A decision tree algorithm is a machine learning tool that uses a tree-like structure to solve classification and regression problems.
- Structure
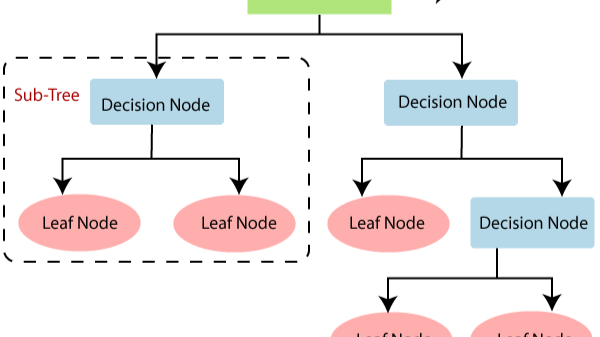
- A decision tree has a hierarchical structure with a root node, branches, internal nodes, and leaf nodes.
- Process
- The algorithm starts at the root node, performs a test, and then repeats the process until it reaches a leaf node. At the leaf node, the tree predicts the outcome.
- A Decision Tree Algorithm is a classic supervised learning model that uses a treelike graph to represent a flow-chart-like structure. It makes sequential decisions based on attribute tests to classify data into different classes. It is commonly used for decision-making and classification tasks in computer science.
- Decision trees are a popular machine learning algorithm that can be used for both regression and classification tasks. They are easy to understand, interpret, and implement, making them an ideal choice for beginners in the field of machine learning. In this comprehensive guide, we will cover all aspects of the decision tree algorithm, including the working principles, different types of decision trees, the process of building decision trees, and how to evaluate and optimize these.
- A decision tree, which has a hierarchical structure made up of root, branches, internal, and leaf nodes, is a non-parametric supervised learning approach used for classification and regression applications.
- It is a tool that has applications spanning several different areas. Decision trees can be used for classification as well as regression problems. The name itself suggests that it uses a flowchart like a tree structure to show the predictions that result from a series of feature-based splits. It starts with a root node and ends with a decision made by leaves.