Deploying machine learning models into production involves setting up an infrastructure that can handle user requests, perform model inference, and return the results efficiently. In this post, we will explore how to deploy a machine learning model using AWS Lambda, API Gateway, and Docker.
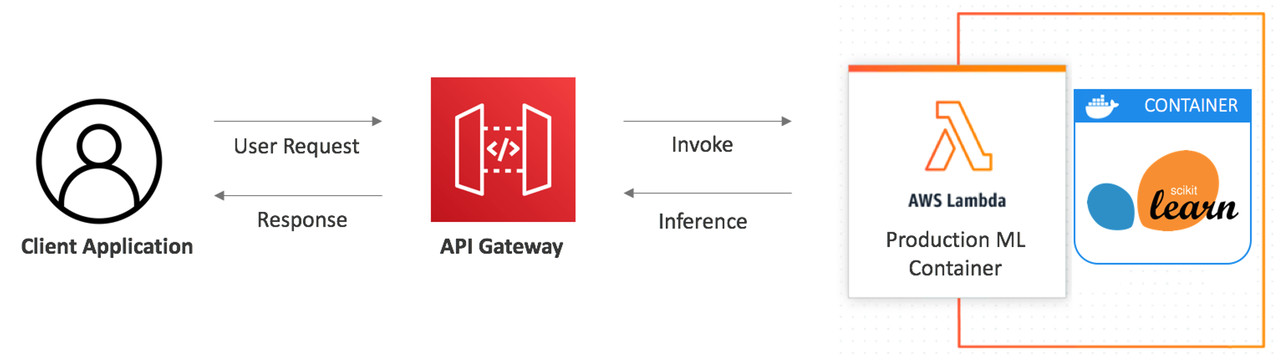
The diagram illustrates a common architecture for deploying a machine learning model:
- Client Application: This is the frontend interface where users interact with the application. It sends user requests to the backend.
- API Gateway: This serves as the entry point for the client application to access backend services. It receives user requests and forwards them to the appropriate service for processing.
- AWS Lambda: This is a serverless compute service that runs code in response to events. It is used here to invoke the machine learning model for inference.
- Production ML Container: This is a Docker container that hosts the machine learning model. In this example, we use a container with scikit-learn.
- User Request: A user interacts with the client application, which sends a request to the API Gateway.
- Invoke: The API Gateway receives the request and invokes an AWS Lambda function.
- Inference: The AWS Lambda function calls the production ML container, which hosts the machine learning model, to perform inference.
- Response: The inference results are sent back to the AWS Lambda function, which then returns the response to the API Gateway.
- Client Response: The API Gateway forwards the response back to the client application, completing the cycle.