Debugging Write Skew: How a Database Ghost Stole ?9.4B (And Why It Wasn’t a Crime)
The Ledger That Couldn’t Add Up
In the heart of Mumbai’s financial district, a stock exchange’s servers hummed with the usual midnight chaos. Thousands of trades settled, balances reconciled, and reports generated. But on this night, something was off. The final ledger showed a ?9.4 billion gap—a ghost in the machine. No hackers. No corrupted files. Just a silent, invisible flaw in the dance of concurrent transactions.
This is the story of how a serializability anomaly almost derailed a market open—and the engineers who raced against time to fix it.
Act 1: The Phantom in the System
The exchange’s settlement engine processed buy and sell orders in parallel. Two critical jobs ran at midnight:
Both jobs read data, calculated totals, and wrote to a settlements table. Individually, they worked perfectly. Together, they created a financial black hole.
The Illusion:
Reality:
Act 2: The Invisible Culprit
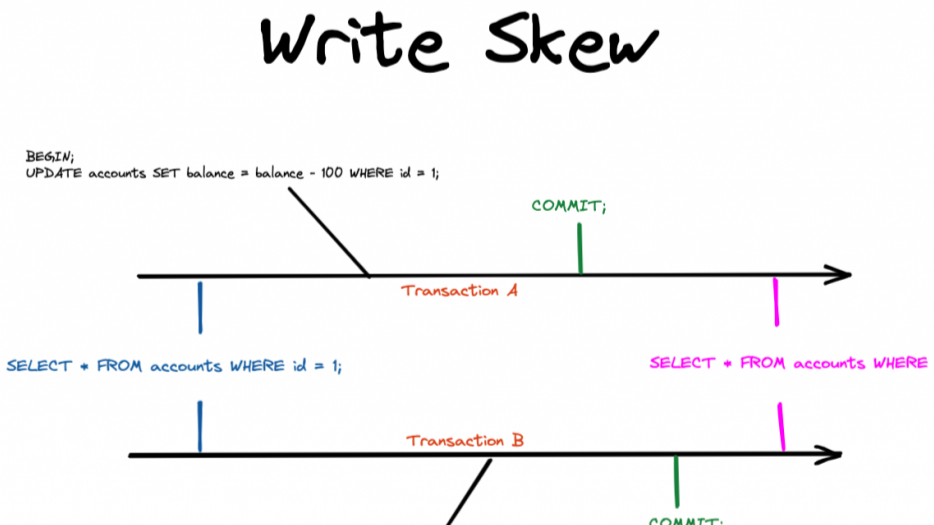
The engineers tore through logs, tracing every query. The culprit? Write skew—a phenomenon where two transactions, operating on related data, commit changes that violate a global rule.
PostgreSQL’s default REPEATABLE READ isolation had allowed both jobs to work with stale snapshots. Each saw a “balanced” world that no longer existed after the other’s write.
Understanding Write Skew in Databases
Write skew occurs when multiple transactions read overlapping data, then update it without realizing another transaction has modified the same data. Unlike traditional deadlocks, where two transactions block each other, write skew silently corrupts data.
The Analogy:
Imagine two chefs in a busy kitchen. Both check the pantry, see 10 eggs, and each starts making a 10-egg omelette. Neither realizes the other is cooking until the eggs vanish.
Now, replace eggs with stock balances, and you have a financial disaster.
Act 3: The Ghostbusters’ Toolkit
The fix wasn’t a patch—it was a paradigm shift. The team embraced Serializable Snapshot Isolation (SSI), PostgreSQL’s strictest isolation level.
Why SSI Prevents Write Skew
Under SSI, if Job Alpha and Job Beta ran in parallel, one would get aborted when it detected a conflict. This ensured that the system didn’t settle more trades than actually existed.
Trade-offs of SSI
Epilogue: The Chessmaster’s Lesson
As dawn broke over Mumbai, the team celebrated with chai and samosas. But the incident left a lingering question: Why had no one anticipated this?
The answer lies in a paradox of distributed systems: Time is an illusion. Transactions, like chess pieces, move in unpredictable sequences. What seems correct in isolation can be catastrophic in parallel.
The mischievous twist? The engineers later discovered the anomaly had occurred twice before—but went unnoticed. The market’s tolerance for minor imbalances had masked the flaw.
Understanding Write Skew (again): A Subtle Form of Data Corruption
Write skew occurs when two concurrent transactions read overlapping data, make decisions based on that data, and then update it—without realizing another transaction has modified the same data. Unlike a traditional lost update problem where two transactions modify the same row, write skew typically involves multiple rows with logical dependencies.
Example: The Bank Account Paradox
Consider two users withdrawing money from a joint account that requires a minimum balance of $500. If both users check the balance (say, $600), see that they can withdraw $100, and execute their transactions in parallel, the final balance ends up at $400—violating the constraint. Neither transaction directly conflicts with the other, so the database allows them both.
This is the essence of write skew: an illusion of consistency that breaks global integrity constraints.
Why Traditional Isolation Levels Fail
Most database management systems (DBMS) offer multiple isolation levels, each with trade-offs in consistency and performance. However, write skew exploits gaps in these guarantees.
1. Read Uncommitted
2. Read Committed
3. Repeatable Read (Default in PostgreSQL)
4. Serializable (via Serializable Snapshot Isolation - SSI)
How Serializable Snapshot Isolation (SSI) Defeats Write Skew
Serializable Snapshot Isolation (SSI) is PostgreSQL’s implementation of true serializability without significant performance degradation. It achieves this by detecting conflicts dynamically instead of locking entire tables.
Key Techniques in SSI:
1. Predicate Locking
Traditional databases use row-level locks, but write skew arises when multiple rows or conditions are involved. Predicate locking tracks logical conditions instead of physical records. If two transactions rely on overlapping conditions (e.g., all users with a balance >$500), one must abort if a conflict arises.
2. Conflict Detection
PostgreSQL constantly monitors concurrent transactions to see if their execution order would have been different in a serialized schedule. If a conflict is detected, one of the transactions is rolled back and retried.
3. Sacrificial Abort
Instead of blocking indefinitely, SSI proactively aborts transactions that could lead to anomalies. This ensures that transactions remain safe without introducing excessive contention.
Performance Trade-offs of SSI
While SSI ensures correctness, it does come with operational challenges.
For high-frequency trading systems or databases handling millions of transactions per second, the trade-off between strict serializability and performance must be carefully balanced.
Preventing Write Skew Without Full Serializability
If full SSI is too expensive, here are some alternative approaches:
Final Thoughts: The Hidden Dangers of “Almost Correct” Systems
Write skew is particularly dangerous because it leaves no obvious traces—it’s not a crash, an error log, or a deadlock. The system appears to be functioning normally, but the data subtly diverges from reality. The financial industry, where milliseconds matter, must carefully evaluate its transaction isolation strategies.
The stock exchange incident underscores a broader lesson in distributed systems: correctness is not just about avoiding crashes, but about ensuring the integrity of every single transaction. As businesses scale, ensuring strict consistency in the face of concurrency will remain one of the biggest challenges in database engineering.
References
Senior Software Engineer in Performance at Beqom Switzerland
2 周Thank you for an unusually interesting write up!