Automating Flight Data Processing with Apache Airflow, Docker, and Python
Here's another "Mad Scientist" Fidel V. latest project; on this project I’ll demonstrate how to automate the process of fetching, processing, and storing flight delay data using Apache Airflow, Docker, and Python. Through a series of steps, we’ll set up a Docker environment, define an Airflow DAG, write Python scripts to interact with the Airlabs flight data API, transform the data for readability, and store it in a PostgreSQL database.
From this framework, users can implement a robust data pipeline for handling flight tracking data efficiently, including visualizing flight delays and patterns.
Let's Build Shall We:
Building and deploying a comprehensive flight tracking application involves multiple steps such as data retrieval, processing, analysis, storage, visualization, and deployment. Below is an example demonstrating how to collect flight data on how often routes are delayed, using Python to extract data from the Airlabs flight data API, transform it, and load it into a PostgreSQL database. We'll also implement ETL using Docker, Python, Postgres, and Airflow for automation.
1. Collecting Flight Data
Python Script for Data Extraction:
import requests
import json
def fetch_flight_data(api_key):
url = "https://api.airlabs.co/v1/flights/delays"
headers = {"Authorization": f"Bearer {api_key}"}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.json()
else:
print("Failed to fetch flight data")
return None
api_key = "YOUR_API_KEY"
flight_data = fetch_flight_data(api_key)
if flight_data:
# Process flight data
# Example: Extract delay statistics for routes
delayed_routes = flight_data['delayed_routes']
for route in delayed_routes:
print(f"Route: {route['route']}, Delayed: {route['delay_percentage']}%")
Dockerfile for Containerization:
FROM python:3.9
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .
CMD ["python", "flight_data_extractor.py"]
2. Implementing ETL with Airflow and Postgres
Docker Compose File (docker-compose.yml):
version: '3'
services:
postgres:
image: postgres
environment:
POSTGRES_DB: flight_data
POSTGRES_USER: postgres
POSTGRES_PASSWORD: password
ports:
- "5432:5432"
volumes:
- pg_data:/var/lib/postgresql/data
airflow:
image: apache/airflow
restart: always
depends_on:
- postgres
environment:
POSTGRES_DB: airflow
POSTGRES_USER: airflow
POSTGRES_PASSWORD: airflow
ports:
- "8080:8080"
volumes:
- ./dags:/opt/airflow/dags
- ./logs:/opt/airflow/logs
- ./plugins:/opt/airflow/plugins
- ./requirements.txt:/requirements.txt
- ./entrypoint.sh:/entrypoint.sh
command: webserver
volumes:
pg_data:
Airflow DAG Script (flight_data_etl.py):
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime
from flight_data_extractor import fetch_flight_data
import psycopg2
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2024, 4, 15),
'email_on_failure': False,
'email_on_retry': False,
'retries': 1
}
def extract_transform_load(**kwargs):
api_key = kwargs['api_key']
flight_data = fetch_flight_data(api_key)
if flight_data:
# Transform data and load into Postgres
conn = psycopg2.connect("dbname=flight_data user=postgres password=password host=postgres")
cur = conn.cursor()
# Example: Load data into Postgres
cur.execute("INSERT INTO flight_delays (route, delay_percentage) VALUES (%s, %s)", (flight_data['route'], flight_data['delay_percentage']))
conn.commit()
conn.close()
with DAG('flight_data_etl', default_args=default_args, schedule_interval='@daily') as dag:
etl_task = PythonOperator(
task_id='extract_transform_load',
python_callable=extract_transform_load,
op_kwargs={'api_key': 'YOUR_API_KEY'}
)
etl_task
3. End-to-End Security Implementation
For end-to-end security, ensure that:
4. Deployment with Docker
To deploy the application within containers, use Docker Compose with the provided docker-compose.yml file.
