Boosting Database Efficiency: The Power of Partitioning and Sharding
Introduction
Partitioning and sharding are essential techniques for managing large databases. They address the need for improved performance, scalability, and availability by distributing data across multiple servers or splitting large tables into smaller, more manageable units.
Why Partitioning and Sharding?
1. Large Databases: Distributing extensive datasets across multiple servers enhances performance by allowing queries to target smaller datasets.
2. Large Tables: Techniques are needed to enhance query performance on large tables by scanning smaller segments.
3. Wide Tables: Some tables have numerous columns, and not all are accessed in every query. We need methods to optimize these queries.
4. Scalability and Availability: Enhancing the scalability, availability, and performance of the database is crucial.
Techniques for Improvement
To address these needs, options include:
Single server partitioning
Single server partitioning: in this technique the large tables is split into small ones on same server. And these can be done by split tables horizontally by split rows into multiple tables, each of them have small volume of data or split tables vertically by split tables with many columns into ones have small number of columns. And Some databases support this technique internally like postgreSQL.
Advantages
Disadvantages
Multiple Servers Partitioning
This technique distributes a large database across multiple servers, with each server holding a part of the database.
Advantages
领英推荐
Disadvantages
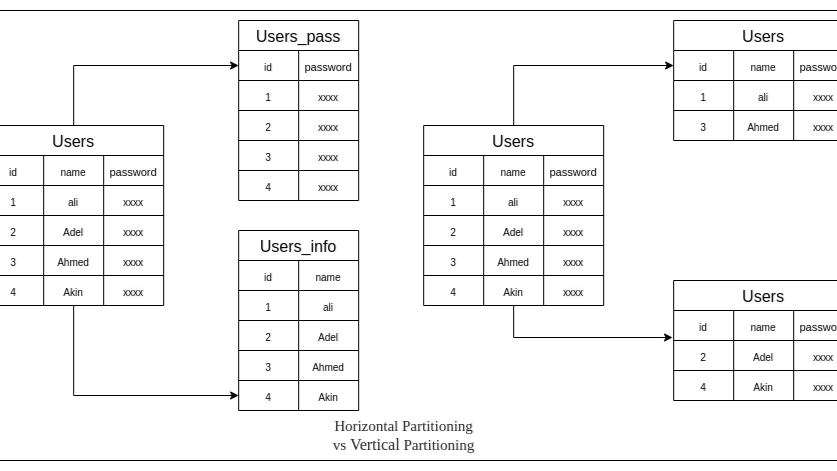
Horizontal Partitioning
Data is partitioned at the row level, with each group of rows referred to as a partition. This can occur on a single server or across multiple servers.
Types of horizontal partitioning?
Example?
In chat application with large number of messages, and most of users access most recent messages, so we can choose sent_at (date) column to be used in partitioning and choose one month as partitioning range. So according to sent_at, the message will be redirected to specific partition.
Example?
In an application like Uber with large number of users and drivers in many countries, the list partitioning can be used to make users are partitioned based on their countries.?
Vertical partitioning
Vertical partitioning: in this technique large tables with many columns are partitioned in small tables with partitioned columns according to the accessing queries and which columns will be accessed. This technique communally used in single server.
Sharding?
it is type of multiple servers partitioning technique, in which the data is partitioned horizontally and distributed across servers and each server have same database scheme. Some of database support sharding natively for example Mongodb.
Challenges in implementing sharding?
Conclusion
Partitioning and sharding enhance database performance, availability, and scalability. However, they also introduce additional complexity. It is essential to weigh the benefits against the complexities and explore other performance-enhancing techniques before implementation.