Demystifying Large Language Models: A Deep Dive into BERT and Its Architectural Influence
Suchir Naik
Experienced Data Scientist | AI ML & NLP Researcher | Innovating Healthcare with AI
Introduction
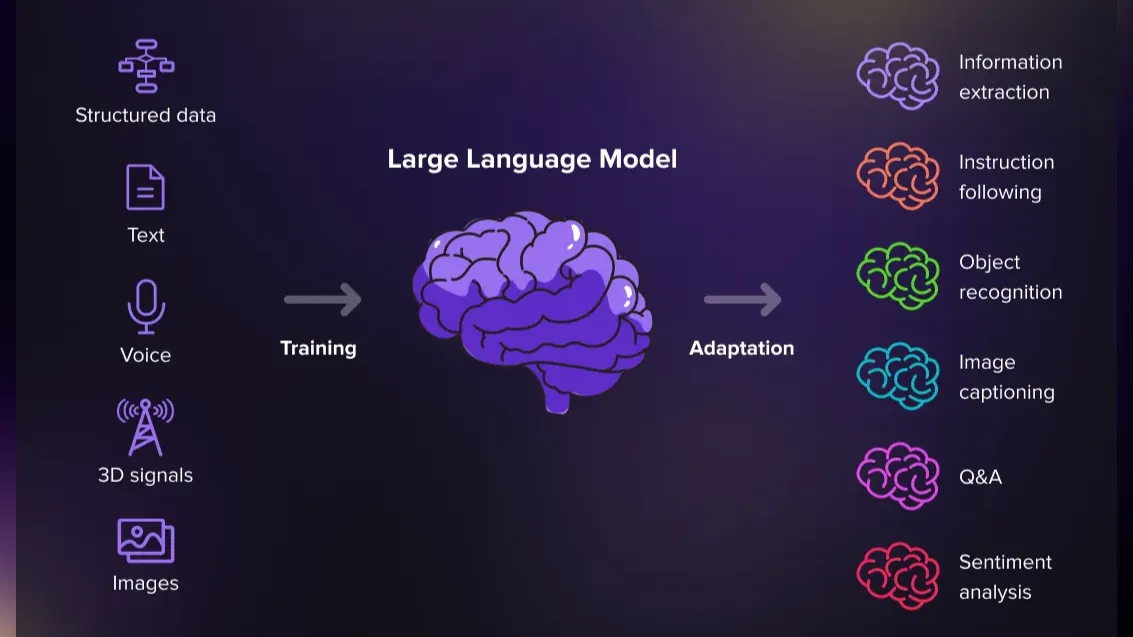
In today's digital age, understanding the nuances of human language through text data is crucial. This article is designed to introduce you to the world of Large Language Models (LLMs) which are at the forefront of analyzing and interpreting vast amounts of text data, from social media feeds and customer reviews to formal documentation. We start with BERT (Bidirectional Encoder Representations from Transformers), a foundational model that has significantly advanced Natural Language Processing (NLP) technologies.
BERT not only helps us comprehend the complex context of words in sentences but also serves as an exemplary starting point for understanding the mechanics of more sophisticated LLMs.
Further Sections: Exploring Various Types of LLMs
After understanding BERT, we’ll touch on other prominent Large Language Models (LLMs) briefly, highlighting their unique capabilities. While BERT focuses on capturing contextual relationships in language, models like GPT are renowned for text generation, and frameworks like RAG enhance factual accuracy by combining data retrieval with generation. This article will provide a starting point to explore these models, offering insight into their practical uses.
For those interested in the technical details, a GitHub link with instructions for fine-tuning BERT for sentiment analysis will be provided soon.
Understanding the BERT Architecture
Before diving into the details of building a sentiment analysis model, it’s essential to grasp why BERT is so transformative in the NLP field. BERT, introduced by Google, has reshaped the way we process language by introducing two critical ideas: bidirectional context and self-attention.
What is BERT?
BERT is a transformer-based model pre-trained on large text datasets. It learns deep bidirectional representations, meaning it considers both the left and right sides of a word simultaneously to understand its context within a sentence. Traditional models only read text in one direction (left-to-right or right-to-left), which limits their understanding. BERT processes the sentence as a whole, making it highly effective at capturing the meaning and relationships between words.
BERT is pre-trained on two main tasks:
BERT and Transformer Architecture
To understand BERT, we need to explore the Transformer architecture it is built on. The Transformer introduced two major improvements over earlier models like LSTMs, particularly bi-directional LSTMs.
