Databloom Blossom - The Federated AI for Data Lakehouse Analytics
Machine Learning (ML) is a specific subset (branch) of Artificial Intelligence (AI). The main idea of ML is to enable systems to?learn from?historical?data?to predict new output values for input events. ML does not require systems to be explicitly programmed to achieve the goal. With the growing volumes of data in today’s world, ML has gained an unprecedented popularity; we achieve today what it was un-imaginable yesterday: from predicting?cancer risk over mammogram?images and patient risk data to polyglot AI translators, es example. As a result, ML?has become?the key?competitive differentiator for many companies, leading ML-powered software to quickly become omnipresent in our lives. The core key of ML is data dependent; more available data enables much better accuracy of predictive models built by ML.
The Appearance of Distributed ML
While ML has become a quite powerful technology, its hunger for training data makes it hard to build ML models with a single machine. It is not unusual to see training data sizes in the order of hundreds of gigabytes to terabytes, such as in the Earth Observation domain. This has created the need to build ML models over distributed data, stored in different multiple storage nodes across the globe.
Distributed ML aims to train themselves, using multiple compute nodes to cope with larger input training data sizes as well as to improve performance and models’ accuracy [1]. Thus, distributed?ML enables organizations and individuals to draw meaningful conclusions from vast amounts of distributed training data. Healthcare, enterprise data analytics and advertising are examples of the most common sectors that highly benefit form distributed ML.
There exist two fundamental ways to perform distributed ML: data parallelism and model parallelism [2].
In the data parallelism approach, the system horizontally partitions the input training data, usually it creates as many partitions as available compute nodes (workers) and distributes each data partition to a different worker. Afterwards, it sends the same model features to each worker, which, in turn, learns a local model using their data partition as input. The workers send their local model to a central place where the system merges the multiple smaller inputs into a single global model.
The model parallelism approach, in contrast to data parallelism, partitions the model features and sends each model partition to a different worker, which in turn build a local model using the same input data. That is, the entire input training data is replicated in all workers. Then, the system brings these local models into a centralize place to aggregate them into a single global model.
Yet, although powerful, distributed ML has a core assumption that limits its applicability: one can have control and access over the entire training data.?
However, in an increasingly number of cases, one cannot have direct access to raw data; hence distributed ML cannot be applied in such cases, for example in the healthcare domain.
The Emergence of Federated Learning
The concept of FL was first introduced Google in 2017 [3]. Yet, the concept of federated analytics/databases date from the 80’s [4]. Similar to federated databases, FL aims at bringing computation to where the data is.
Federated learning (FL) is basically a distributed ML approach. In contrast to traditional distributed ML, raw data at different workers is never moved out of the particular worker. The workers own the data and they are the only ones having control and have direct access to it. Generally speaking, FL allows for gaining experience for a more diverse set of datasets at different independent/autonomous locations.?
Ensuring data privacy is just crucial in todays world, the societal?awareness for data privacy is rising as one of the main concerns of our more and more data driven world. For example, many governmental organizations have laws, such as GDPR [5] and CCPA [6], to control the way data is being stored and processed. FL?enables?organizations and individuals to train ML models across multiple autonomous parties without compromising data privacy, since the sole owner of the data is the node on which the data is stored. During training, organizations/individuals share their local models to learn from each other’s local models. Thus, organizations and individuals can leverage from others data to learn more robust ML models than when using their own data only. Multiple participants collaboratively train a model with their sensitive data?and communicate among them only the learnt local model.
The beauty of FL is that enables organizations and individuals to collaborate towards a common goal without sacrificing data privacy.?
FL also leverages the two fundamental execution modes to build models across multiple participants: horizontal learning (data parallelism) and vertical learning (model parallelism).?
What are the problems today?
The research and industry community have already started to provide multiple systems in the arena of federated learning. TensorFlow Federated [7], Flower [8], and OpenFL [9] are just a few examples of such systems. All these systems allow organizations and individuals (users) to deploy their ML tasks in a simple and federated way using a single system interface.?
