Aggregate and Window Functions in Pyspark
Nikhil G R
Senior Data Engineer (Apache Spark Developer) @ SAP Labs India, Ex TCS, 3x Microsoft Azure Cloud Certified, Python, Pyspark, Azure Databricks, SAP BDC, Datasphere, ADLs, Azure Data factory, MySQL, Delta Lake
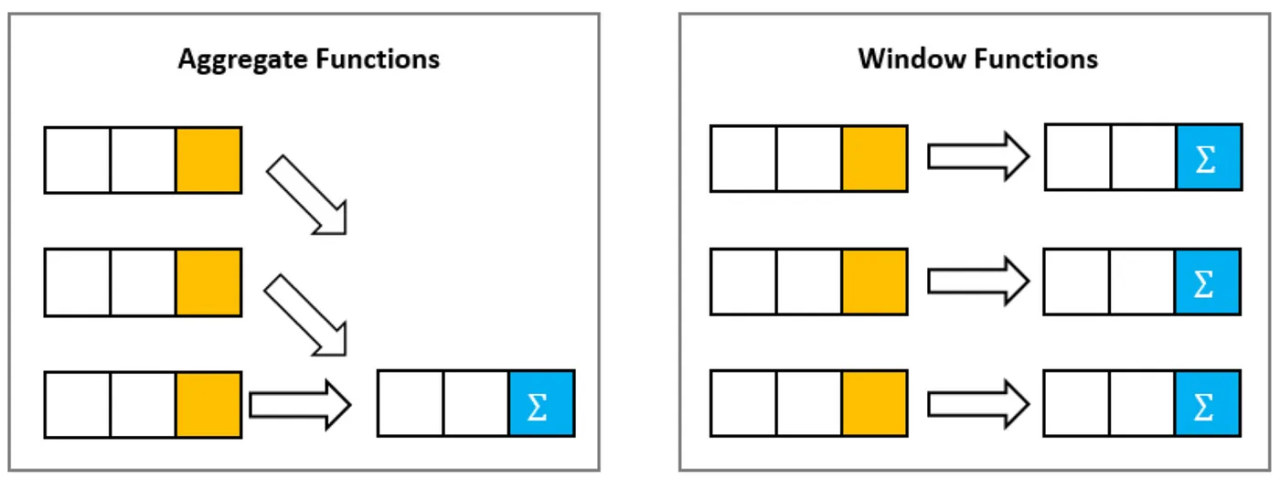
Aggregate Functions
These are the functions where the number of output rows will always be less than the number of input rows.
There are mainly two types of Aggregate Functions:
Simple Aggregate Function Example
Consider we have an orders.csv dataset and we are required to
Grouping Aggregate Function Example
Consider we have an orders.csv dataset and we are required to group based on invoice number and country. We also need to
Window Functions
Window Function Example
Consider we have window.csv. We need to define the following 3 parameters
Find the running total of invoice value
Understanding rank(), dense_rank(), row_number(), lead() and lag()
rank() - Returns the rank of rows within a window partition.
领英推荐
In rank(), some ranks can be skipped if there are clashes in the ranks.
dense_rank() - Returns the rank of rows within a window partition without any gaps.
In dense_rank(), the ranks are not skipped even if there are clashes in the ranks.
row_number() - Returns a sequential number starting at 1 within a window partition.
In row_number(), different row numbers are assigned even in case of a tie. It plays an important role in calculating the top-n results.
Realworld example of rank(), dense_rank() and row_number()
Consider an example scenario of how different ranks are assigned to the students based on the marks scored.
2 people got 100 points - 1st rank
1 person got 99 points - 2nd rank
1 person got 98 points - 3rd rank
Here, we need to use dense_rank()
When we need to compare two rows, lead() and lag() function should be used.
lead() - It is used when the current row needs to be compared with the next row.
lag() - It is used when the current row needs to be compared with the previous row.
For more information please check out:
Credits - Sumit Mittal sir