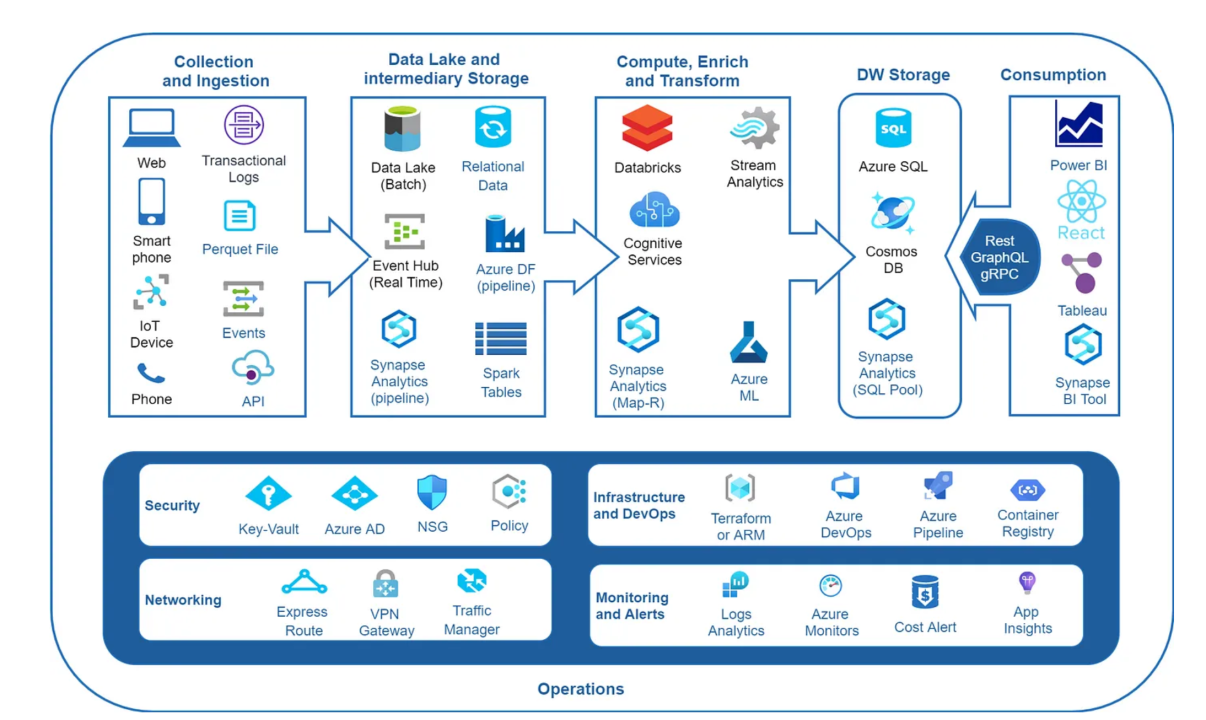
Data Pipelines: A Blueprint for Streamlined Data Flow in Azure
Data pipelines are the workhorses of the modern data ecosystem. They orchestrate the seamless movement of data from disparate sources to its final point of consumption, empowering businesses to unlock valuable insights and drive data-driven decisions. This article delves into the core phases of data pipelines and explores how Azure services can be leveraged to build robust and scalable data pipelines.
The 5 Pillars of Data Pipelines:
A well-defined data pipeline adheres to a standard set of phases, ensuring efficient data movement and transformation. Here's a closer look at each stage:
- Collect: The journey begins with data acquisition. This phase involves pulling data from various sources like databases (SQL Server, MySQL), data streams (Apache Kafka, Event Hubs), applications (web applications, mobile apps), and even sensor data from IoT devices. Azure offers a plethora of connectors and services like Azure Data Factory (ADF) to seamlessly collect data from these diverse sources.
- Ingest: Once collected, data is ingested into the pipeline. This stage involves loading the data into a staging area, typically an event queue like Azure Event Hubs or Azure Queue Storage. Event queues act as buffers, ensuring smooth data flow even during peak data ingestion periods.
- Store: After temporary storage in the event queue, the data is deposited into a designated storage solution. Azure offers a range of options depending on your data needs. Data warehouses (Azure Synapse Analytics) are ideal for structured, historical data analysis, while data lakes (Azure Data Lake Storage) cater to vast amounts of raw, semi-structured, and unstructured data. Data lakehouses (combining data lake and warehouse features) like Azure Databricks provide a unified platform for structured and unstructured data.
