Activation Functions in Deep Learning & Neural Network
Md Nazrul Islam
Power BI & Tableau Specialist | Transforming Data into Actionable Insights | Python & ML Expertise
Introduction of Activation function:
First proposed in 1944 by Warren McCullough and Walter Pitts, Neural Networks are the techniques powering the best speech recognizers and translators on our smartphones, through something called “deep learning” which employs several layers of neural nets.
Neural Nets are modeled loosely based on the human brain, where there are thousands or even millions of nodes that are densely connected with each other. Just like how the brain “fires” up neurons, in Artificial Neural Networks (ANN) an Artificial Neuron is fired up by sending a signal from the incoming node multiplies by some weight, this node can be visualized as something that is holding a number which comes from the ending branches (Synapses) supplied at that Neuron, what happens is for a Layer of Neural Network (NN) we multiply the input to the Neuron with the weight held by that synapse and sum all of those up to get our output.
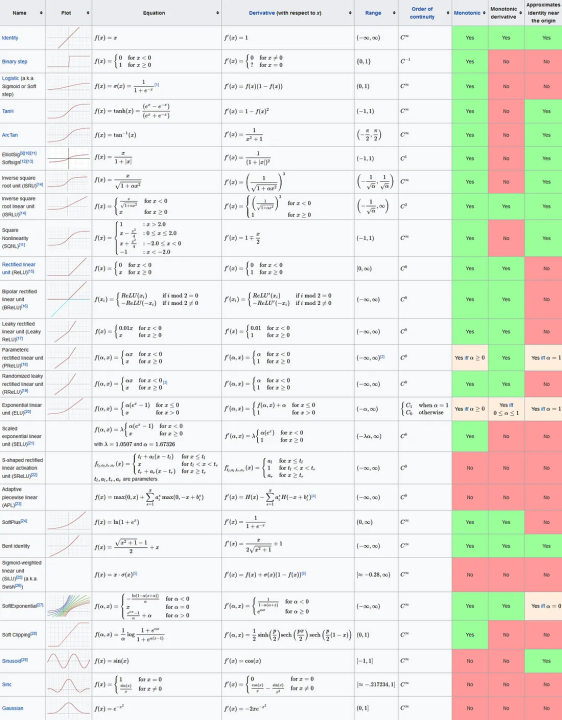
Commonly used activation functions in neural networks satisfy various desirable properties:
One of the most popular activation functions, the Rectified Linear Unit (ReLU), is nonlinear, continuously differentiable (except at 0 where it's subdifferentiable), and computationally efficient. However, ReLU lacks monotonicity.
To address this, Leaky ReLU and Parametric ReLU (PReLU) introduce a small slope for negative inputs, maintaining nonlinearity while being monotonic. These functions are also continuously differentiable.
Another commonly used activation function, the Sigmoid function, is nonlinear, continuously differentiable, and has a finite range, making it stable for gradient-based optimization. However, it suffers from the vanishing gradient problem.
The Hyperbolic Tangent (Tanh) function shares similar properties with the Sigmoid function but has a range between -1 and 1, making it symmetric around the origin and potentially mitigating the vanishing gradient problem.
The Swish activation function, proposed by Google researchers, is nonlinear, smooth, and approximately identity near zero, enhancing gradient flow during training. It also tends to generalize well.
Additionally, the Softplus function is a smooth approximation of the ReLU function and is continuously differentiable everywhere, making it suitable for gradient-based optimization.
While these activation functions offer different trade-offs in terms of properties like monotonicity, smoothness, and range, the choice often depends on the specific requirements of the neural network architecture and the problem domain.
Most used Activation Function in Deep Learning and Neural Network
Sigmoid functions are used in machine learning for logistic regression and basic neural network implementations and they are the introductory activation units. But for advanced Neural Network Sigmoid functions are not preferred due to various drawbacks (vanishing gradient problem). It is one of the most used activation function for beginners in Machine Learning and Data Science when starting out.
