The Cheapest Way to Deploy an AI Model on AWS ?
Georges Awono
Cloud Architect for Data & AI Platforms - Transforming Business Goals to Technical Strategies ?
Imagine you run a small e-commerce company and want to integrate image recognition into your workflow. For example, you might want to analyze product images uploaded by customers to categorize them or detect defects in photos. The challenge? You need this AI model to be accessible, efficient, and most importantly, you have a very low budget !
Today we are going to explore an architecture that will allow you to deploy your AI model for less than 2$ per month !
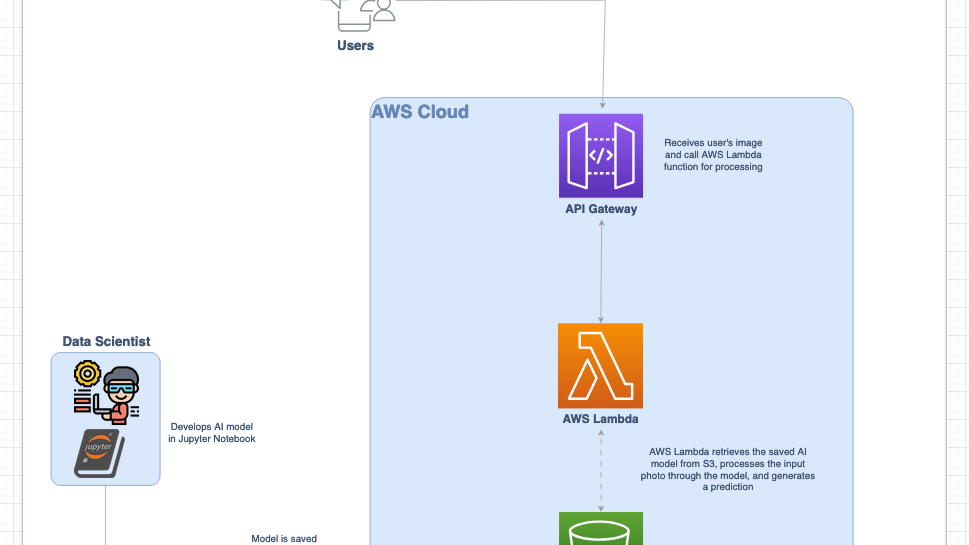
Without further due, here is our final architecture :?
Let’s dive deeper into the architecture and its components.
From Notebook to S3: Prepare and serialize (saved) Your AI Model
The story starts with your data scientist developing the AI model in a jupyter notebook. The data scientist validates his model and now you want it live, ready to make predictions according to the photo your users will upload.?
The first step is to serialize the model, in other words save your model as an object.?
Model serialization is the process of converting a trained machine learning model into a format that can be saved as a physical file. This step is crucial for deploying your model because it allows you to store the model’s structure, parameters, and weights in a way that other applications can load and use later.?
Common serialization formats include pickle and joblib for Python-based models. These formats capture everything needed to reconstruct the model, making it easy to transfer and deploy in production environments. For example, after training an image recognition model in a Jupyter notebook, you would serialize it into a file and upload it to a storage service like Amazon S3, where it becomes accessible for inference tasks. Serialization ensures that your model is portable, reusable, and ready to be integrated into deployment workflows
Upload to S3: Once serialized, upload the model file to an Amazon S3 bucket. This serves as your central storage, where it’s accessible to the Lambda function when needed.
Amazon API Gateway: Create RESTful APIs easily
API Gateway is an AWS service that allows us to build APIs very easily. It exposes a RESTful API endpoint where our users can send requests (like uploading an image) and receive predictions.
API Gateway creates RESTful APIs that :?
API Gateway handles all the tasks involved in accepting and processing up to hundreds of thousands of concurrent API calls. These tasks include traffic management, authorization and access control, monitoring, and API version management.?
What I like the most about API Gateway, is its native lambda integration. In a few clicks, you can create an API, create a route and assign a lambda function to handle the request. For example, here, I have created an API named “mytestapi”, with an integration with a lambda function named “MyLambdaToCallAIModel”. Each time a user will send a POST request to my API, at “/predict” path, my lambda function will be called and will receive as input the payload (here an image) of the user’s post request.?
API Gateway lets you add caching to your APIs by provisioning a cache and setting its size in gigabytes. This means responses from your endpoints can be cached, reducing the number of calls to your backend and improving the speed of API requests.
You can also use API Gateway to implement throttling. Throttling allows you to set limits on how many requests your API can handle, both in terms of concurrent requests and burst requests. If the limit is exceeded, users will receive a “429 Too Many Requests” response. This helps protect your backend from being overwhelmed by high traffic.
AWS Lambda: Serverless Model Execution
AWS Lambda allows you to run your AI model without provisioning or managing servers. Here’s how it works in this architecture:
The keys benefits of using AWS Lambda include Pay-as-you-go pricing model : you are only charged for the compute time used; and no need to manage infrastructure as Lambda scales up and down based on demand.?
Final Architecture
Here is a final view of our AI model deployment architecture :?
Together, these services allow you to deploy an AI model with minimal upfront cost and a pay-as-you-go model that scales with your business needs.
This architecture is perfect for businesses looking to integrate machine learning into their workflows without breaking the bank. Whether you’re building an image recognition system or any other AI-powered service, this approach ensures you get started quickly, efficiently, and affordably.
#Cloud #AI #AWS #APIGateway #S3 #Lambda