Yet, there are still several open problems that have not been tackled by these solutions, such as preserving data privacy, model debugging, reduce wall-clock training times, and reducing the trained model size. All of equally importance. Among all of these open problems there is one of crucial importance: supporting end-to-end pipelines.
Currently, users must have good knowledge of several big data systems to be able to create their end-to-end pipelines. They must have decent technical knowledge starting from data preparation techniques and will not end with ML algorithms. Furthermore, users must also deploy good coding skills to put all the pieces (systems) together to create end-to-end pipeline. And Federated Learning exacerbates the problem.
How Blossom solves this problems
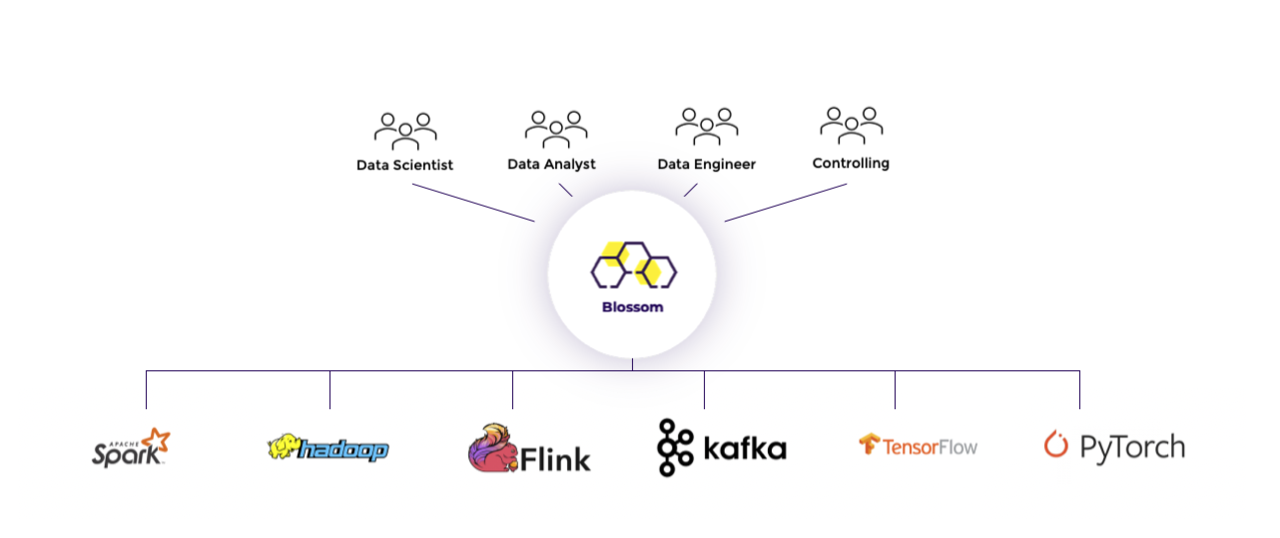
Databloom offers Blossom, a?Federated AI and Data Lakehouse Analytics?Platform to?help users to build their end-to-end federated pipelines. Blossom covers the entire spectrum of analytics in end-to-end pipelines and executes them in a federated way. Especially, Blossom allows users to?focus solely on the logic of their applications, instead of worrying about the system, execution, and deployment details.?
Overall, Blossom comes with?two simple interfaces for users to develop their pipelines: Python (FedPy)?for data scientists?and a graphical dashboard (FedUX)?for users?in general.
Blossom provides users with the means to easily develop their federated data analytics in a simple way for a fast execution.?
In more detail, users specify their pipelines using any of these two interfaces. Blossom, in turn,?runs the created pipelines?in a federated fashion using any?data processing platform available for the user, be it in any cloud or hybrid constellation.