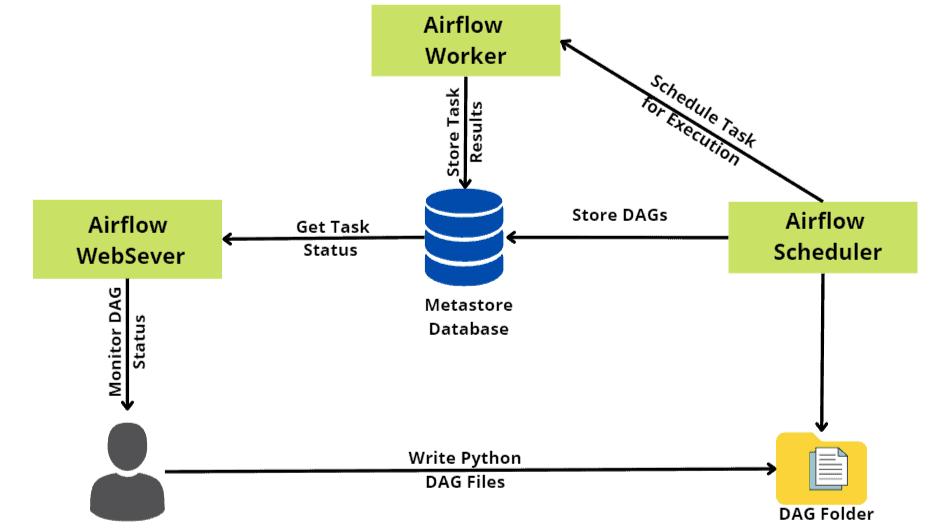
5. Automating with Airflow
Airflow is used to automate the ETL process. The DAG script (flight_data_etl.py) defines the workflow, scheduling it to run daily.
6. Transforming Data
Transformations can be done in the ETL process. For example, converting IATA airport codes to a readable format can be achieved within the extract_transform_load function.
This example demonstrates a basic setup for building and deploying a flight tracking application. Adjustments may be necessary based on specific requirements and additional features desired.
Let't me dig in with more details on End-to-End Security Implementation involves securing every aspect of the application, from data transmission to storage and access control. Below is my comprehensive example demonstrating various security measures:
1. Secure Data Transmission:
Implement HTTPS:
Ensure all communication between clients and the server is encrypted using HTTPS. This can be achieved by configuring the web server (e.g., Nginx or Apache) with an SSL certificate.
2. Secure Data Storage:
Encrypt Sensitive Data:
Use encryption algorithms to encrypt sensitive data before storing it in the database. This ensures that even if the database is compromised, the data remains unreadable without the decryption key.
Database Security:
3. Authentication and Authorization:
User Authentication:
Require users to authenticate before accessing the application. Implement secure authentication mechanisms such as OAuth, JWT, or multi-factor authentication.
Role-Based Access Control (RBAC):
Enforce RBAC to control access to different parts of the application based on user roles and permissions. Ensure that users only have access to the data and functionality necessary for their roles.
4. Secure API Access:
API Key Management:
Manage API keys securely. Avoid hardcoding keys in the application code or configuration files. Store keys securely in environment variables or a secure storage service.
API Rate Limiting:
Implement rate limiting to prevent abuse and protect the API from denial-of-service attacks.
5. Regular Security Audits:
Vulnerability Scanning:
Regularly scan the application and infrastructure for vulnerabilities using security scanning tools. Address any identified vulnerabilities promptly.
Penetration Testing:
Conduct periodic penetration testing to identify and address potential security weaknesses in the application.
Example Code Snippets:
Flask App Configuration for HTTPS:
from flask import Flask
from flask_sslify import SSLify
app = Flask(__name__)
sslify = SSLify(app)
Database Encryption:
from cryptography.fernet import Fernet
# Generate encryption key
key = Fernet.generate_key()
# Encrypt data before storing in the database
cipher_suite = Fernet(key)
cipher_text = cipher_suite.encrypt(b"Sensitive data")
# Decrypt data when retrieving from the database
plain_text = cipher_suite.decrypt(cipher_text)
User Authentication with Flask:
from flask_login import LoginManager, UserMixin, login_user, logout_user, login_required
app = Flask(__name__)
login_manager = LoginManager(app)
class User(UserMixin):
pass
@login_manager.user_loader
def load_user(user_id):
return User.get(user_id)
@app.route('/login', methods=['POST'])
def login():
# Validate credentials
user = User.query.filter_by(username=request.form['username']).first()
if user and check_password_hash(user.password, request.form['password']):
login_user(user)
return redirect(url_for('dashboard'))
else:
return 'Invalid username or password'
API Key Management:
import os
API_KEY = os.getenv('API_KEY')
Security Headers in Flask:
from flask import Flask
from flask_talisman import Talisman
app = Flask(__name__)
csp = {
'default-src': '\'self\'',
'script-src': ['\'self\'', 'https://cdn.example.com'],
# Add more directives as needed
}
talisman = Talisman(app, content_security_policy=csp)
These examples provide a starting point for implementing end-to-end security in your application. Remember to customize and expand upon them based on your specific security requirements and best practices.
