Building a Real-Time Streaming Data Pipeline with Python, Docker, Kafka, Spark, Airflow, and Cassandra
Big companies like Netflix, Uber, and LinkedIn use real-time streaming data pipelines to enhance user experience, deliver personalized recommendations, and optimize operations. By leveraging technologies like Apache Kafka, Spark, and Cassandra, they process and analyze data instantly, providing crucial insights.
In this project, we’ll recreate a similar end-to-end real-time streaming solution using Python, Docker, Kafka, Spark, Airflow, and Cassandra. You’ll learn how to build a pipeline that retrieves data from an API, processes it in real-time, and stores it for analysis — demonstrating the power of modern streaming technologies.
Project Workflow Overview
The data pipeline will consist of the following stages:
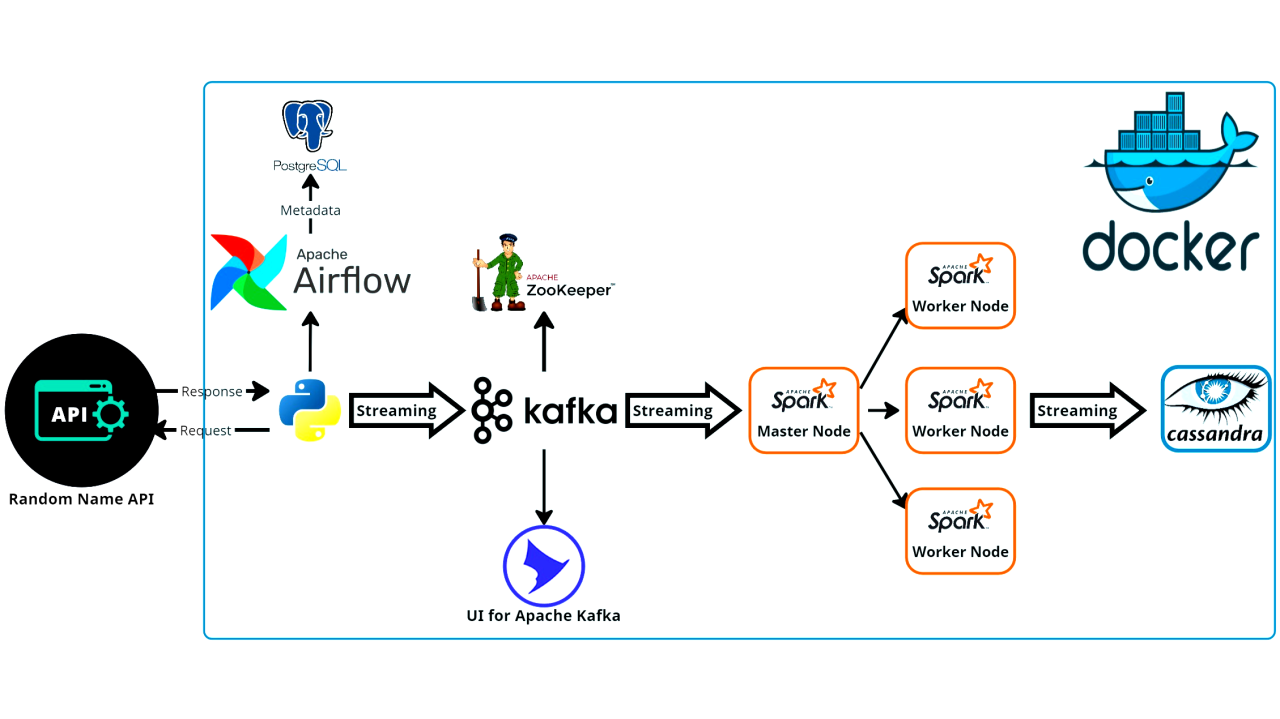
System Architecture
The architecture includes the following components:
Getting Started
Prerequisites
Ensure that Docker and Docker Compose are installed on your machine.
