Building Resilient and Fault-Tolerant Systems: An In-Depth Guide
In distributed systems, failures are inevitable. A resilient and fault-tolerant system can continue to function despite failures, ensuring high availability and minimal service disruption. In this blog, we will explore key concepts, patterns, and strategies for building resilient systems, backed by code examples.
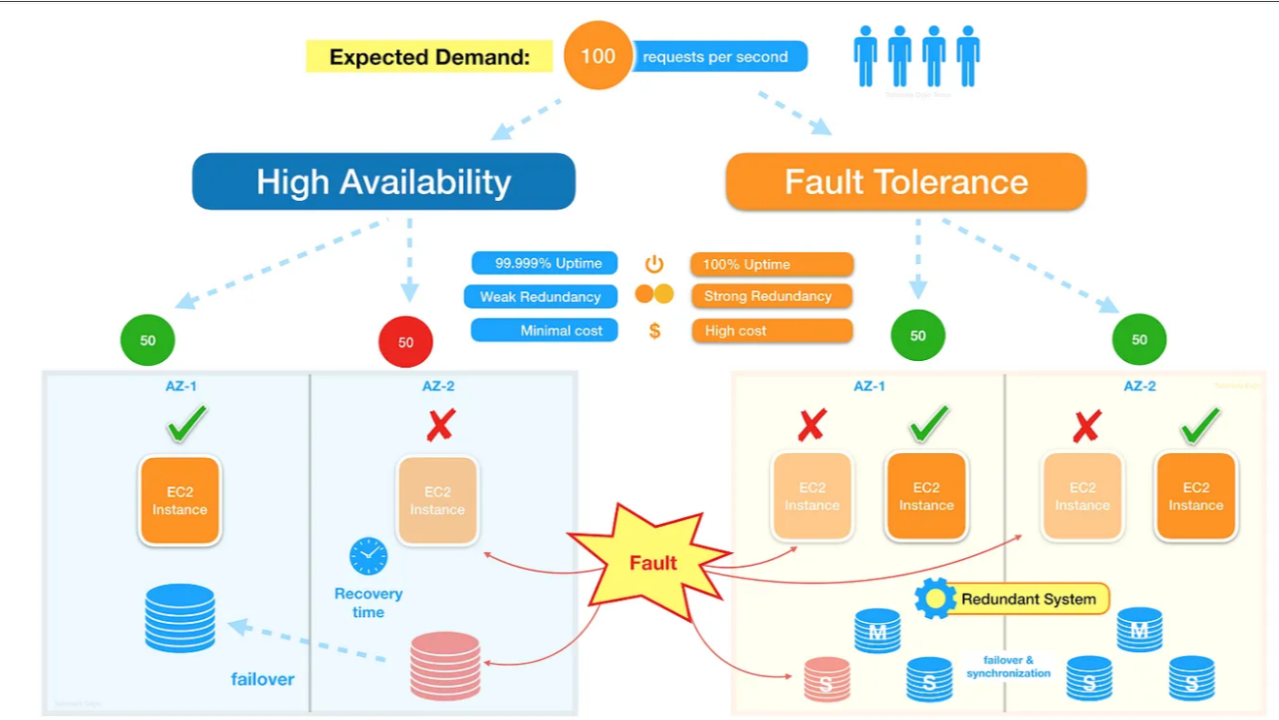
1. Understanding Resilience vs. Fault Tolerance
A resilient system can fail gracefully, while a fault-tolerant system can handle faults without the end user noticing. Both are essential to creating robust applications.
2. Circuit Breaker Pattern
The Circuit Breaker Pattern prevents a system from repeatedly invoking a failing service. When a service call fails, the circuit "opens," allowing time for the service to recover.
Code Example: Implementing Circuit Breaker with Resilience4j
@RestController
@RequestMapping("/api/v1/orders")
public class OrderController {
private final OrderService orderService;
@Autowired
public OrderController(OrderService orderService) {
this.orderService = orderService;
}
@GetMapping("/{id}")
@CircuitBreaker(name = "orderService", fallbackMethod = "fallbackGetOrder")
public ResponseEntity<OrderDTO> getOrder(@PathVariable("id") Long orderId) {
return ResponseEntity.ok(orderService.getOrderById(orderId));
}
// Fallback method in case of failure
public ResponseEntity<OrderDTO> fallbackGetOrder(Long orderId, Throwable throwable) {
// Return a cached or default response
return ResponseEntity.status(HttpStatus.SERVICE_UNAVAILABLE)
.body(new OrderDTO("Default Order", 0));
}
}
3. Retries and Exponential Backoff
Sometimes failures are transient, and retrying a failed request may succeed. However, naive retries can overwhelm services, so it’s essential to implement exponential backoff to space out retries.