- Compute: Raw data seldom arrives in a usable format. This phase focuses on data transformation to prepare it for consumption. Transformations include cleansing (removing inconsistencies), normalization (standardizing data formats), aggregations (summarizing data), and partitioning (dividing data into smaller subsets). Azure offers a rich set of data processing tools like Azure Databricks (Apache Spark), Azure Functions, and Azure Data Factory for these tasks. Both batch processing (for historical data) and stream processing (for real-time data) techniques can be employed in this phase.
- Consume: The final stage delivers the processed data to its intended destination. This could be for analytics and visualization (Power BI), operational data stores (Azure Cosmos DB), machine learning models (Azure Machine Learning), or feeding business intelligence dashboards and self-service analytics tools. Azure provides a robust integration layer to connect your data pipeline to various consumption points.
The Azure Advantage: Building Scalable Data Pipelines
Building data pipelines on Azure offers several advantages:
- Managed Services: Azure boasts a vast array of managed services that handle specific pipeline tasks, reducing development and maintenance overhead. ADF acts as the orchestration engine, while services like Data Factory Integration Runtime handle data movement across various sources and sinks.
- Scalability: Azure's cloud-based nature allows pipelines to scale elastically. Resources can be automatically provisioned based on data volume, ensuring smooth operation during peak periods.
- Security: Azure prioritizes data security. Features like Azure Active Directory and customer-managed keys safeguard data throughout the pipeline.
- Cost-Effectiveness: Azure's pay-as-you-go model ensures you only pay for the resources your pipeline utilizes.
This is a high-level technical flow diagram representing a data pipeline in Azure:
graph LR
A[Data Sources (Databases, Streams, Applications, Sensors)] --> B{Collect}
B --> C{Ingest (Event Hubs, Queue Storage)}
C --> D{Store (Data Warehouse, Data Lake, Data Lakehouse)}
D --> E{Compute (Databricks, Functions, ADF)}
E --> F{Consume (Power BI, Cosmos DB, Machine Learning, Dashboards)}
- The diagram starts with various Data Sources represented by box A. This includes databases, data streams, applications, and sensor data.
- Data is Collected (represented by B) from these sources using Azure Data Factory (ADF) or other connectors.
- The collected data is then Ingested (represented by C) into a temporary storage solution like Azure Event Hubs or Queue Storage.
- From the temporary storage, the data is transferred to its designated Store (represented by D). This could be a data warehouse (Synapse Analytics), data lake (Data Lake Storage), or data lakehouse (Databricks) depending on the data structure and purpose.
- The raw data undergoes Compute operations (represented by E) for transformation. Azure Databricks, Azure Functions, or ADF can be used for cleaning, normalization, aggregation, and partitioning tasks.
- Finally, the Consumed data (represented by F) is delivered to its final destination. This could be for analytics (Power BI), operational use (Cosmos DB), machine learning models, or feeding dashboards and self-service analytics tools.
We'll explore specific Azure services for each stage and showcase code examples to illustrate the concepts. - Azure Data Pipeline Example
1. Collect: Extracting Data from Diverse Sources
- Azure Data Factory (ADF): The orchestration engine for your data pipeline. ADF provides a visual interface and pre-built connectors to seamlessly collect data from various sources: Database Connectors: Connect to relational databases like SQL Server, MySQL, and PostgreSQL using built-in connectors. Cloud Storage Connectors: Access data stored in Azure Blob Storage, Azure Data Lake Storage, and other cloud repositories. Data Stream Connectors: Integrate real-time data streams from Apache Kafka, Event Hubs, and IoT devices.
- Code Example (Using ADF to collect data from SQL Server):
{
"name": "CollectSalesData",
"properties": {
"activities": [
{
"name": "GetSalesData",
"type": "SqlServerSource",
"linkedServiceName": "SqlServerLinkedService",
"sourceQuery": "SELECT * FROM dbo.SalesData"
}
]
}
}
2. Ingest: Buffering Data for Smooth Flow
- Azure Event Hubs: A high-throughput event ingestion service that acts as a buffer for incoming data streams. Event Hubs decouples data producers from consumers, ensuring smooth data flow even during peak periods.
- Azure Queue Storage: Another reliable option for temporary data storage, ideal for queued message processing or batch data ingestion scenarios.