Clone the Repository
Begin by cloning the project repository:
https://github.com/mdvohra/End-to-End-Realtime-Streaming-Data-Engineering-Project.git
cd End-to-End-Realtime-Streaming-Data-Engineering-Project
Set Up the Environment (Linux/WSL)
Create an .env file to set the necessary configurations for Airflow, and make the entrypoint script executable:
echo -e "AIRFLOW_UID=$(id -u)" > .env
chmod +x script/entrypoint.sh
The project structure includes two folders and several files:
├── dags
│ └── kafka_stream.py
├── docker-compose.yaml
├── requirements.txt
├── dependencies.zip
├── script
│ └── entrypoint.sh
└── spark_stream.py
The entrypoint.sh file contains the commands to be executed after the container is initialized. To ensure it functions correctly, it is recommended to run chmod +x scripts/entrypoint.sh from the root directory to make the script executable.
#!/bin/bash
set -e
if [ -e "/opt/airflow/requirements.txt" ]; then
python -m pip install --upgrade pip
pip install -r requirements.txt
fi
if [ ! -f "/opt/airflow/airflow.db" ]; then
airflow db migrate && \
airflow users create \
--username admin \
--firstname admin \
--lastname admin \
--role Admin \
--email [email protected] \
--password admin
fi
$(command -v airflow) db upgrade
exec airflow webserver
Below is the content of the docker.yaml used to orchestrate the setup process.
x-airflow-common:
&airflow-common
image: ${AIRFLOW_IMAGE_NAME:-apache/airflow:2.9.3}
environment:
&airflow-common-env
AIRFLOW__CORE__EXECUTOR: LocalExecutor
AIRFLOW__DATABASE__SQL_ALCHEMY_CONN : postgresql+psycopg2://airflow:airflow@postgres:5432/airflow
AIRFLOW__CORE__FERNET_KEY: ''
AIRFLOW__CORE__DAGS_ARE_PAUSED_AT_CREATION: 'true'
AIRFLOW__CORE__LOAD_EXAMPLES: 'false'
AIRFLOW__API__AUTH_BACKENDS: 'airflow.api.auth.backend.basic_auth,airflow.api.auth.backend.session'
AIRFLOW__SCHEDULER__ENABLE_HEALTH_CHECK: 'true'
_PIP_ADDITIONAL_REQUIREMENTS: "kafka-python-ng==2.2.2 ${_PIP_ADDITIONAL_REQUIREMENTS:-}"
and continue......
Airflow Initialization
To initialize the Airflow instance and set up the database, run the following command:
docker-compose up airflow-init
docker compose up -d
Once the Docker containers are up and running, create a new file in the dags directory named stream_kafka.py. Here is the content of the file:
from datetime import datetime
from airflow import DAG
from airflow.operators.python import PythonOperator
import random
default_args = {
'owner': 'admin',
'start_date': datetime(2023, 9, 3, 10, 00)
}
def get_data():
import requests
res = requests.get("https://randomuser.me/api/")
res = res.json()
res = res['results'][0]
return res
def format_data(res):
data = {}
location = res['location']
data['first_name'] = res['name']['first']
data['last_name'] = res['name']['last']
data['gender'] = res['gender']
data['address'] = f"{str(location['street']['number'])} {location['street']['name']}, " \
f"{location['city']}, {location['state']}, {location['country']}"
data['post_code'] = location['postcode']
data['email'] = res['email']
data['username'] = res['login']['username']
data['dob'] = res['dob']['date']
data['registered_date'] = res['registered']['date']
data['phone'] = res['phone']
data['picture'] = res['picture']['medium']
return data
def stream_data():
import json
from kafka import KafkaProducer
import time
import logging
producer = KafkaProducer(bootstrap_servers='broker:9092', max_block_ms=5000)
curr_time = time.time()
while True:
if time.time() > curr_time + 120: #2 minutes
break
try:
res = get_data()
res = format_data(res)
producer.send('users_created', json.dumps(res).encode('utf-8'))
sleep_duration = random.uniform(0.5, 2.0)
time.sleep(sleep_duration)
except Exception as e:
logging.error(f'An error occured: {e}')
continue
with DAG('user_automation',
default_args=default_args,
schedule_interval='@daily',
catchup=False) as dag:
streaming_task = PythonOperator(
task_id='stream_data_from_api',
python_callable=stream_data
)
Go to the Airflow UI at https://localhost:8080, and unpause the user_automation DAG by clicking the switch button in the DAG section.