1. Introduction to Transformer Architecture
The Transformer architecture was designed to solve challenges like language translation, where understanding context and ensuring fast processing are crucial. Prior to Transformers, models like LSTM (Long Short-Term Memory) networks were widely used.
Bi-directional LSTMs process information in both directions—left-to-right and right-to-left—to capture the context from both ends of a sentence. However, even in bi-directional LSTMs, the two contexts are processed separately and then concatenated. This approach leads to the following limitations:
The Transformer model addresses these issues by:
For instance, in BERT (Bidirectional Encoder Representations from Transformers), the Transformer architecture is leveraged to understand relationships between words by analyzing their surrounding context from all directions. This makes BERT ideal for complex NLP tasks like sentiment analysis, question answering, and text classification, which rely on understanding the full meaning of sentences.
3. How the Transformer Architecture Works
The core components of the Transformer include:
The stacking of these attention and feed-forward layers allows the Transformer to learn deep, context-rich representations of text, making models like BERT highly effective for tasks like sentiment analysis, question answering, and named entity recognition.
4. Understanding the BERT Architecture
BERT is based on the Transformer architecture, which consists of key components that enable it to process text efficiently and with deep contextual understanding. Let’s break down these components to understand how BERT operates.
1. Input Embeddings When a sentence is fed into BERT, each word is transformed into a numerical vector using WordPiece tokenization, which breaks down words into subword units. Positional encodings are also added to these vectors to maintain word order, crucial since transformers process words in parallel, not sequentially.
2. Self-Attention Mechanism (Multi-Head Attention) At the heart of BERT’s architecture is the self-attention mechanism, which assesses other words in the sentence to determine their relevance to each other—for instance, recognizing how "not" changes the sentiment of "bad" in the phrase "not bad." This mechanism allows BERT to consider multiple word relationships simultaneously from different perspectives.
3. Add & Norm (Residual Connection + Normalization) Post-attention, the model enhances its outputs by adding back the original input (residual connection) before normalization balances the data, similar to adjusting the focus in practice to master a new piece of piano music. This step ensures stability and continuity in the learning process.
4. Feed-Forward Layer This layer processes the data further, refining BERT's grasp of word relationships, akin to putting final touches on a learned skill. It helps the model distinguish subtleties, like the sentiment conveyed by "not bad," through non-linear transformations.
5. Stacking Layers (Nx) BERT layers these mechanisms multiple times—12 in BERTBASE and 24 in BERTLARGE—to deepen its linguistic understanding. Each repetition consolidates the model's knowledge, enhancing its ability to parse complex language constructs.
6. Final Output
Final Output: Using BERT Embeddings for Different Tasks
When BERT processes input text, it generates embeddings (numeric representations) for each word in the sentence. These embeddings can be used for different tasks depending on what you want to achieve. Here's how it works:
For Classification Tasks (like Sentiment Analysis):
To be clear, the classification layer and softmax layer are not part of BERT itself; they are added on top of BERT’s output when you're using BERT for classification tasks.
For Text Generation (like in Chatbots):
Expanding Beyond BERT: Exploring the Spectrum of LLMs
While BERT is a powerful tool in Natural Language Processing (NLP), there are many other Large Language Models (LLMs) with unique strengths and applications. These models address various linguistic challenges, offering vast opportunities for innovation.
A few examples include:
While there are many more types, uses, and applications, this article serves as a starting point with just a few examples.
Conclusion
In summary, Large Language Models (LLMs) such as BERT and GPT have transformed Natural Language Processing by offering deep contextual understanding and generating coherent, context-aware text. Frameworks like Retrieval-Augmented Generation (RAG) further enhance these capabilities by integrating external data sources, allowing for more accurate and fact-based outputs. The growing landscape of LLMs and frameworks continues to push boundaries in industries, streamlining processes like customer service, content generation, and decision-making. The key to leveraging LLMs effectively lies in selecting the right model or approach for the specific task, data, and computational resources at hand, driving both innovation and practical impact across various fields.
Stay tuned – GitHub link dropping soon with all the details on sentiment analysis and model parameters!
Software Development Expert | Builder of Scalable Solutions
5 个月Fantastic overview of BERT and the broader landscape of LLMs! Exciting to see how these models are transforming NLP tasks like sentiment analysis and text generation.
??Portfolio-Program-Project Management, Technological Innovation, Management Consulting, Generative AI, Artificial Intelligence??AI Advisor | Director Program Management | Partner @YOURgroup
5 个月Suchir Naik, your article is a great resource for leadership to grasp BERT's impact.