//create a context to set the platform
val wayangContext = new WayangContext(new Configuration)
.withPlugin(Java.basicPlugin)
.withPlugin(Spark.basicPlugin)
//create plan builder
val planBuilder = newPlanBuilder(WayangContext)
//Wordcount plan and result in as a list
val wordcounts = planBuilder
.readTextFile(inputFile)
.flatMap(_.split("\\W+"))
.map (word => (word.toLowerCase, 1))
.reduceByKey(_._1, (c1, c2) => (c1._1,c1._2 + c2._2))
.collect()
The example?above?shows the simple WordCount application in Blossom. The intelligence of Blossom lets the user focus on the task, and not the technical decision on which data processing platform every single step should run (Java Streams or Spark, in our case). Blossom decides the actual execution based on the input datasets and processing platforms characteristics (such as the size of the input dataset and the Spark cluster size).?It can do so via an AI-powered cross-platform optimizer and executor.
Blossom AI-Powered Optimizer
At Blossoms core, we find Apache Wayang [10], the first cross-platform data processing system. Blossom leverages and equips Apache Wayang with AI to unify and optimize heterogeneous (federated) data pipelines. Additionally, the system is able select the right cloud provider and data processing platform to run the resulting federated data pipelines. As a result, users can seamlessly run general data analytics and AI together on any data processing platform.
Blossom’s optimizer?mainly provides an?intermediate representation between applications and processing platforms, which allows it to flexible compose the users pipelines using multiple processing platforms. Besides translating the users pipelines to the underlying processing platforms, the optimizer decides on what is the best way to perform a pipeline so that runtime is improved as well as on how to move data from one processing platform (or cloud provider) to another one.
Blossom Cross-Platform Executor
Blossom also comes with a cloud-native cross-platform executor, which allows users to deploy their federated data analytics on any cloud provider and data processing platform available. They can choose their preferred cloud provider/data processing platform or let Blossom select the best cloud provider (data processing platform) based on their time and monetary budget. In both cases, Blossom deploys and execute users’ federated pipelines on their behalf.
More importantly,?the executor takes care of any data transfer that must occur among cloud providers and data processing platforms. While the optimizer decides which data must be moved, the executor ensures the efficient movement of the data among different providers and data processing platforms.
Conclusion
Thanks to its design, optimizer, and executor, Blossom can provide a real federated data?lake house?analytics framework from the beginning:
References
[1]?Alon Y. Halevy,?Peter Norvig,?Fernando Pereira:?The Unreasonable Effectiveness of Data.?IEEE Intell. Syst.?24(2):?8-12?(2009).
[2]?Diego Peteiro-Barral,?Bertha Guijarro-Berdi?as:?A survey of methods for distributed machine learning.?Prog. Artif. Intell.?2(1):?1-11?(2013).
[3]?Brendan McMahan,?Daniel Ramage:?Federated Learning: Collaborative Machine Learning without Centralized Training Data. Google AI Blog.?April 6, 2017.
[4]?Dennis Heimbigner,?Dennis McLeod:?A Federated Architecture for Information Management.?ACM Trans. Inf. Syst.?3(3):?253-278?(1985).
[5]?General Data Protection Regulation (GDPR): https://gdpr-info.eu/
[6]?California Consumer Privacy Act (CCPA):?https://oag.ca.gov/privacy/ccpa
[7] TensorFlow Federated: https://www.tensorflow.org/federated
[8] Flower: https://flower.dev/
[9] OpenFL: https://www.openfl.org/
[10] Apache Wayang: https://wayang.apache.org/
Working on Federated AI for Smart Enterprises.
3 年Lars Ewe - wouldn’t this be of interested for ya?
Principal Software Engineer at Dremio | Member of Board of Directors of The Apache Software Foundation
3 年Great article indeed !
Ekrem Namazci Begüm Demir Jean-Baptiste Onofré - great article about Apache Wayang