Building LLM Solutions using Prompt Engineering, Embeddings, Vector DB, and LangChains
Language Models, especially Large Language Models (LLMs), have evolved into essential tools for comprehending and crafting human language. In this ever-evolving realm of Generative Intelligence, lets go through the complexities of LLMs, navigating token constraints, harnessing embeddings, and leveraging vector databases and innovative prompting techniques. These fundamental elements empower us to explore the expansive domain of language with precision, enhancing the capabilities of AI. Let's explore the intricacies of tokens, embeddings, vectors, and advanced prompts, as we unveil their transformative potential
?? Token: The Fundamental Unit of LLMs
Tokens are the building blocks of LLMs, akin to the words in a dictionary. However, they can be as short as a single character or as long as a word. Tokens are not just words; they can also represent subword units, making them highly flexible. Understanding tokens is crucial because LLMs often come with token limits.
For instance:
- In GPT-3, the token limit is 4,000.
- GPT-4 offers an 8,000 token limit.
- Advanced models like GPT-4(32K) extend the limit further.
It's essential to remember that these token limits encompass both input and output tokens. Exceeding these limits can lead to API failures, so effective token management is critical.
?? Embeddings: Bridging Words and Vectors
Embedding models are the bridge between words and vectors. These models take words or sentences and convert them into vectors, allowing for operations like cosine similarity, which is crucial for similarity search and retrieval.
For example, embeddings enable you to search for content related to "machine learning" by identifying vectors that closely match this concept. Similar vectors represent semantically related content.
Example: In a text classification task, word embeddings are used to represent text data. For instance, "cat" and "dog" are represented as vectors, and their semantic similarity can be measured using cosine similarity.
?? Vector Databases: The Core of Efficient Search
Vector databases are essential components of LLM-based search systems. Let's explore the key features and functionalities of vector databases:
- Pinecone: A fully managed vector database, Pinecone, offers powerful capabilities for approximate and exhaustive search. Here's what it brings to the table:
- Near Instance Refresh: Pinecone ensures that vectors and indexes are frequently updated, ensuring that you always have access to fresh data.
- Metadata Filtering: Pinecone supports various filtering criteria, such as dates, category, type of vectors, and topics. For example, you can filter your search results to specific departments or categories.
- Query, Context, and Document Embeddings: Pinecone supports different types of embeddings, including query embeddings, context embeddings, and document embeddings.
Let's consider a practical scenario where you want to search a large document, perhaps a 50-page report. Instead of sending the entire document to the LLM, you can split it into chunks, each containing 2 pages. These chunks are converted into vectors and scored individually. Then, the average scores across these chunks are used to score the entire document. This approach ensures that your score is still close to the actual document's quality.
?? Prompt Engineering Theory: Strategies for Effective Interaction
LLMs have evolved with various prompting techniques, each catering to specific needs and use cases. Here are some prominent strategies:
- Zero Shot: In this strategy, the model relies solely on its existing knowledge without being trained on any specific examples. While this method lacks fine-tuning and may have lower accuracy, it's valuable when examples are scarce, offering a more generalized approach.
- Few Shot: The Few Shot technique provides a few instructions or examples to guide the model's responses. It's particularly useful when you have limited data and need to fine-tune existing models for specific tasks.
- Chain of Thought (COT): Inspired by Google's Chain of Thought, this strategy improves the reasoning ability of LLMs by breaking down problems into smaller, more manageable steps. It assists models in reasoning and achieving greater accuracy in their responses. This technique can make the model more efficient and compact.
- ReAct (Reason-Acting): ReAct combines the reasoning capabilities of LLMs with actionable steps. It involves reasoning, taking actions, observing results, and conducting iterative conversations based on each search's findings. It's an approach that helps in developing the LangChain framework, enabling more interactive and efficient interactions with LLMs.
?? Prompt Engineering: Tips for Success
Successful interaction with LLMs requires careful prompt engineering. Here are some tips to enhance the effectiveness of your prompts:
- Provide Context: Context is crucial for LLMs to understand and respond accurately. Clearly convey the context of your query or task.
- Clear, Non-ambiguous Task Description: Ensure your instructions are concise, clear, and unambiguous. Clearly state what you expect from the model and the goals of the task.
- Iterations: Continuously improve your prompts through iterations. Fine-tune them to achieve better results over time.
?? LangChain: Powering LLM-Based Applications
LangChain is a framework that empowers LLMs to build a wide range of applications. It offers a comprehensive set of tools, libraries, and abstractions to create complex chains of actions. Here are some key components in LangChain:
- PromptTemplate: This takes text as input for prompts and allows you to pass parameters and variables to the template. For instance, you can use it to define how the input and output of a prompt should look.
- Chat Models/ChatOpenAI: This provides LLMs and wrappers for interacting with LLMs. You can specify parameters like temperature to control the model's creativity and the model's name.
- LLMChain: LLMChain combines various tasks of actions to create a chain. These chains can be run with specific input information.