While the sigmoid function simplifies model creation and expedites training, it suffers from a significant drawback: information loss due to its limited derivative range. As the neural network deepens, this loss compounds at each layer, exacerbating the vanishing and exploding gradient problem. Moreover, since the sigmoid function's outputs are positive, it skews the output neurons toward positivity, which is suboptimal. Additionally, its lack of centrality at 0 renders it unsuitable for early layer activation. However, it can still find utility in the final layer of the network.
2. TanH Function:
In tanh function the drawback we saw in sigmoid function is addressed (not entirely), here the only difference with sigmoid function is the curve is symmetric across the origin with values ranging from -1 to 1
This does not however mean that tanh is devoid of the vanishing or exploding gradient problem, it persists even in the case of tanh but unlike Sigmoid as it is centered at Zero, it is more optimal than Sigmoid Function. Therefore other functions are employed more often which we will see below for machine learning.
3. ReLU (Rectified Linear Units) and Leaky ReLU:
Most Deep Learning applications right now make use of ReLU instead of Logistic Activation functions for Computer Vision, Speech Recognition, Natural Language Processing and Deep Neural Networks etc. ReLU also has a manifold convergence rate on application when compared to tanh or sigmoid functions.
Some of the ReLU variants include : Softplus (SmoothReLU), Noisy ReLU, Leaky ReLU, Parametric ReLU and ExponentialReLU (ELU). Some of which we will discuss below.
ReLU : A Rectified Linear Unit (A unit employing the rectifier is also called a rectified linear unit ReLU) has output 0 if the input is less than 0, and raw output otherwise. That is, if the input is greater than 0, the output is equal to the input. The operation of ReLU is closer to the way our biological neurons work.
领英推荐
ReLU f(x)
ReLU is non-linear and has the advantage of not having any backpropagation errors unlike the sigmoid function, also for larger Neural Networks, the speed of building models based off on ReLU is very fast opposed to using Sigmoids :
ReLUs aren’t without any drawbacks; some of them are that ReLU is Non Zero centered and is non-differentiable at Zero, but differentiable anywhere else.
One of the conditions on ReLU is the usage, it can only be used in hidden layers and not elsewhere. This is due to the limitation mentioned below
Another problem we see in ReLU is the Dying ReLU problem where some ReLU Neurons essentially die for all inputs and remain inactive no matter what input is supplied, here no gradient flows and if large number of dead neurons are there in a Neural Network it’s performance is affected, this can be corrected by making use of what is called Leaky ReLU where slope is changed left of x=0 in above figure and thus causing a leak and extending the range of ReLU.
Leaky ReLU and Parametric ReLU
With Leaky ReLU there is a small negative slope, so instead of not firing at all for large gradients, our neurons do output some value and that makes our layer much more optimized too.
4. PReLU (Parametric ReLU) Function:
In Parametric ReLU as seen from the figure above, instead of using a fixed slope like 0.01 used in Leaky ReLU, a parameter ‘a’ is made that will change depending on the model, for x < 0
Using weights and biases, we tune the parameter that is learned by employing backpropagation across multiple layers .
for a ≤ 1
Therefore as PReLU relates to the maximum value, we use it in something called “maxout” networks too.
5. ELU (Exponential LU) Function:
Exponential Linear Units are are used to speed up the deep learning process, this is done by making the mean activations closer to Zero, here an alpha constant is used which must be a positive number.
ELU have been shown to produce more accurate results than ReLU and also converge faster. ELU and ReLU are same for positive inputs, but for negative inputs ELU smoothes (to -alpha) slowly whereas
6. Softmax Function:
Softmax is a very interesting activation function because it not only maps our output to a [0,1] range but also maps each output in such a way that the total sum is 1. The output of Softmax is therefore a probability distribution.
The softmax function is often used in the final layer of a neural network-based classifier. Such networks are commonly trained under a log loss (or cross-entropy) regime, giving a non-linear variant of multinomial logistic regression
Mathematically SoftMax is the following function where z is vector of inputs to output layer and j indexes the the output units from 1,2, 3 …. k :
In conclusion, SoftMax is used for multi-classification in logistic regression model (multivariate) whereas Sigmoid is used for binary classification in logistic regression model.