Apache Spark 101: DataFrame Write API Operation
Shanoj Kumar V
VP - Technology Architect & Data Engineering | AWS | AI & ML | Big Data & Analytics | Digital Transformation Leader | Author
Apache Spark is an open-source distributed computing system that provides a robust platform for processing large-scale data. The Write API is a fundamental component of Spark's data processing capabilities, which allows users to write or output data from their Spark applications to different data sources.
Understanding the Spark Write API
Data Sources: Spark supports writing data to a variety of sources, including but not limited to:
DataFrameWriter: The core class for the Write API is DataFrameWriter. It provides functionality to configure and execute write operations. You obtain a DataFrameWriter by calling the .write method on a DataFrame or Dataset.
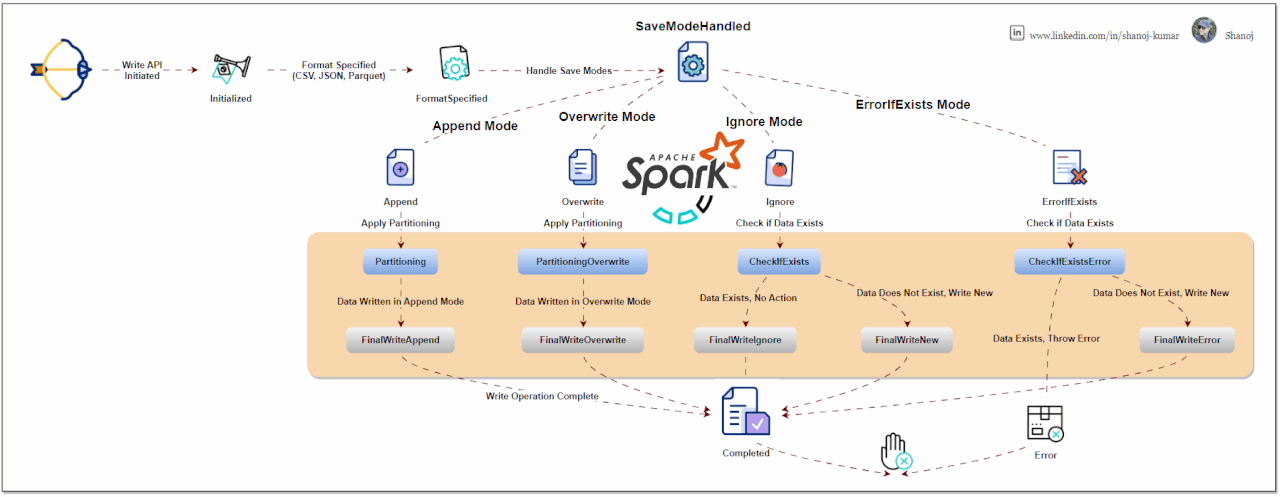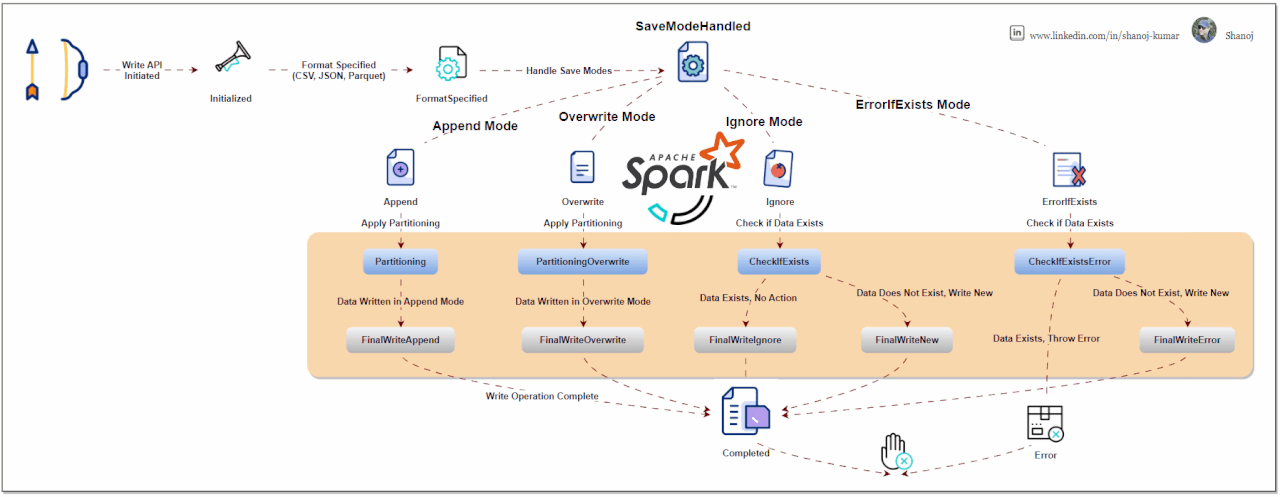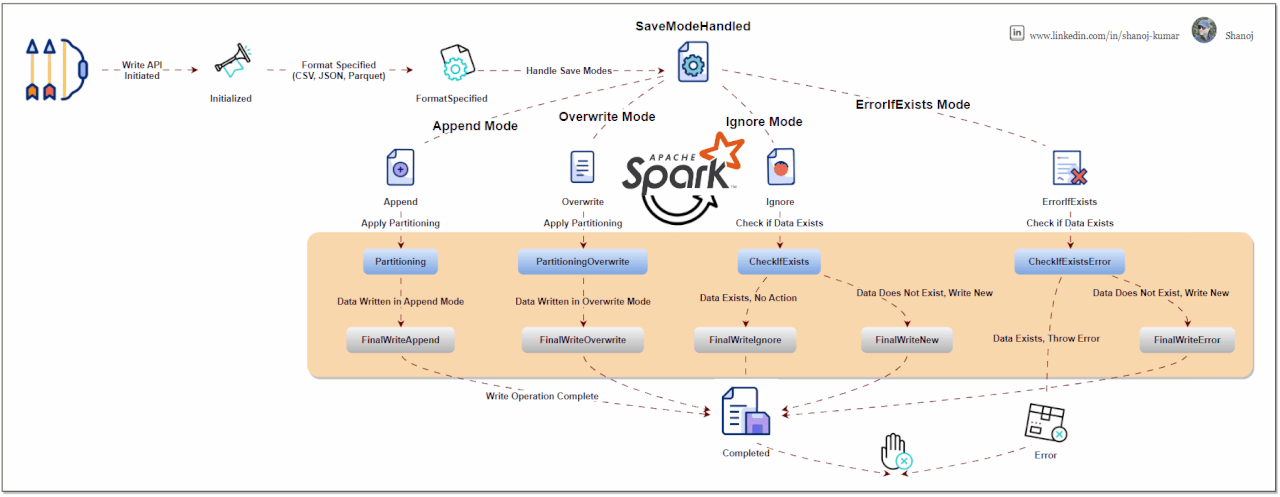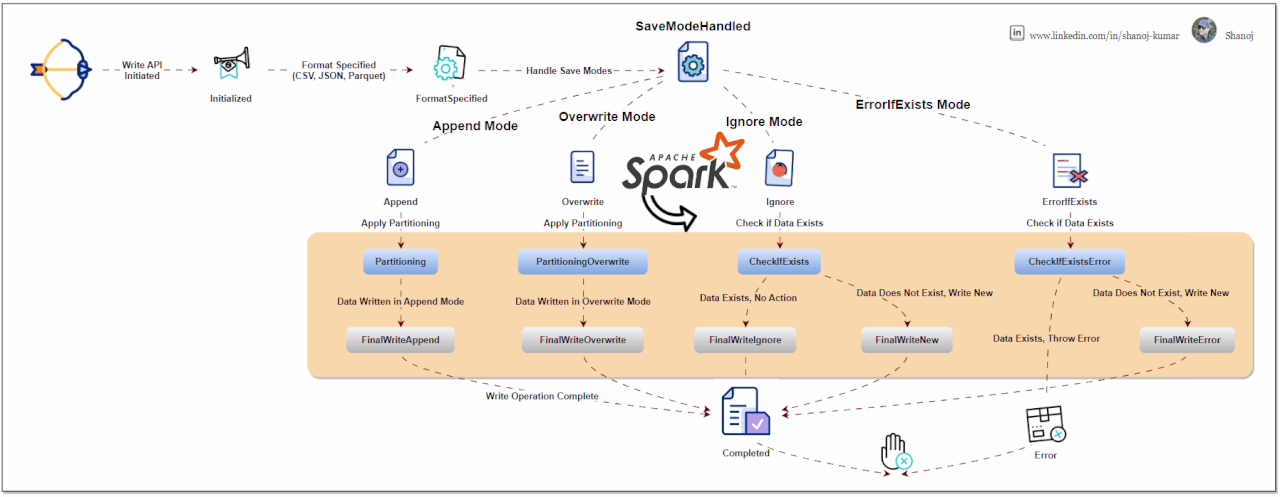
Write Modes: Specify how Spark should handle existing data when writing data. Common modes are:
Format Specification: You can specify the format of the output data, like JSON, CSV, Parquet, etc. This is done using the .format("formatType") method.
