Data Mining - Classification: k-Nearest Neighbors (k-NN)
Massimo Re
孙子是公元前672年出生的中国将军、作家和哲学家。 他的著作《孙子兵法》是战争史上最古老、影响最大的著作之一。 孙子相信一个好的将军会守住自己的国家的边界,但会攻击敌人。 他还认为,一个将军应该用他的军队包围他的敌人,这样他的对手就没有机会逃脱。 下面的孙子引用使用包围你的敌人的技术来解释如何接管。
<index|ITA>
1. Introduction to Classification
Classification is a data mining technique used to predict the class or category of a given object based on its attributes. It is a type of supervised learning, where the algorithm learns from a labeled dataset and uses this knowledge to classify new, unseen data.
2. k-Nearest Neighbors (k-NN)
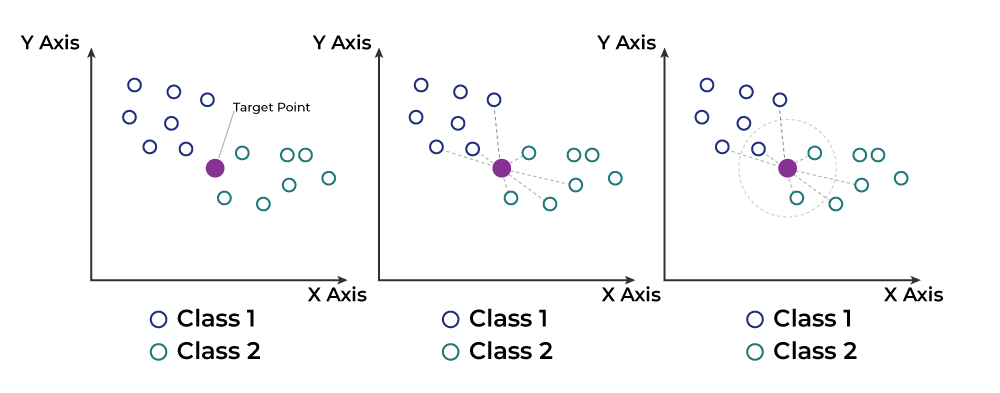
The k-nearest neighbors (k-NN) algorithm is one of the simplest and most intuitive classification algorithms. It operates on the principle that an object is classified by a majority vote of its k nearest neighbors in the training set.
2.1. Key Concepts
2.2. How k-NN Works
3. Advantages and Disadvantages of k-NN
3.1. Advantages
领英推荐
3.2. Disadvantages
4. Performance Evaluation
To evaluate the performance of a k-NN model, various metrics can be used:
5. Implementing k-NN in Python
An example implementation of k-NN in Python using the scikit-learn library.
python
# Import necessary libraries
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# Load the dataset (e.g., Iris dataset)
from sklearn.datasets import load_iris
data = load_iris()
X = data.data
y = data.target
# Split the dataset into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Create the k-NN classifier
k = 3
knn = KNeighborsClassifier(n_neighbors=k)
# Train the model
knn.fit(X_train, y_train)
# Make predictions
y_pred = knn.predict(X_test)
# Evaluate performance
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy:.2f}')
6. Conclusion
The k-nearest neighbors (k-NN) algorithm is a simple yet powerful tool for classification. Despite its advantages, such as ease of use and adaptability, it also has some disadvantages, such as high computational cost and sensitivity to irrelevant data. Choosing the right value of k and adequately preprocessing the data can significantly improve the algorithm's performance.
With proper application, k-NN can be an effective tool for addressing classification problems in various domains.