Code Example: Retry with Exponential Backoff using Spring Retry
@Service
public class PaymentService {
@Retryable(
value = { RemoteServiceException.class },
maxAttempts = 5,
backoff = @Backoff(delay = 2000, multiplier = 2))
public Payment processPayment(Long orderId) throws RemoteServiceException {
return externalPaymentGateway.process(orderId);
}
@Recover
public Payment fallbackProcessPayment(Long orderId, RemoteServiceException ex) {
return new Payment("Failed", orderId);
}
}
4. Timeouts and Fail Fast Mechanism
Long-running processes should have timeouts in place to prevent them from blocking resources indefinitely. Coupled with a fail-fast approach, you can ensure the system avoids cascading failures.
Code Example: Setting Timeouts in RestTemplate
@Bean
public RestTemplate restTemplate() {
SimpleClientHttpRequestFactory factory = new SimpleClientHttpRequestFactory();
factory.setConnectTimeout(5000); // 5 seconds connection timeout
factory.setReadTimeout(5000); // 5 seconds read timeout
return new RestTemplate(factory);
}
Timeouts ensure that if a downstream service is unresponsive, the system moves on rather than waiting indefinitely.
5. Bulkhead Pattern
The Bulkhead Pattern isolates components so that a failure in one part of the system doesn't take down the entire service. You can think of this as limiting resource usage per service, preventing one service from overwhelming others.
Code Example: Bulkhead with Resilience4j
@RestController
@RequestMapping("/api/v1/products")
public class ProductController {
private final ProductService productService;
@Autowired
public ProductController(ProductService productService) {
this.productService = productService;
}
@GetMapping("/{id}")
@Bulkhead(name = "productService", type = Bulkhead.Type.SEMAPHORE, fallbackMethod = "fallbackGetProduct")
public ResponseEntity<ProductDTO> getProduct(@PathVariable("id") Long productId) {
return ResponseEntity.ok(productService.getProductById(productId));
}
public ResponseEntity<ProductDTO> fallbackGetProduct(Long productId, Throwable throwable) {
return ResponseEntity.status(HttpStatus.SERVICE_UNAVAILABLE)
.body(new ProductDTO("Default Product", "Default Description"));
}
}
6. Fallback Mechanisms
In a distributed system, failures in downstream services are inevitable. Implementing fallback mechanisms ensures that the system can degrade gracefully by providing default responses or alternative services.
领英推荐
Code Example: Fallback with Hystrix
@RestController
@RequestMapping("/api/v1/inventory")
public class InventoryController {
private final InventoryService inventoryService;
@Autowired
public InventoryController(InventoryService inventoryService) {
this.inventoryService = inventoryService;
}
@GetMapping("/{id}")
@HystrixCommand(fallbackMethod = "fallbackInventory")
public ResponseEntity<InventoryDTO> getInventory(@PathVariable("id") Long productId) {
return ResponseEntity.ok(inventoryService.getInventory(productId));
}
public ResponseEntity<InventoryDTO> fallbackInventory(Long productId) {
return ResponseEntity.status(HttpStatus.SERVICE_UNAVAILABLE)
.body(new InventoryDTO(productId, 0));
}
}
7. Load Balancing
Distributing traffic across multiple instances of a service reduces the risk of failure and improves system performance. In Spring Boot, Ribbon or Spring Cloud LoadBalancer can be used to distribute load across services.
Code Example: Load Balancing with Ribbon
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}
public InventoryDTO getInventory(Long productId) {
return restTemplate.getForObject("https://inventory-service/api/v1/inventory/" + productId, InventoryDTO.class);
}
8. Graceful Degradation with Feature Flags
In cases of partial service failures, it's important to degrade gracefully. By using feature flags, you can dynamically enable or disable features based on system health or failures.
Code Example: Feature Flag with Togglz
if (Features.SHOW_INVENTORY.isActive()) {
return inventoryService.getInventory(productId);
} else {
return new InventoryDTO(productId, "Feature Disabled");
}
9. Self-Healing Systems
A self-healing system detects faults and attempts to recover automatically. This can be achieved through health checks and automatic restarts of failed services.
Code Example: Health Checks with Spring Boot Actuator
management:
endpoints:
web:
exposure:
include: health, info
10. Chaos Engineering
To truly understand how resilient and fault-tolerant a system is, chaos engineering practices should be employed. Simulating failures in a controlled environment allows teams to identify weaknesses in the system.
Code Example: Chaos Monkey for Spring Boot
chaos:
monkey:
enabled: true
assaults:
latencyRangeStart: 1000
latencyRangeEnd: 5000
Conclusion
Building resilient and fault-tolerant systems is crucial in distributed architectures. The patterns and strategies discussed—circuit breakers, retries with backoff, timeouts, bulkheads, and more—allow us to mitigate the impact of failures, ensuring that systems continue to function under adverse conditions. Coupled with tools like Resilience4j, Hystrix, and Spring Boot Actuator, you can build systems that not only handle failure but recover from them gracefully.
Resilience isn’t a feature; it’s a design philosophy that needs to be embedded into every layer of your architecture to build robust, fault-tolerant systems.