领英推荐
To view the data streams on Kafka, you can visit https://localhost:8085 in your browser.
In the root directory of the project there is a file called spark_stream.py to read kafka topic named users_created.
import logging
from datetime import datetime
from cassandra.cluster import Cluster
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, from_json
from pyspark.sql.types import StructType, StructField, StringType
# Configure logging
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[logging.StreamHandler()]
)
logger = logging.getLogger(__name__)
def create_keyspace(session):
session.execute("""
CREATE KEYSPACE IF NOT EXISTS spark_streaming
WITH REPLICATION = {'class': 'SimpleStrategy', 'replication_factor': 1}
""")
logger.info("Keyspace created successfully")
def create_table(session):
session.execute("""
CREATE TABLE IF NOT EXISTS spark_streaming.created_users (
first_name TEXT,
last_name TEXT,
gender TEXT,
address TEXT,
post_code TEXT,
email TEXT,
username TEXT PRIMARY KEY,
dob TEXT,
registered_date TEXT,
phone TEXT,
picture TEXT);
""")
logger.info("Table created successfully")
def insert_data(session, **kwargs):
logger.info("Inserting data")
first_name = kwargs.get('first_name')
last_name = kwargs.get('last_name')
gender = kwargs.get('gender')
address = kwargs.get('address')
postcode = kwargs.get('post_code')
email = kwargs.get('email')
username = kwargs.get('username')
dob = kwargs.get('dob')
registered_date = kwargs.get('registered_date')
phone = kwargs.get('phone')
picture = kwargs.get('picture')
try:
session.execute("""
INSERT INTO spark_streaming.created_users (first_name, last_name, gender, address,
post_code, email, username, dob, registered_date, phone, picture)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
""", (first_name, last_name, gender, address,
postcode, email, username, dob, registered_date, phone, picture))
logger.info(f"Data inserted for {first_name} {last_name}")
except Exception as e:
logger.error(f"Error while inserting data: {e}")
def create_spark_connection():
s_conn = None
try:
s_conn = SparkSession.builder \
.appName('SparkDataStreaming') \
.config('spark.jars.packages', "com.datastax.spark:spark-cassandra-connector_2.12:3.5.1,"
"org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.1") \
.config('spark.cassandra.connection.host', 'cassandra_db') \
.getOrCreate()
s_conn.sparkContext.setLogLevel("ERROR")
logger.info("Spark connection created successfully")
except Exception as e:
logger.error(f"Error while creating spark connection: {e}")
return s_conn
def connect_to_kafka(spark_conn):
spark_df = None
try:
spark_df = spark_conn.readStream \
.format('kafka') \
.option('kafka.bootstrap.servers', 'broker:9092') \
.option('subscribe', 'users_created') \
.option('startingOffsets', 'earliest') \
.load()
logger.info("Kafka dataframe created successfully")
except Exception as e:
logger.error(f"Kafka dataframe could not be created because: {e}")
logger.error(f"Error type: {type(e).__name__}")
logger.error(f"Error details: {str(e)}")
import traceback
logger.error(f"Traceback: {traceback.format_exc()}")
if spark_df is None:
logger.error("Failed to create Kafka dataframe")
return spark_df
def create_cassandra_connection():
try:
# Connection to Cassandra cluster
cluster = Cluster(['cassandra_db'])
cas_session = cluster.connect()
logger.info("Cassandra connection created successfully")
return cas_session
except Exception as e:
logger.error(f"Error while creating Cassandra connection: {e}")
return None
def create_selection_df_from_kafka(spark_df):
schema = StructType([
StructField("first_name", StringType(), False),
StructField("last_name", StringType(), False),
StructField("gender", StringType(), False),
StructField("address", StringType(), False),
StructField("post_code", StringType(), False),
StructField("email", StringType(), False),
StructField("username", StringType(), False),