I would like to dig in more on deploying an application with Docker involves creating Docker images for each component of the application and then running those images as containers. Below is a comprehensive example demonstrating how to deploy a Flask web application with PostgreSQL database using Docker.
领英推荐
1. Dockerfile for Flask Application:
# Use the official Python image as a base
FROM python:3.9-slim
# Set environment variables
ENV PYTHONDONTWRITEBYTECODE 1
ENV PYTHONUNBUFFERED 1
# Set the working directory in the container
WORKDIR /app
# Install dependencies
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copy the Flask application code into the container
COPY . .
# Expose the port on which the Flask app will run
EXPOSE 5000
# Command to run the Flask application
CMD ["python", "app.py"]
2. Dockerfile for PostgreSQL Database:
# Use the official PostgreSQL image as a base
FROM postgres:latest
# Set environment variables
ENV POSTGRES_DB flight_data
ENV POSTGRES_USER postgres
ENV POSTGRES_PASSWORD password
3. Docker Compose File (docker-compose.yml):
version: '3'
services:
web:
build:
context: .
dockerfile: Dockerfile
ports:
- "5000:5000"
depends_on:
- db
db:
build:
context: .
dockerfile: Dockerfile.postgres
ports:
- "5432:5432"
volumes:
- pg_data:/var/lib/postgresql/data
volumes:
pg_data:
4. Flask Application Code (app.py):
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello():
return 'Hello, Docker!'
if __name__ == '__main__':
app.run(host='0.0.0.0')
5. PostgreSQL Initialization Script (init.sql):
CREATE TABLE flight_delays (
id SERIAL PRIMARY KEY,
route VARCHAR(100),
delay_percentage FLOAT
);
Deployment Steps:
This example demonstrates how to deploy a Flask web application with a PostgreSQL database using Docker. Adjustments may be necessary based on specific requirements and additional components of your application.
Automate tasks such as data extraction, transformation, and loading (ETL) using Airflow, you'll define Directed Acyclic Graphs (DAGs) that represent your workflow. Each DAG consists of tasks that are executed in a specific order according to dependencies and schedules. Below is a comprehensive example demonstrating how to automate ETL tasks using Airflow.
1. Install Apache Airflow:
Ensure you have Apache Airflow installed. You can install it using pip:
pip install apache-airflow
2. Initialize Airflow Database:
Initialize the Airflow metadata database:
airflow db init
3. Define Airflow DAG:
Create a Python script to define your Airflow DAG. For this example, let's create a file named flight_data_etl.py:
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime
from flight_data_extractor import fetch_flight_data
import psycopg2
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2024, 4, 15),
'email_on_failure': False,
'email_on_retry': False,
'retries': 1
}
def extract_transform_load(**kwargs):
api_key = kwargs['api_key']
flight_data = fetch_flight_data(api_key)
if flight_data:
# Transform data and load into Postgres
conn = psycopg2.connect("dbname=flight_data user=postgres password=password host=postgres")
cur = conn.cursor()
# Example: Load data into Postgres
cur.execute("INSERT INTO flight_delays (route, delay_percentage) VALUES (%s, %s)", (flight_data['route'], flight_data['delay_percentage']))
conn.commit()
conn.close()
with DAG('flight_data_etl', default_args=default_args, schedule_interval='@daily') as dag:
etl_task = PythonOperator(
task_id='extract_transform_load',
python_callable=extract_transform_load,
op_kwargs={'api_key': 'YOUR_API_KEY'}
)
etl_task
4. Define Data Extraction Script:
Create a Python script to extract flight data. Let's call it flight_data_extractor.py. This script should contain the fetch_flight_data function.
