Deploying Machine Learning Models at Scale: Insights for Business Leaders and Technical Teams from LeaseSCRE's Lessons Learned
Chris Pappalardo
Senior Director at Alvarez & Marsal | Software Engineer and FinTech Innovator | CPA, AWS Solutions Architect
Whether you’re a technical expert or a business leader, if you’re part of an organization that uses machine learning and plans to make machine learning models available to a wider audience, such as employees and customers, there are several issues you need to consider. Updating your model dependencies, dynamically routing requests to the proper models, scaling to handle increased volume, and planning for authentication and security are all important considerations.?In this article, I’ll discuss lessons that we learned firsthand in these four areas at Alvarez & Marsal when building and deploying LeaseSCRE, our proprietary machine learning model that predicts corporate credit ratings from 12 financial features with 92% accuracy (1).
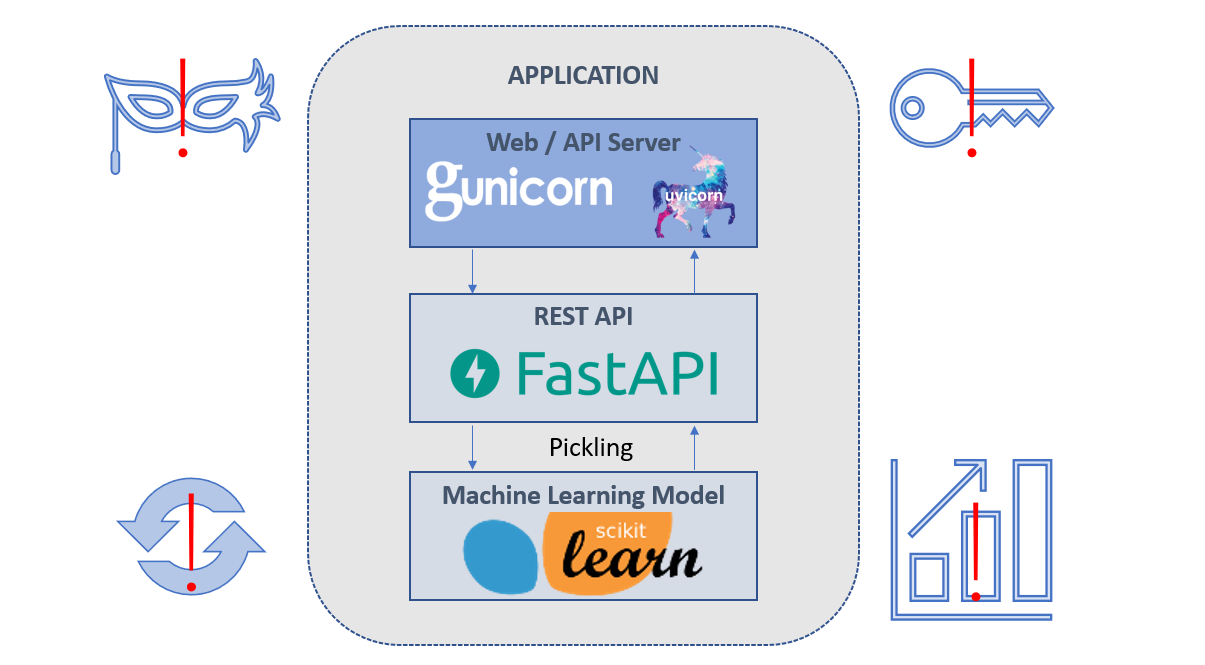
Unless you’re using a cloud-based machine learning service, you likely will be using some form of model persistence and a web service.?In this article, I will focus on Python-based machine learning platforms, which typically use object pickling and an API server to deploy models for broader use.?A typical deployment scenario can be depicted as follows:
You may be planning to use a similar pattern or have an application like this already running.?But have you thought through the following issues that can arise?
Our team at A&M had to deal with each of these issues when building LeaseSCRE after our application was already launched and made available to external users.?Here are some takeaways from our experience dealing with each of these issues:
Have a plan for migrating models when updating dependencies.
Pickling is a Python technique for serializing objects so they can persist outside of Python’s memory, such as on the filesystem or in a database.?Pickling is both a blessing and a curse.?The issue with pickling trained machine learning model objects is that the serialization is specific to the version of the library.?If you update it, you could break your app.?One way to deal with this issue is to combine library dependency updates with a data migration that retrains your models on the new platform.?But the cost involved may not be trivial and requires other data and information that may not be available to your application.
领英推荐
Consider aliasing your model API endpoints.
API endpoints for machine learning models are often specific to the model object itself.?At A&M, we use UUIDs to reference models and APIs, since they ensure there is no ambiguity in what is being accessed.?However, UUIDs are long and cryptic strings and are not human-friendly.?Often, users will want to access models by descriptive information like relevant date, rather than a unique identifier.?Implementing endpoint aliases can offload the task of using the correct model from the user to the server.
Containerize your API service so you can scale easily based on load.
Most likely you’ll be hosting your application in some type of cloud-based service.?Resist the urge to host your app on “bare metal” servers, use containers and a container service instead.?Containerization is the process of creating services from images where the underlying server(s) and infrastructure are handled by the cloud provider.?Containerized services are easy to scale up (larger servers) and out (more servers) based on dynamic load.?They also integrate well into other cloud services that you may already be using, such as HTTPS offloading, load balancing, log capture, and firewalling.
Use API keys and HTTPS to both authenticate and secure API calls from users.
Resist the temptation to create an open API or delay the implementation of authentication and security.?API keys are available natively or as an optional package in most web application frameworks.?API keys can be generated for each user and your API endpoints can be configured to require a valid key to generate a response.?You can offload the effort of HTTPS to your cloud provider, and HTTPS ensures that API keys are protected when traversing the internet to your endpoints.?And an added benefit of API keys is they allow you to tract user activity for monetization purposes.
In conclusion, whether you're a technical expert or a business leader, it's important to remember that these issues can have significant impacts on successfully realizing the benefits of an otherwise successful machine learning project. By planning for these challenges in advance, you'll be able to deploy robust and scalable machine learning models in a way that meets the needs of your organization and customers.?We have many tools at Alvarez & Marsal that we’ve developed internally to tackle these challenges, including an API server that can host machine learning models and many other kinds of digital assets, so feel free to reach out for help.
(1) Alvarez & Marsal Valuation Services, LLC is not a rating agency and does not publish ratings on individual companies; it uses a prediction of a likely corporate credit rating for private companies solely as an input to its proprietary models.
Global head of Valuation and Investigations
1 年Great read on deploying apps safely and efficiently!