Collaborative filtering: How to build a recommender system
This post was written by Justin Cechmanek, a Senior Applied AI Engineer at Redis, and originally appeared on Redis' blog.
When users sit down to watch a movie on Netflix, they face a problem untold numbers of Netflix users have faced before: What to watch next? Luckily, the fact that so many users face this problem yet watch another one provides a solution: Collaborative filtering.
With collaborative filtering, recommender systems—often powered by machine learning, deep learning, and artificial intelligence—can use interactions from different users, like ratings, to inform recommendations for other users.
In an ideal world, this looks like magic. A user opens up Netflix, and without realizing it, a similar user selected a movie previously, and that decision helps the recommendation algorithm to infer what the original user might like.?
But under the hood, collaborative filtering is anything but magic.?
What is collaborative filtering?
Collaborative filtering was one of the first approaches used to build recommender systems. Collaborative filtering, at its core, relies on user interactions, such as user ratings, user likes, user dislikes, and purchases, to make recommendations.?
Collaborative filtering gets its name from the way this approach allows users to “collaborate” with each other via implicit feedback. One user doesn’t need to know the other to help them by rating a movie highly so that the system can recommend it to the next user.?
It’s tempting to think of recommender systems—the behind-the-scenes tools that seem to magically know what users want to buy, watch, or see next—as entirely modern systems. But recommender systems emerged long before AI, machine learning, and algorithm competitions.?
The first recommender system emerged soon after the initial invention of the World Wide Web. While other, more visible systems and concepts have swept over the industry and then been swept away by newer systems and concepts, recommender systems have remained. Over the years, the sophistication of the technologies involved has evolved dramatically, but the challenge of recommending new things to engaged users has always been a challenge.?
Collaborative filtering is split into two approaches: User-user and item-item.?
In user-user (or user-based) approaches, the recommender system predicts a user’s preferences by finding other users with similar interests or tastes and then recommending similar items on that basis. In item-item (or item-based) approaches, the recommender system uses matrix factorization to suggest new items to users based on how similar those new items are to the previous items they’ve already demonstrated interest in.??
Collaborative filtering vs. content-based filtering
Collaborative filtering is not the only approach to building recommender systems.?
Content-based filtering, unlike collaborative filtering, which focuses on users, focuses on the content of the items being recommended. In content-based filtering, machine learning algorithms suggest similar items to users based on the content of these items. These recommender systems build user profiles over time and match new items to those profiles with the hopes that users like them, too.?
Collaborative filtering, in contrast, focuses on users instead of items and uses explicit feedback from users rather than implicit metadata regarding the items.?
Advantages and disadvantages of collaborative filtering
There are advantages and disadvantages to each approach, but many recommender systems use both and treat them as complementary (such as when building hybrid recommender systems). Whether you emphasize one over the other or combine them both, knowing the tradeoffs of each is essential to building a modern recommender system.?
Advantages of collaborative filtering
Collaborative filtering has numerous advantages that have made it a long-standing part of recommender systems over the years:?
Despite these compelling advantages, collaborative filtering isn’t without its disadvantages.?
Disadvantages
Collaborative filtering has some major tradeoffs that companies investing in it need to consider, especially younger companies with newer networks.??
The advantages and disadvantages described above carry more weight once implemented, which you can see via use cases and examples.?
Use cases for collaborative filtering
The use cases for collaborative filtering are broad and diverse. Like content-based filtering, collaborative filtering (and all other recommender system techniques) face the same persistent problem: Online, there are always too many options, and too many options lead users to analysis paralysis.?
Anywhere that dynamic is possible, you’re likely to find recommender systems and, often, collaborative filtering in particular.?
Collaborative filtering is an old idea (at least in technology terms), and the industry’s methods of building with it and iterating on it have changed over the years. Learning to build a collaborative filtering system yourself is a great first step to building, or at least better understanding, how modern recommender systems work.?
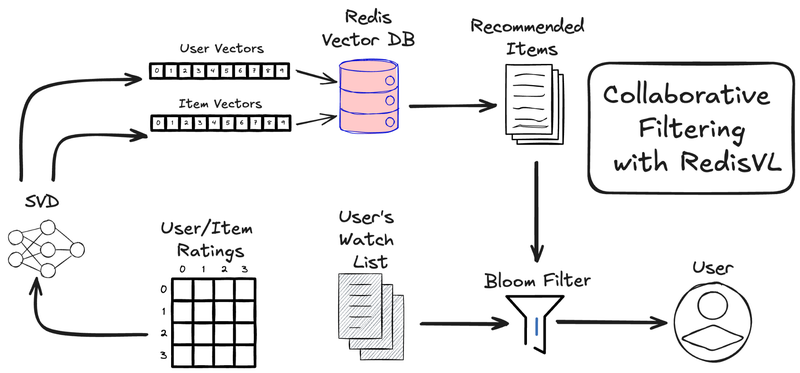
How to build a collaborative filtering system with Redis
With Redis, you use real-time, low-latency capabilities to build scalable, AI-powered recommendation systems. In environments where real-time data processing is necessary to make the best recommendations, Redis’ sub-millisecond response times and vector database capabilities can help you deliver seamless user experiences.
Here, we’ll walk through how to build a movie recommendation system supported by collaborative filtering using RedisVL and the IMDB movie dataset.
You can run it yourself or clone the repo here.
The algorithm we’ll be using is the Singular Value Decomposition, or SVD, algorithm. It works by looking at the average ratings users have given to movies they have already watched. Below is a sample of what that data might look like.?
Unlike content filtering, which is based on the features of the recommended items, collaborative filtering looks at the user’s ratings and only the user’s ratings.
Singular value decomposition
It’s worth going into more detail about why we chose this algorithm and what it is computing in the methods we’re calling.?
