Apache Kafka: An Introduction to Core Concepts and Terminology
Ritvik Raj
Writes to 9k+ | Lead Data Engineer | IIT Roorkee | Big Data | GenAI | Cloud Architectures | Spark | Databricks | Hadoop | AWS | Azure | Kafka | Scala | Airflow | Mentor | 300+ Resume Reviewed
Apache Kafka is a powerhouse for data streaming, handling large volumes of real-time data with impressive reliability. It enables seamless data integration across systems and has become a staple in data engineering, distributed systems, and big data solutions. But what makes Kafka so effective? Let's dive into its core terms and understand its foundational elements. ??
1?? Topics
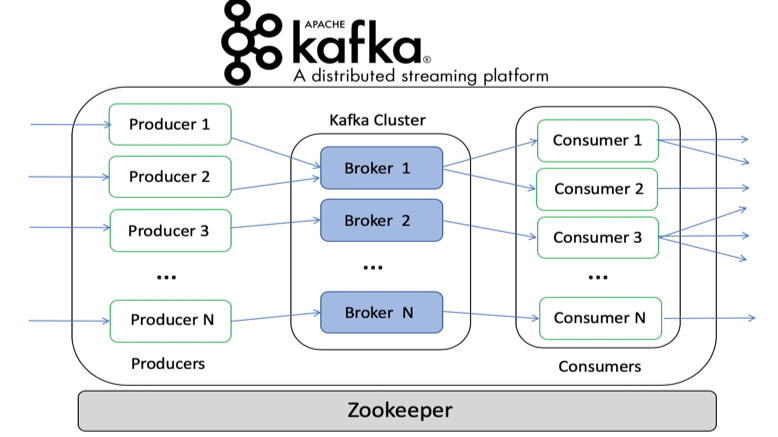
At the heart of Kafka are Topics, which act as channels for data flow. Each topic is an ordered stream of events or records (messages). Topics can be categorised based on use cases (e.g., “user_logins” or “order_events”) and help segregate data streams logically.
2?? Producers
Producers are applications or services that send data to Kafka topics. They push data records into specific topics and can control the exact partition where the record is sent, often by using a key. Producers also play a role in ensuring data reliability by setting the acks parameter, determining the acknowledgment required for data delivery success.
3?? Consumers
Consumers are applications or services that read data from Kafka topics. A consumer pulls records in sequential order and processes them. In distributed systems, consumers often belong to a Consumer Group, enabling load balancing by allowing different instances of a consumer to read from multiple partitions in parallel.
4?? Consumer Groups
A Consumer Group consists of one or more consumers collaborating to consume data from a topic. Kafka divides the topic's partitions among the group’s consumers, ensuring each partition is consumed by only one consumer in a group. This partitioned consumption model enables scalable data processing.
5?? Partitions
Each Kafka topic is divided into multiple Partitions to enable parallelism and data redundancy. Partitions allow Kafka to scale horizontally by distributing data across multiple brokers. Each partition has an immutable sequence of records, where each record is identified by an offset, marking its position within the partition.
6?? Offsets
An Offset is the unique identifier for a record within a partition. Kafka stores offsets as markers, so consumers know where they last left off, enabling seamless continuation even in cases of failure. Managing offsets effectively is crucial for ensuring data consistency and avoiding duplicate processing.
领英推荐
7?? Brokers
Kafka servers, known as Brokers, are responsible for storing topic data and serving producers and consumers. Kafka clusters consist of multiple brokers working together to ensure high availability and fault tolerance. Brokers coordinate with each other and share the responsibility of storing and distributing data.
8?? Replication Factor
Kafka’s fault tolerance relies on Replication. Each topic’s partitions have a replication factor, determining how many copies of each partition are stored across different brokers. A higher replication factor enhances data reliability, ensuring data is preserved even if some brokers fail.
9?? ZooKeeper
Historically, Kafka has relied on ZooKeeper for cluster management, including leader election, configuration management, and detecting failures. With newer Kafka versions, Kafka Raft (KRaft) is gradually replacing ZooKeeper, streamlining Kafka’s internal management by consolidating responsibilities within Kafka itself.
?? Kafka Streams & Kafka Connect
Kafka is not just about messaging; it’s a full-fledged data platform:
Understanding these terms will strengthen your grasp of Kafka’s architecture and prepare you to leverage its capabilities effectively in data-driven applications. Whether you’re implementing a streaming data pipeline or powering real-time analytics, Kafka’s distributed model offers the flexibility and resilience required for modern data challenges.
Credits for the images used:
"Empower Your Career with Expert Insights: Discover Technical Interview Success Strategies on Algo2Ace!"
3 个月Scenario Based Interview Questions on Kafka: https://algo2ace.com/category/kafka-stream/
C11 Senior Software Engineer at CITI | Full Stack | Java 8 | Typescript | Microservices | Spring Framework | Springboot | Angular | REST APIs | SQL | JPA and Hibernate | Docker | AKS | Microsoft Azure Cloud | Open Shift
3 个月This post is very informative. Good for beginners to get an overview of Kafka and its components.
10k+| Member of Global Remote Team| Building Tech & Product Team| AWS Cloud (Certified Architect)| DevSecOps| Kubernetes (CKA)| Terraform ( Certified)| Jenkins| Python| GO| Linux| Cloud Security| Docker| Azure| Ansible
3 个月Very helpful Ritvik Raj ?? Let's connect ??!!!
Data Engineer | Expertise in Scalable Data Platforms, Real-Time Streaming & Cloud | Skilled in Airflow, Kafka, dbt | Driving Data Quality, Governance & Innovation | AWS GCP
3 个月Interesting to read this. If in a topic there are multiple partitions, the ordering is not garaunteed when consuming, any suggestions on how can we maintain orders while consuming.