StructField("dob", StringType(), False),
StructField("registered_date", StringType(), False),
StructField("phone", StringType(), False),
StructField("picture", StringType(), False)
])
sel = spark_df.selectExpr("CAST(value AS STRING)") \
.select(from_json(col("value"), schema).alias("data")) \
.select("data.*")
logger.info("Selection dataframe created successfully")
return sel
if __name__ == "__main__":
# Create Spark connection
spark_conn = create_spark_connection()
if spark_conn is not None:
# Create connection to Kafka with Spark
spark_df = connect_to_kafka(spark_conn)
selection_df = create_selection_df_from_kafka(spark_df)
logger.info("Selection dataframe schema:")
selection_df.printSchema()
# Create Cassandra connection
session = create_cassandra_connection()
if session is not None:
create_keyspace(session)
create_table(session)
# Insert data into Cassandra
insert_data(session)
streaming_query = selection_df.writeStream.format("org.apache.spark.sql.cassandra") \
.option('keyspace', 'spark_streaming', ) \
.option('checkpointLocation', '/tmp/checkpoint') \
.option('table', 'created_users') \
.start()
streaming_query.awaitTermination()
session.shutdown()
Prepare Spark and Cassandra
Copy the dependencies and spark_stream files into the Spark container:
docker cp dependencies.zip spark-master:/dependencies.zip
docker cp spark_stream.py spark-master:/spark_stream.py
Access the Cassandra container and verify that there is no keyspace named created_users:
docker exec -it cassandra cqlsh -u cassandra -p cassandra localhost 9042
cqlsh> DESCRIBE KEYSPACES;
Run the Spark job to start processing data:
docker exec -it spark-master spark-submit \
--packages com.datastax.spark:spark-cassandra-connector_2.12:3.5.1,org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.1 \
--py-files /dependencies.zip \
/spark_stream.py
Monitor the Pipeline
Access Airflow UI at https://localhost:8080/ and unpause the user_automation DAG.
Check Cassandra to verify that data is being inserted:
docker exec -it cassandra cqlsh -u cassandra -p cassandra localhost 9042
cqlsh> SELECT * FROM spark_streaming.created_users;
cqlsh> SELECT count(*) FROM spark_streaming.created_users;
Conclusion
Real-time data streaming is a key enabler for businesses to make quick, data-driven decisions and enhance user experience, much like how major companies such as Netflix and Uber do today. In this project, we explored building an end-to-end streaming pipeline using Python, Docker, Kafka, Spark, Airflow, and Cassandra, covering every step from data ingestion to processing and storage.
This pipeline demonstrates the power of integrating these technologies to create a robust data flow that can handle real-time data. Whether you're just getting started in data engineering or seeking to expand your knowledge, this hands-on approach provides a strong foundation to understand how real-time data streaming architectures work and can be implemented in various business contexts. Feel free to explore, modify, and build upon this solution as you embark on your data engineering journey.
Feel free to explore the repository for more details and code.
About the Author
Associate Data Scientist
GenAI
Mohammad Vohra is a passionate data scientist specializing in generative AI and data-driven solutions. He focuses on developing innovative applications that bridge the gap between complex data science and user-friendly experiences. With a keen interest in making advanced technology accessible to all, Mohammad continues to push the boundaries of what’s possible in the field of AI and data science.
Telecommunications | ICT Research & Engineering | Father | Tech.
4 个月Anything, but data processing. Great breakdown.
Software Developer | Digital Health | Data
4 个月Very insightful
M.Sc Data Science and Spatial Analytics | Python | Machine Learning | SQL | PowerBI | Excel
5 个月Very informative
Engineer at ESRI INDIA
5 个月Insightful