- Agents: The Agents uses LLMs to determine which actions to take. It can make external calls, interact with databases, and perform various subtasks. The AgentType function defines how the Agent operates, and verbosity can be adjusted to monitor the Agent's reasoning.
- Output_Parsers: These help format the data output of the model. You can create schema to define fields based on the model's output.
Example: In financial, an output parser can convert complex financial data into concise, easy-to-understand reports for clients.
- Document Loader: This deals with data in various document formats, making it accessible for processing and interaction.
- Text Splitters: Text Splitters come into play when handling large documents or long texts. They help split content into manageable chunks that can be sent to LLMs, making them easier to process and manage. This approach also helps with token limitations and can be particularly useful when working with very large documents.
Example: In legal, text splitters divide complex legal documents into sections for more focused analysis.
- Memory: Memory is a vital component in LangChains, helping LLMs remember the context and history of past conversations. It plays a crucial role in co-reference resolution, allowing LLMs to maintain context throughout conversations. Different types of memory are available in LangChains to cater to various use cases.
Example: In a virtual assistant chatbot, memory stores previous conversations, allowing the Model to refer back to previous interactions and provide context-aware responses.
- Token Limitation Handling Strategies: Managing token limitations is a critical consideration when working with LLMs. Various strategies are available, including stuffing, map reduce, and refine. These strategies help optimize token usage and ensure efficient interactions with LLMs.
?? Ensemble Approaches: In the quest for more accurate results, an ensemble approach can be used, which involves applying multiple prompts and averaging the results from all prompts. This approach can enhance the robustness of the interactions with LLMs.
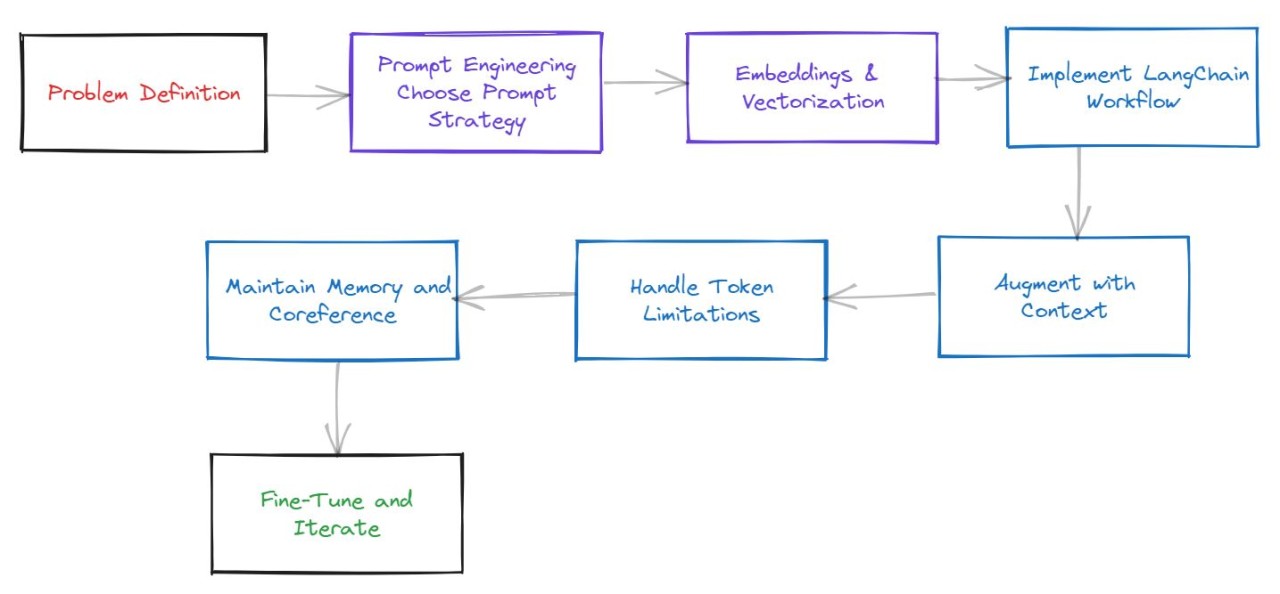
Stitching together: Using Prompt Engineering, Embeddings, and Vector Databases in LLM Solutions
To build LLM solutions that leverage Prompt Engineering, embeddings, and vector databases, follow these steps:
Michio Kaku recently characterized this as akin to "glorified tape recorders" rearranging existing internet content. AI is an expansive and ever-evolving field, often associated with the latest and most significant advancements in cutting-edge models. The so-called GenAI represents a purpose-built Large Language Model (LLM) designed for specific tasks. It's intriguing to observe how this field will progress with the rapid enhancements in scale and model size.
Contemplating whether LLMs can reach a point where they can excel in a SAT English exam, potentially achieving a perfect score.
The debate arises: In the future, will colleges find it necessary for their students to continue taking SAT English exams? Only time will provide the answer to that!
?? References for Further Exploration:
- [OpenAI Cookbook - Vector Databases](https://github.com/openai/openai-cookbook/tree/main/examples/vector_databases)
- [Pinecone: Approximate Search](https://youtu.be/HtI9easW