First, let’s think about what data it’s receiving—our ratings data. This only contains the user IDs, movie IDs, and the user’s ratings of the movies they watched on a scale of 0 to 5. We can put this data into a matrix with rows being users and columns being movies.
Our empty cells are missing ratings—not zeros—so user 1 has never rated movie 3. They may like it or hate it.
Unlike content-based filtering, here, we only consider the ratings that users assign. We don’t know the plot, genre, or release year of any of these films. However, we can still build a recommender by assuming that users have tastes similar to each other.?
As an intuitive example, we can see that user 1 and user 4 have very similar ratings on several movies, so we can assume that user 4 will rate movie 6 highly, just as user 1 did.?
Since we only have this matrix to work with, what we want to do is decompose it into two constituent matrices.
Let’s call our ratings matrix [R]. We want to find two other matrices, a user matrix [U] and a movies matrix [M], that fit the equation:
[U] * [M] = [R]
[U] will look like:
[M] will look like:
These features are the latent features (or latent factors) and are the values we’re trying to find when we call the svd.fit(train_set) method. The algorithm that computes these features from our ratings matrix is the SVD algorithm.?
Our data sets the number of users and movies. The size of the latent feature vectors k is a parameter we choose. We’ll keep it at the default 100 for this notebook.
A look at the code
Grab the ratings file and load it up with Pandas.
A lot is going to happen in the code cell below. We split our full data into train and test sets. We define the collaborative filtering algorithm to use, which in this case is the Singular Value Decomposition (SVD) algorithm. Lastly, we fit our model to our data.
Extract the user and movie vectors
Now that the SVD algorithm has computed our [U] and [M] matrices, which are both just lists of vectors, we can load them into our Redis instance. The Surprise SVD model stores user and movie vectors in two attributes:
svd.pu: user features matrix—a matrix where each row corresponds to the latent features of a user).
svd.qi: item features matrix—a matrix where each row corresponds to the latent features of an item/movie).
It’s worth noting that the matrix svd.qi is the transposition of the matrix [M] we defined above. This way, each row corresponds to one movie.
Predict user ratings in one step
The great thing about collaborative filtering is that using our user and movie vectors, we can predict the rating any user will give to any movie in our dataset. And unlike content filtering, there is no assumption that all the movies a user will be recommended are similar to each other. A user can get recommendations for dark horror films and light-hearted animations.
Looking back at our SVD algorithm, the equation is:
[User_features] * [Movie_features].transpose = [Ratings]
To predict how a user will rate a movie they haven’t seen yet, we just need to take the dot product of that user’s feature vector and a movie’s feature vector.
Add movie metadata to our recommendations
While our collaborative filtering algorithm was trained solely on users’ ratings of movies and doesn’t require any data about the movies themselves, such as the title, genre, or release year, we’ll want that information stored as metadata.
We can grab this data from our `movies_metadata.csv` file, clean it, and join it to our user ratings via the `movieId` column.
We’ll have to map these movies to their ratings, which we’ll do so with the `links_small.csv` file that matches `movieId`, `imdbId`, and `tmdbId`.
We’ll want to move our SVD user vectors and movie vectors and their corresponding userId and movieId into two dataframes for later processing.
RedisVL handles the scale
Especially for large datasets like the 45,000 movie catalog, like the one we’re dealing with here, you’ll want Redis to do the heavy lifting of vector search. All that you need is to define the search index and load the data we’ve cleaned and merged with our vectors.
For a complete solution, we’ll store the user vectors and their watched list in Redis, too. We won’t be searching over these user vectors, so there is no need to define an index for them. A direct JSON look up will do.
Unlike in content-based filtering, where we want to compute vector similarity between items and use cosine similarity between items vectors to do so, in collaborative filtering, we instead try to compute the predicted rating a user will give to a movie by taking the inner product of the user and movie vector.?
This is why, in our schema definition, we use ‘ip’ (inner product) as our distance metric. It’s also why we’ll use our user vector as the query vector when we do a query. The distance metric ‘ip’ inner product is computing:
vector_distance = 1 – u * v ?
And it’s returning the minimum, which corresponds to the max of u * v. This is what we want. The predicted rating on a scale of 0 to 5 is then:
predicted_rating= -(vector_distance-1) = –vector_distance +1
Let’s pick a random user and their corresponding user vector to see what this looks like.
Add all the bells and whistles
Vector search handles the bulk of our collaborative filtering recommendation system and is a great approach to generating personalized recommendations that are unique to each user.?
To up our RecSys game even further, we can use RedisVL Filter logic to get more control over what users are shown. Why have only one feed of recommended movies when you can have several, each with its own theme and personalized to each user?
Keep things fresh with Bloom filters
You’ve probably noticed that a few movies get repeated in these lists. That’s not surprising as all our results are personalized, and things like popularity, rating, and revenue are likely highly correlated. And it’s more than likely that at least some of the recommendations we’re expecting to be highly rated by a given user are ones they’ve already watched and rated highly.
We need a way to filter out movies that a user has already seen and movies that we’ve already recommended to them before. We could use a Tag filter on our queries to filter out movies by their ID, but this gets cumbersome quickly.?
Luckily, Redis offers an easy answer to keeping recommendations new and interesting: Bloom Filters.
Get started with RedisVL
Now you know the basics of collaborative filtering, the advantages and disadvantages of this approach, a range of use cases and examples, and how to build a collaborating filtering system using RedisVL.?
With Redis and RedisVL, it only takes a few steps to build a highly scalable, personalized, customizable collaborative filtering recommendation system. Be sure to check out how to build a content-filtering recommendation system if you’re curious about how to do the same for content-based filtering.?
Try Redis for free or book a demo to see collaborative filtering and recommender systems in action.