Partitioning: For efficient data storage, you can partition the output data based on one or more columns using .partitionBy("column").
Configuration Options: You can set various options specific to the data source, like compression, custom delimiters for CSV files, etc., using .option("key", "value").
Saving the Data: Finally, you use .save("path") to write the DataFrame to the specified path. Other methods .saveAsTable("tableName") are also available for different writing scenarios.
from pyspark.sql import SparkSession
from pyspark.sql import Row
import os
# Initialize a SparkSession
spark = SparkSession.builder \
.appName("DataFrameWriterSaveModesExample") \
.getOrCreate()
# Sample data
data = [
Row(name="Alice", age=25, country="USA"),
Row(name="Bob", age=30, country="UK")
]
# Additional data for append mode
additional_data = [
Row(name="Carlos", age=35, country="Spain"),
Row(name="Daisy", age=40, country="Australia")
]
# Create DataFrames
df = spark.createDataFrame(data)
additional_df = spark.createDataFrame(additional_data)
# Define output path
output_path = "output/csv_save_modes"
# Function to list files in a directory
def list_files_in_directory(path):
files = os.listdir(path)
return files
# Show initial DataFrame
print("Initial DataFrame:")
df.show()
# Write to CSV format using overwrite mode
df.write.csv(output_path, mode="overwrite", header=True)
print("Files after overwrite mode:", list_files_in_directory(output_path))
# Show additional DataFrame
print("Additional DataFrame:")
additional_df.show()
# Write to CSV format using append mode
additional_df.write.csv(output_path, mode="append", header=True)
print("Files after append mode:", list_files_in_directory(output_path))
# Write to CSV format using ignore mode
additional_df.write.csv(output_path, mode="ignore", header=True)
print("Files after ignore mode:", list_files_in_directory(output_path))
# Write to CSV format using errorIfExists mode
try:
additional_df.write.csv(output_path, mode="errorIfExists", header=True)
except Exception as e:
print("An error occurred in errorIfExists mode:", e)
# Stop the SparkSession
spark.stop()
Spark’s Architecture Overview
The Apache Spark Write API, from the perspective of Spark’s internal architecture, involves understanding how Spark manages data processing, distribution, and writing operations under the hood. Let’s break it down:
领英推荐
Spark’s Architecture Overview
Writing Data Internally in Spark
Data Distribution: Data in Spark is distributed across partitions. Spark first determines the data layout across these partitions when a write operation is initiated.
Task Execution for Write: Each partition’s data is handled by a task. These tasks are executed in parallel across different executors.
Write Modes and Consistency:
Format Handling and Serialization: Depending on the specified format (e.g., Parquet, CSV), Spark uses the respective serializer to convert the data into the required format. Executors handle this process.
Partitioning and File Management:
Error Handling and Fault Tolerance: In case of a task failure during a write operation, Spark can retry the task, ensuring fault tolerance. However, not all write operations are fully atomic, and specific scenarios might require manual intervention to ensure data integrity.
Optimization Techniques:
Write Commit Protocol: Spark uses a write commit protocol for specific data sources to coordinate the process of task commits and aborts, ensuring a consistent view of the written data.
Efficient and reliable data writing is the ultimate goal of Spark's Write API, which orchestrates task distribution, data serialization, and file management in a complex manner. It utilizes Spark's core components, such as the DAG scheduler, task scheduler, and Catalyst optimizer, to perform write operations effectively.