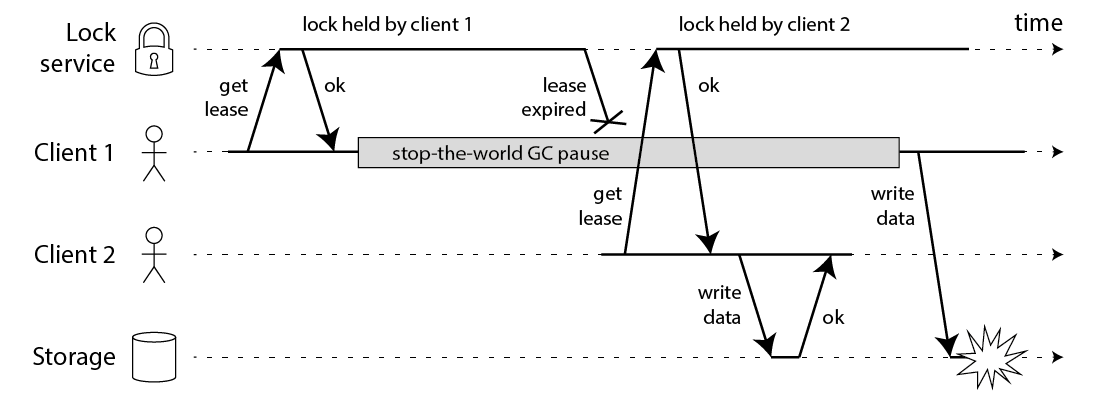
- Network Partitions: Network delays or outages can lead to inconsistencies if a worker holding a lock becomes unavailable. In our example, worker A might have acquired the lock for updating stock but experiences a network issue. This can prevent other workers from accessing the data even though A is no longer actively modifying it.
- Deadlocks: If workers wait on locks held by each other (e.g., worker A needs lock 1 and worker B needs lock 2, but A holds lock 2 and B holds lock 1), a deadlock can occur, preventing any progress.
Popular Distributed Locking Approaches
There are several techniques to implement distributed locking, each with its strengths and weaknesses:
- Leverages built-in locking mechanisms offered by databases (e.g., locking tables or rows for the stock level data).
- Simple to implement but might not scale well for highly concurrent access in a busy warehouse with many workers.
- Limited fault tolerance as a database failure can disrupt locking functionality.
Distributed Lock Manager (DLM):
- Utilizes a dedicated service to manage locks across different nodes in the system, like separate servers managing different sections of the warehouse.
- Offers high availability and fault tolerance as failures in individual nodes won't affect the entire locking mechanism. This ensures even if one server managing a specific section fails, workers in other sections can still acquire and release locks for their respective areas.
- Popular algorithms like Redlock provide robust locking with good scalability for large-scale inventory management systems.
Choosing the Right Approach
The ideal distributed locking approach depends on your specific requirements. Consider factors like:
- Scalability: If you anticipate a high volume of concurrent access (many workers updating stock levels), a DLM is likely a better choice compared to database locking.
- Fault Tolerance: A DLM offers higher fault tolerance compared to relying on a single database server.
- Performance: Database locking might offer lower latency for small-scale deployments, but a DLM can maintain good performance even with high concurrency.
By carefully considering these factors, you can choose the most appropriate distributed locking approach to ensure data consistency and smooth operation in your distributed system.