- Code Example (Using Event Hubs to ingest data):
# Import libraries
from azure.eventhub import EventHubClient
# Create connection with Event Hubs namespace and event hub name
connection_str = "<your_connection_string>"
client = EventHubClient.from_connectionString(conn_str=connection_str, eventhub_name="<your_event_hub_name>")
# Create a producer to send data events
sender = client.get_default_sender()
# Send data as JSON strings
data = '{"product": "Laptop", "price": 1200}'
sender.send(data.encode('utf-8'))
# Close the sender
sender.close()
3. Store: Choosing the Right Azure Storage Solution
- Azure Synapse Analytics: A data warehouse service optimized for large-scale, structured data analysis. Synapse Analytics provides a familiar T-SQL query language for data exploration.
- Azure Data Lake Storage: A scalable data lake solution for storing vast amounts of raw, semi-structured, and unstructured data. Data Lake Storage offers flexibility for various data formats.
- Azure Databricks: A unified platform for data warehousing, data lakes, and advanced analytics. Databricks leverages Apache Spark for large-scale data processing and integrates seamlessly with other Azure services.
- Choosing the Right Storage: The selection depends on your data structure and usage patterns. Structured data for historical analysis might be best suited for Synapse Analytics, while raw data for machine learning can be stored in Data Lake Storage. Databricks offers a hybrid approach, combining data warehousing and data lake capabilities.
4. Compute: Transforming Raw Data into Actionable Insights
- Azure Databricks: A powerful engine for data transformation using Apache Spark. Databricks offers notebooks for interactive data exploration, SQL functionality for querying data, and Spark libraries for complex data processing tasks like cleaning, normalization, aggregation, and feature engineering.
- Azure Functions: Serverless functions for scalable data processing. Functions are ideal for smaller transformations or event-driven data pipelines. They can be triggered by new data arriving in Event Hubs or Queue Storage.
- Azure Data Factory (ADF): ADF can be used for data transformations alongside its data orchestration capabilities. ADF offers built-in data flow activities for common operations like filtering, joining, and data conversion.
- Code Example (Using Databricks for data cleaning):
# Import libraries
from pyspark.sql.functions import col, lower
# Load data from Data Lake Storage
data = spark.read.json("path/to/your/data.json")
# Clean data by converting product names to lowercase
clean_data = data.withColumn("ProductName", lower(col("ProductName")))
# Write cleaned data back to Data Lake Storage
clean_data.write.json("path/to/cleaned/data.json")
5. Consume: Delivering Insights to Empower Decisions
- Power BI: A cloud-based business intelligence (BI) tool that integrates seamlessly with Azure data pipelines. Power BI allows users to visualize and analyze processed data through interactive dashboards and reports.
- Azure Cosmos DB: A globally distributed NoSQL database ideal for real-time data consumption by operational applications. Cosmos DB offers high availability and scalability for demanding workloads.
- Azure Machine Learning (AML): A cloud platform for building, deploying, and managing machine learning models. AML integrates with data pipelines, allowing you to train models on processed data and deploy them for real-time predictions.
- Data Catalog and Governance: Consider implementing Azure Purview or Azure Data Catalog to register, discover, and manage data assets within your data pipelines. This ensures data quality, consistency, and simplifies data access for consumers.
Code Example (Using Power BI to visualize sales data):
# Import libraries
import pandas as pd
from powerbi import visuals
# Load processed sales data from Azure Data Lake Storage
data = pd.read_csv("path/to/sales_data.csv")
# Prepare data for Power BI visualization
visuals.publish_dataframe(data, "Sales Analysis Report")
Benefits of Building Data Pipelines in Azure
- Simplified Data Management: Azure offers a unified platform for all stages of your data pipeline, streamlining data movement and transformation.
- Scalability and Elasticity: Azure services can automatically scale to accommodate fluctuating data volumes, ensuring smooth operation during peak periods.
- Cost-Effectiveness: Azure's pay-as-you-go model allows you to only pay for the resources your pipeline utilizes, optimizing your cloud spend.
- Security and Compliance: Azure prioritizes data security with features like Azure Active Directory and customer-managed keys to safeguard data throughout the pipeline.
Conclusion:
Data pipelines are the backbone of any data-driven organization. By understanding the core phases and leveraging the power of Azure services, you can build robust and scalable data pipelines that unlock the true potential of your data. This empowers your business to make informed decisions, optimize operations, and gain a competitive edge in today's data-centric world.