5. Start Airflow Scheduler:
Start the Airflow scheduler:
airflow scheduler
6. Trigger DAG Execution:
Access the Airflow UI (typically at localhost:8080), and trigger the flight_data_etl DAG. Airflow will execute the defined tasks according to the schedule specified in the DAG definition.
Note:
This example demonstrates how I automate ETL tasks using Apache Airflow. Adjustments may be necessary based on your specific use case and requirements.
To transform data during the ETL process, you can create Python scripts within your Airflow DAG to perform necessary transformations before loading the data into the destination database. Below is an example demonstrating how to transform data using Python scripts within an Airflow DAG:
1. Define Transform Script:
Create a Python script to perform the data transformation. Let's call it transform_data.py:
import csv
def transform_airport_codes(input_file, output_file):
with open(input_file, 'r') as csv_file:
reader = csv.DictReader(csv_file)
airport_codes = {}
for row in reader:
airport_codes[row['IATA']] = row['AirportName'] # Assuming IATA code is the key and AirportName is the value
with open(output_file, 'w') as transformed_file:
writer = csv.writer(transformed_file)
writer.writerow(['IATA', 'AirportName']) # Header
for code, name in airport_codes.items():
writer.writerow([code, name])
2. Integrate Transformation in Airflow DAG:
Modify your Airflow DAG script (flight_data_etl.py) to include a task that executes the transformation script. Add the following task definition to your DAG:
from airflow.operators.python_operator import PythonOperator
def transform_data(**kwargs):
input_file = kwargs['input_file']
output_file = kwargs['output_file']
transform_airport_codes(input_file, output_file)
with DAG('flight_data_etl', default_args=default_args, schedule_interval='@daily') as dag:
# Other tasks...
transform_task = PythonOperator(
task_id='transform_data',
python_callable=transform_data,
op_kwargs={'input_file': '/path/to/input.csv', 'output_file': '/path/to/output.csv'}
)
# Define dependencies
etl_task >> transform_task
3. Trigger Transformation Task:
Trigger the transform_data task within your Airflow DAG. This task will execute the transformation script (transform_data.py) and produce the transformed output file.
Note:
This example demonstrates how to incorporate data transformation into an Airflow DAG using Python scripts. Adjustments may be necessary based on your specific use case and data transformation requirements.
Fidel V (Mad Scientist)
Chief Innovation Architect || Product Developer
Security * AI * Systems?*?Cloud?*?Software
Space. Technology. Energy. Manufacturing. BioTech
?? The #Mad_Scientist "Fidel V. || Technology Innovator & Visionary ??
Disclaimer: The views and opinions expressed in this my article are those of the Mad Scientist and do not necessarily reflect the official policy or position of any agency or organization.
#AI / #AI_mindmap / #AI_ecosystem / #ai_model / #Space / #Technology / #Energy / #Manufacturing / #stem / #Docker / #Kubernetes / #Llama3 / #integration / #cloud / #Systems / #blockchain / #Automation / #LinkedIn / #genai / #gen_ai / #LLM / #ML / #analytics / #automotive / #aviation / #SecuringAI / #python / #machine_learning / #machinelearning / #deeplearning / #artificialintelligence / #businessintelligence / #cloud / #Mobileapplications / #SEO / #Website / #Education / #engineering / #management / #security / #android / #marketingdigital / #entrepreneur / #linkedin / #lockdown / #energy / #startup / #retail / #fintech / #tecnologia / #programing / #future / #creativity / #innovation / #data / #bigdata / #datamining / #strategies / #DataModel / #cybersecurity / #itsecurity / #facebook / #accenture / #twitter / #ibm / #dell / #intel / #emc2 / #spark / #salesforce / #Databrick / #snowflake / #SAP / #linux / #memory / #ubuntu / #apps / #software / #io / #pipeline / #florida / #tampatech / #Georgia / #atlanta / #north_carolina / #south_carolina / #personalbranding / #Jobposting / #HR / #Recruitment / #Recruiting / #Hiring / #Entrepreneurship / #moon2mars / #nasa / #Aerospace / #spacex / #mars / #orbit / #AWS / #oracle / #microsoft / #GCP / #Azure / #ERP / #spark / #walmart / #smallbusiness