Aggregation Methods in Apache Spark: Simplified Explanation with Examples
Manish Batra
Azure data engineer |Senior Big Data Engineer |Pyspark | Hive | Hadoop | Sqoop | SQL
Apache Spark uses two main methods for grouping and summarizing data: Hash-based aggregation and Sort-based aggregation. Each has its own strengths and best-use scenarios.
Hash-based Aggregation
How It Works:
1. Hash Table Creation: Spark creates a hash table where each unique group gets an entry.
2. Updating Aggregates: As Spark processes rows, it quickly finds the group in the hash table and updates the aggregate values (e.g., sum, count).
3. Memory Requirement: This method is fast because it doesn’t sort the data, but it needs enough memory to hold all the groups.
Example:
Imagine you have a dataset of sales data, and you want to sum the sales by product ID:
Key Points:
Sort-based Aggregation
How It Works:
1. Sorting: Spark first sorts the data by the group keys.
2. Processing Groups: After sorting, it processes the sorted data to compute aggregate values.
3. Handling Large Data: It’s slower due to the sorting step but can handle larger datasets as it processes data in chunks.
Example:
Using the same sales dataset, if it’s too large for hash-based aggregation:
Key Points:
领英推荐
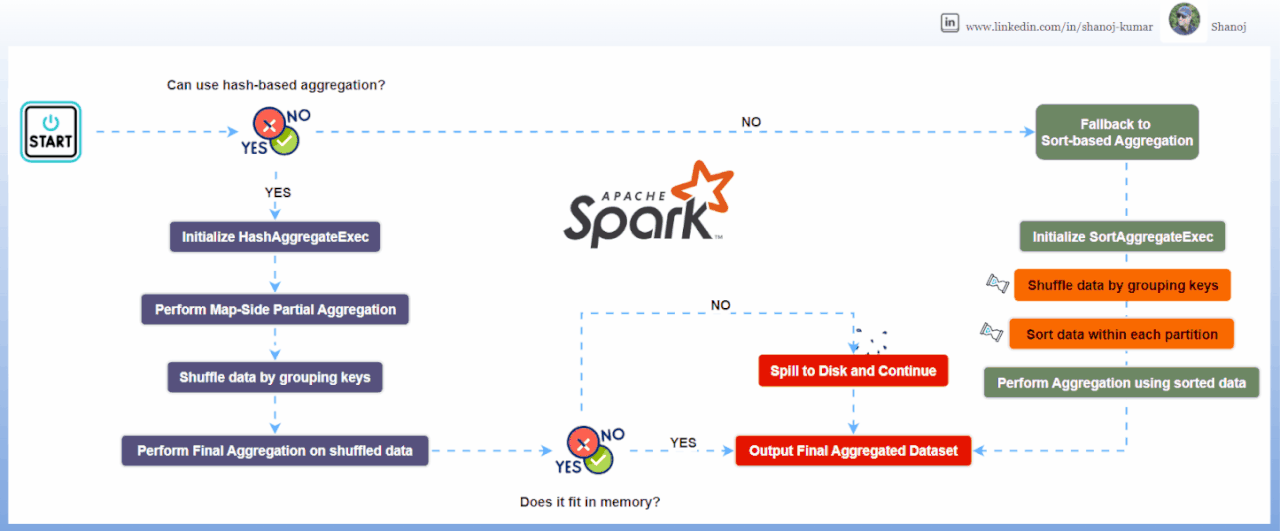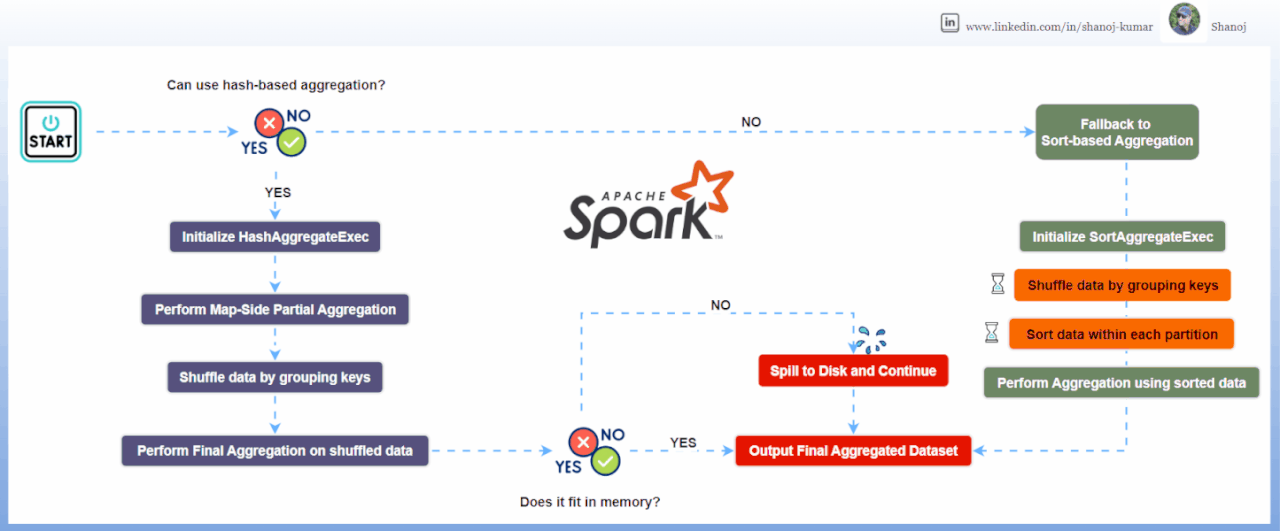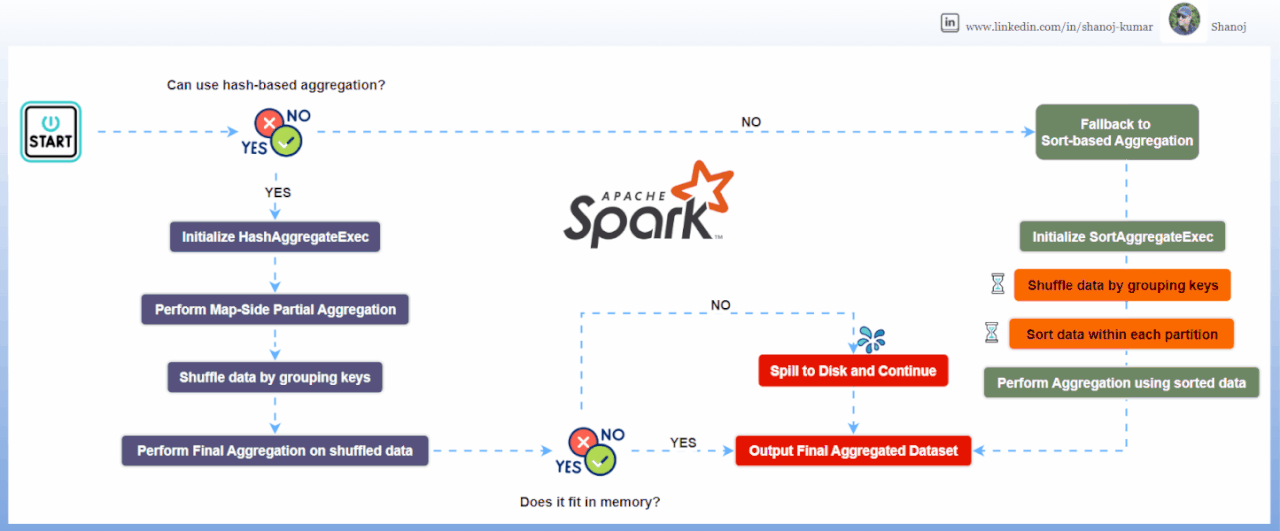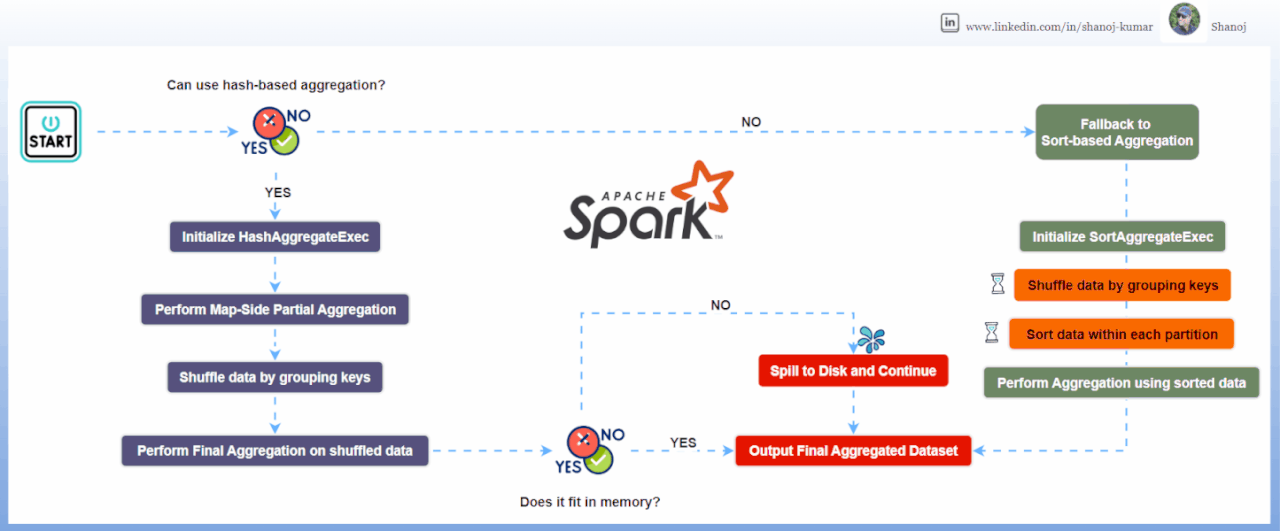
Detailed Explanation of Hash-based Aggregation
1. Initialization: Spark checks if it can use hash-based aggregation based on the data and functions involved.
2. Partial Aggregation (Map Side): Each data partition creates a hash map to store partial results.
3. Shuffling: Data is shuffled so that records with the same group key are in the same partition.
4. Final Aggregation (Reduce Side): Spark combines the partial results using another hash map.
5. Spill to Disk: If memory is insufficient, Spark can spill data to disk.
6. Fallback: If memory issues persist, Spark falls back to sort-based aggregation.
Example:
Detailed Explanation of Sort-based Aggregation
1. Shuffling: Data is partitioned by grouping keys.
2. Sorting: Each partition’s data is sorted by the group keys.
3. Aggregation: Spark processes the sorted data, aggregating values for each group.
4. Processing Rows: It updates a buffer with aggregated values, and outputs results when group keys change.
5. Memory Management: Only needs a buffer for the current group, allowing it to handle large datasets.
6. Fallback: Hash-based aggregation can fallback to sort-based if memory issues occur.
Example:
Summary
These methods ensure Spark can efficiently aggregate data under various conditions, balancing speed and scalability.
Data Engineer | Pyspark | Hadoop | Aws | Hive | Sqoop | SQL
7 个月Useful tips??